-
, 万一, 胡堃, 郑茂腾. 光学卫星影像摄影测量处理理论与方法 科学出版社, ISBN: 978-7-03-072801-2, 438P, 2022.08.
-
李彦胜, , 陈瑞贤, 马佳义. 高分辨率遥感影像场景智能理解 科学出版社, ISBN: 978-7-03-071437-4, 120P, 2022.02.
-
. 基于序列图像的视觉检测理论与方法 武汉大学出版社, ISBN: 978-7-307-06654-0, 148P, 2008.12.
- All
- All
- English Journal
- Chinese Journal
-
Dongdong Yue, Xinyi Liu, Yi Wan, . (2025) NeRFOrtho: Orthographic Projection Images Generation based on Neural Radiance Fields. In: International Journal of Applied Earth Observation and Geoinformation, 136(178).

Abstract: The application value of orthographic projection images is substantial, especially in the field of remote sensing for True Digital Orthophoto Map (TDOM) generation. Existing methods for orthographic projection image generation primarily involve geometric correction or explicit projection of photogrammetric mesh models. However, the former suffers from projection differences and stitching lines, while the latter is plagued by poor model quality and high costs. This paper presents NeRFOrtho, a new method for generating orthographic projection images from neural radiance fields at arbitrary angles. By constructing Neural Radiance Fields from multi-view images with known viewpoints and positions, the projection method is altered to render orthographic projection images on a plane where projection rays are parallel to each other. In comparison to existing orthographic projection image generation methods, this approach produces orthographic projection images devoid of projection differences and distortions, while offering superior texture details and higher precision. We also show the applicative potential of the method when rendering TDOM and the texture of building façade. [full text] [link]
-
, Peihao Wu, Yongxiang Yao, Wenfei Zhang, Yansheng Li. (2025) Multimodal Remote Sensing Image Robust Matching Based on Second-Order Tensor Orientation Feature Transformation. In: IEEE Transactions on Geoscience and Remote Sensing, 63.
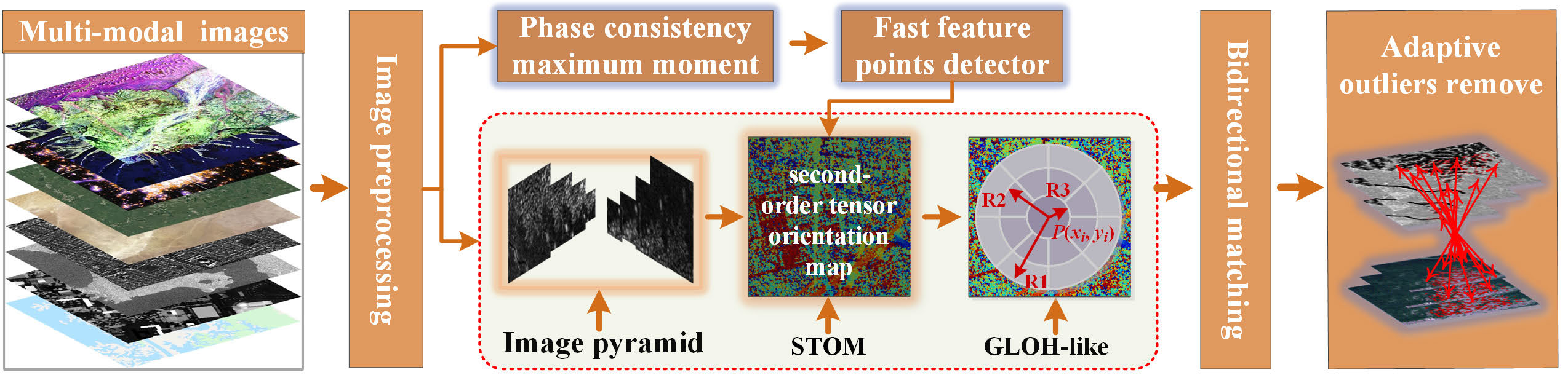
Abstract: Nonrigid deformation (NRD) and image noise in multimodal remote sensing images (MRSI) lead to abrupt changes in feature directions, resulting in sensitivity to rotational variation, sparse correct matches, and high false match rates. In order to address these challenges, this article proposes a second-order tensor orientation feature transformation (SOFT) method to improve the rotational invariance of MRSI matching and increase the number of correct matches (NCMs). The SOFT method has two main contributions: 1) a novel second-order tensor orientation descriptor is constructed by generating a tensor orientation feature map using a designed second-order tensor function, which is then combined with a gradient location and orientation histogram (GLOH)-like descriptor framework to achieve robust rotational invariance in multimodal image matching and 2) an error-removal global-local iterative optimization (EGIO) is introduced, employing a skewness of mixed pixel intensity (SMPI) function to automatically select matching seed points, followed by an iterative partition optimization strategy for refining corresponding points. Experiments on 744 groups of typical MRSIs demonstrate that the SOFT method significantly outperforms nine state-of-the-art methods, achieving an average 97% improvement in the NCMs, an average 25.51% improvement in the rate of correct matches (RCMs), and an average reduction in RMSE of 2.69 pixels. The proposed SOFT method, thus, offers robust MRSI matching with strong rotational invariance and precise identification of corresponding points, proving its effectiveness for complex remote sensing scenarios. Access to experiment-related data and codes will be provided at https://skyearth.org/research/. [full text] [link]
-
Bin Zhang, , Chengdu Cao, Yi Wan, Yongxiang Yao, Liang Fei. (2025) SeConDA: Self-Training Consistency Guided Domain Adaptation for Cross-Domain Remote Sensing Image Semantic Segmentation. In: The photogrammetric record, 40(189).
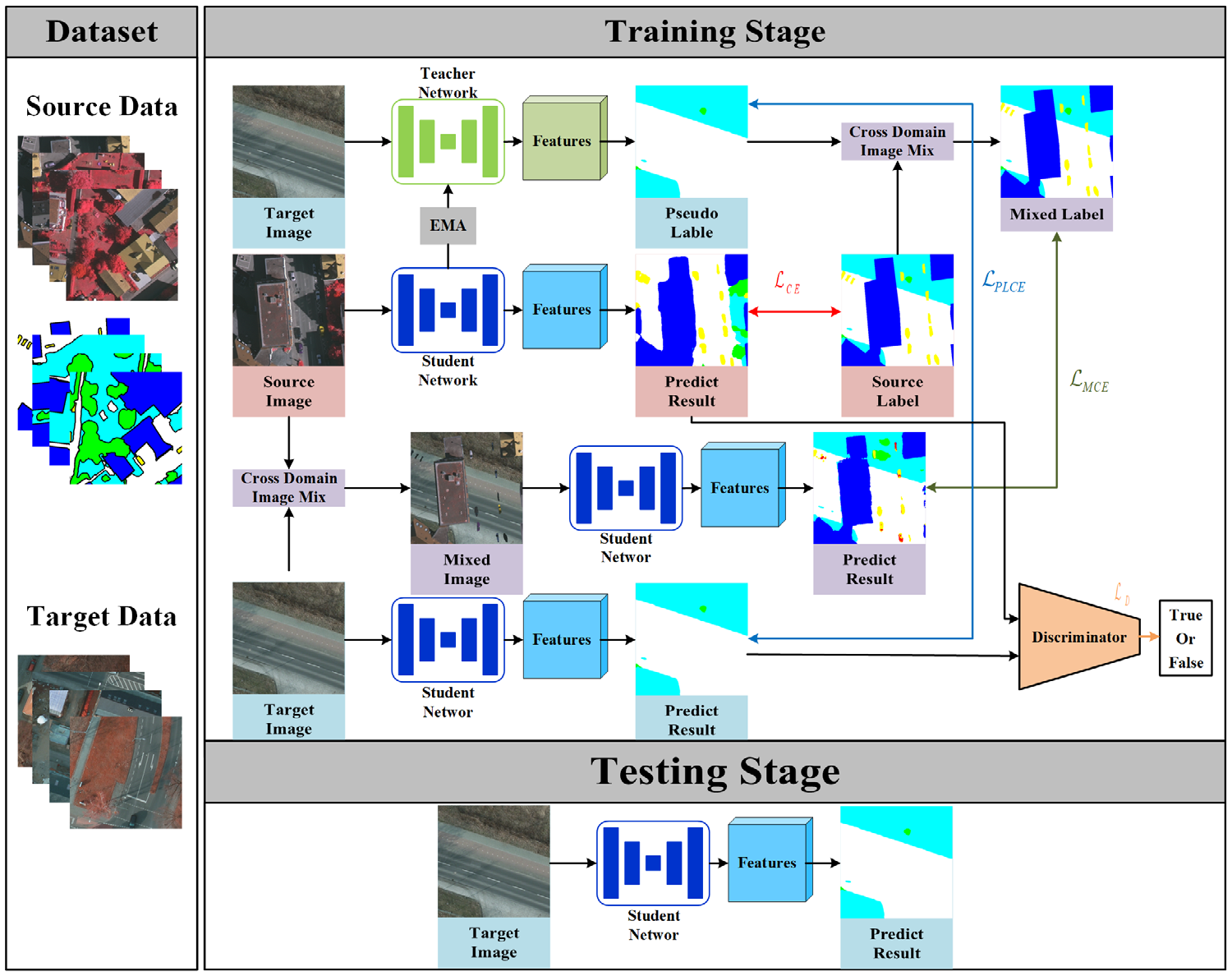
Abstract: Well-trained remote sensing (RS) deep learning models often encounter a considerable decline in performance when applied to images that differ from the training data. This decline can be attributed to variations in imaging sensors, geographic location, imaging time, and radiation levels during image acquisition. Consequently, the widespread application of these models has been greatly impeded. An envisioned resolution to confront this challenge encompasses formulating a cross-domain RS image semantic segmentation network integrated with self-training consistency. This approach involves the generation of high-quality pseudo-labels for images in the target domain, which are then used to guide the training of the network. To enhance the model's ability to learn the data distributions of both the source and target domains, highly perturbed mixed samples are created by blending images from these domains. Additionally, adversarial training is incorporated to reduce the entropy of the model's predicted results, thereby mitigating the influence of noise present in the pseudo-labels. As a result, this approach effectively extracts domain-invariant features and minimizes the disparities between the distributions of the different domains. By employing the ISPRS and LoveDA datasets in a series of experiments conducted across varied scenarios, our empirical investigations evince the capacity of the proposed methodology to generalize the model to target domain data, which is achieved through the mitigation of disparities between domain distributions. It effectively alleviates the domain shift issues caused by differences in imaging locations and band combinations in RS image data and achieves state-of-the-art results and validates its effectiveness. [full text] [link]
-
Yansheng Li, Yuning Wu, Gong Cheng, Chao Tao, Bo Dang, Yu Wang, Jiahao Zhang, Chuge Zhang, Yiting Liu, Xu Tang, Jiayi Ma, . (2025) MEET: A Million-Scale Dataset for Fine-Grained Geospatial Scene Classification With Zoom-Free Remote Sensing Imagery. In: IEEE/CAA Journal of Automatica Sinica, 12(5).

Abstract: Accurate fine-grained geospatial scene classification using remote sensing imagery is essential for a wide range of applications. However, existing approaches often rely on manually zooming remote sensing images at different scales to create typical scene samples. This approach fails to adequately support the fixed-resolution image interpretation requirements in real-world scenarios. To address this limitation, we introduce the million-scale fine-grained geospatial scene classification dataset (MEET), which contains over 1.03 million zoom-free remote sensing scene samples, manually annotated into 80 fine-grained categories. In MEET, each scene sample follows a scene-in-scene layout, where the central scene serves as the reference, and auxiliary scenes provide crucial spatial context for fine-grained classification. Moreover, to tackle the emerging challenge of scene-in-scene classification, we present the context-aware transformer (CAT), a model specifically designed for this task, which adaptively fuses spatial context to accurately classify the scene samples. CAT adaptively fuses spatial context to accurately classify the scene samples by learning attentional features that capture the relationships between the center and auxiliary scenes. Based on MEET, we establish a comprehensive benchmark for fine-grained geospatial scene classification, evaluating CAT against 11 competitive baselines. The results demonstrate that CAT significantly outperforms these baselines, achieving a 1.88% higher balanced accuracy (BA) with the Swin-Large backbone, and a notable 7.87% improvement with the Swin-Huge backbone. Further experiments validate the effectiveness of each module in CAT and show the practical applicability of CAT in the urban functional zone mapping. The source code and dataset will be publicly available at https://jerrywyn.github.io/project/MEET.html. [full text] [link]
-
Haiqing He, Shixun Yu, , Yufeng Zhu, Ting Chen, Fuyang Zhou. (2025) PI-ADFM: Enhancing Multi-Modal Remote Sensing Image Matching through Phase-Integrated Aggregated Deep Features. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing.
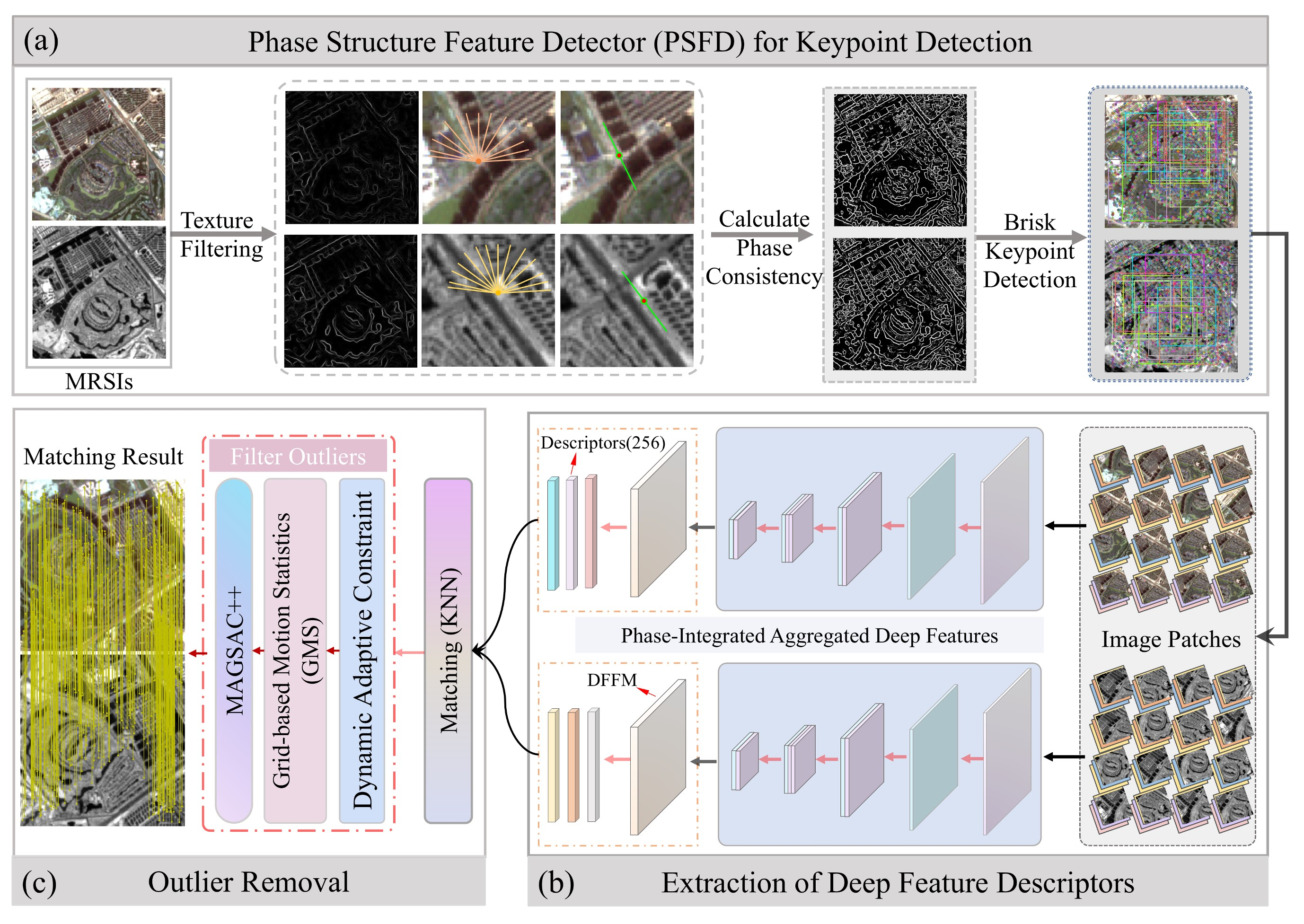
Abstract: Geometric distortions and significant nonlinear radiometric differences in multi-modal remote sensing images (MRSIs) introduce substantial noise in feature extraction. Single-branch convolutional neural networks fail to capture global image features and integrate local and global information effectively, yielding deep descriptors with low discriminability and limited robustness. Moreover, the lack of comprehensive training data further limits the network's performance, which pose a formidable challenge to existing matching methods in securing adequate and evenly distributed corresponding points. This paper proposes a novel method called Phase-Integrated Aggregated Deep Feature Matching (PI-ADFM), designed to address these challenges. Initially, a phase structure feature detector is introduced, which amalgamates the structural attributes and phase information of images to distill keypoints that are highly repeatable and exhibit minimal redundancy. Subsequently, an attention-based multi-level feature interaction and aggregation module (MFIAM) is crafted to encapsulate a comprehensive representation of both local and global features of keypoints. This is followed by the integration of a dense feature fusion module (DFFM) designed to sift through and amalgamate key features, thereby capturing highly discriminative deep semantic features that serve as descriptors for similarity measures. Finally, a multi-level outlier removal strategy is proposed to effectively reduce mismatches. Experimental results substantiate that, in juxtaposition with state-of-the-art methods, the PI-ADFM method has significantly augmented the count of matches for optical-infrared and optical SAR images by a factor of at least 1.7 and 3.7, respectively, while concurrently enhancing the accuracy by a minimum of 10% and 6%, respectively. These enhancements markedly bolster the robustness and reliability of MRSI matching endeavors. The source code of this study is freely available at https://github.com/hyhqing/PI-ADFM [full text] [link]
-
Xuejun Huang, Xinyi Liu, Yi Wan, Zhi Zheng, Bin Zhang, Yameng Wang, Haoyu Guo, . (2025) MVSR3D: An End-to-End Framework for Semantic 3-D Reconstruction Using Multiview Satellite Imagery. In: IEEE Transactions on Geoscience and Remote Sensing, 63.
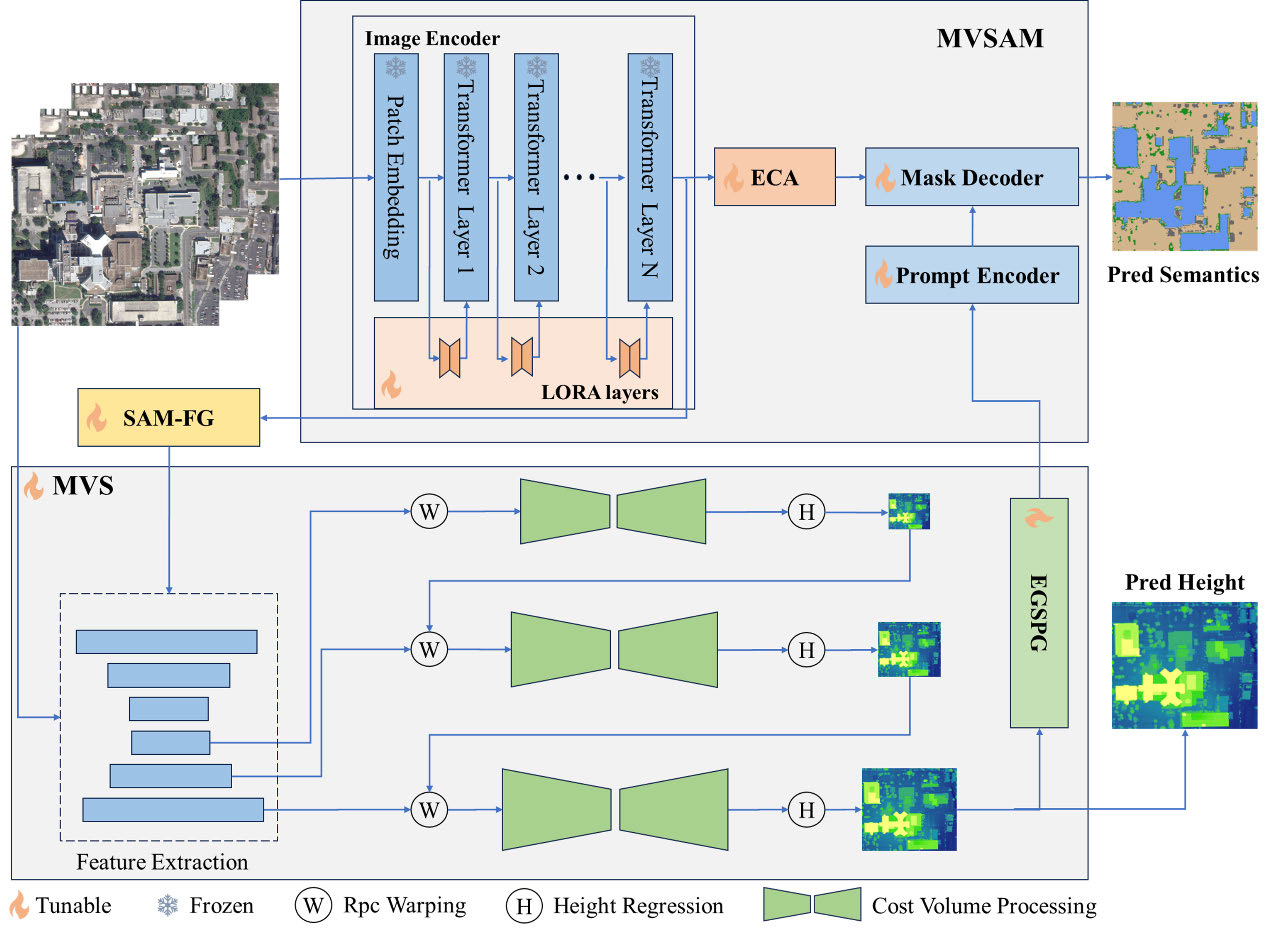
Abstract: Semantic 3-D reconstruction from multiview images is essential for applications such as 3-D city modeling and robot navigation. However, existing methods treat semantic segmentation (SS) and height estimation (HE) as separate tasks, leading to suboptimal reconstruction results. To bridge this gap, we introduce MVSR3D, the first end-to-end framework for semantic 3-D reconstruction using multiview satellite images. MVSR3D employs a dual-stream architecture, consisting of the segmentation branch (MVSAM) based on segment anything model (SAM) and the HE branch based on multiview stereo (MVS). To enhance multiview feature fusion, we propose the epipolar cross attention (ECA) module in the MVSAM branch, which integrates image embeddings primarily along epipolar line to exploit complementary multiview information. Unlike conventional multitask learning approaches, we design dedicated interaction modules—the SAM feature-guided (SAM-FG) module and the elevation-guided sparse prompts generator (EGSPG)—to facilitate multitask interaction and feature fusion. Extensive evaluations on the DFC19 and SpaceNet4 datasets demonstrate that MVSR3D significantly outperforms the state-of-the-art multiview multitask learning (MV-MTL) method, improving the mIoU3 metric at a 2.5-m threshold by 37.09%–45.11%. [full text] [link]
-
Xuejun Huang, Yi Wan, , Xinyi Liu, Bin Zhang, Yameng Wang, Haoyu Guo, Yingying Pei. (2025) PSDA: Pyramid Spatial Deformable Aggregation for Building Segmentation in Multiview Remote Sensing Images. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 18.
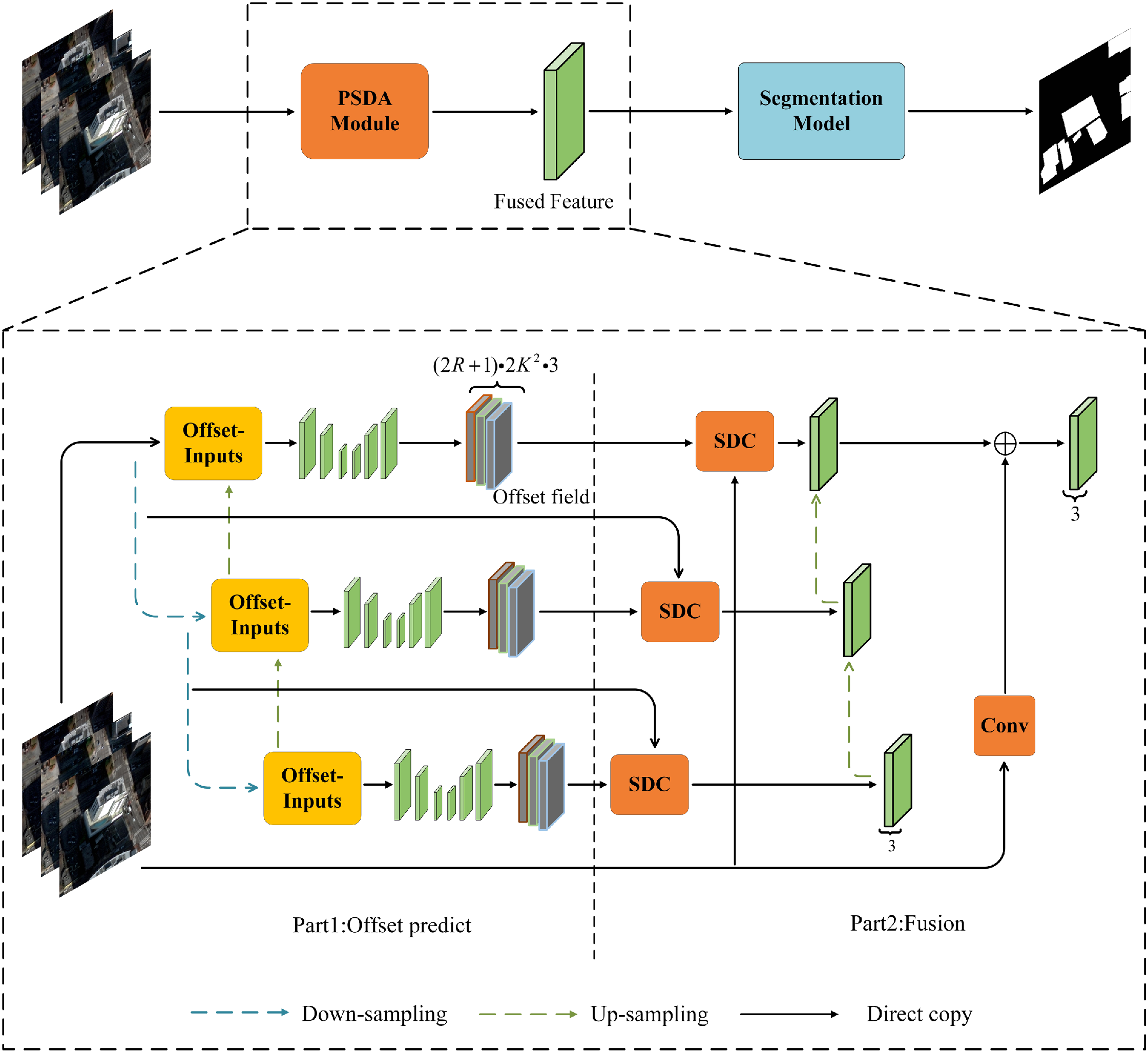
Abstract: As increasingly more deep learning models are designed and implemented, the performance of single-view image semantic segmentation is approaching its upper limit. With the increasing availability of multiview satellite images, using multiview information is gaining attention as it can address occlusion problems in single-view images and achieve cross-validation to reduce inappropriate segmentation. However, current multiview semantic segmentation methods often rely on multiview voting or require complex preprocessing steps, which may not fully leverage the advantages of multiview images. We analyzed the complementarity and constraints of multiview information and introduced the pyramid spatial deformable aggregation (PSDA) module, a plug-and-play module designed to enhance multiview feature fusion. PSDA is the core component of our early multiview segmentation framework, which facilitates early-stage information fusion by directly extracting features from multiview images, avoiding the complex and time-consuming production of true orthoimages. In this article, we first show how we created the multiview segmentation dataset (MVSeg dataset) using orthoimages generated from different-view images. Then, the results are shown to prove that our method outperformed the corresponding single-view segmentation method, namely by increasing the intersection over union (IoU) metric by approximately 1.23% –3.68% on both datasets. Due to the fusion of multiview images at an early stage, the computational complexity is 0.29–0.74 times that of the state-of-the-art method, and the IoU metric improved by approximately 2.20% –7.52% on both datasets. [full text] [link]
-
Haiqing He, Fuyang Zhou, , Ting Chen, Yan Wei. (2025) GACNet: A Geometric and Attribute Co-Evolutionary Network for Citrus Tree Height Extraction From UAV Photogrammetry-Derived Data. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 18.
Abstract: The undulating terrain and complex backgrounds of citrus plantations introduce nonlinear variations that significantly impede the high-precision estimation of citrus tree heights from remote sensing data. To overcome these obstacles, we introduce a novel geometric and attribute co-evolutionary network, tailored for extracting citrus tree heights using unmanned aerial vehicle photogrammetry-derived data. Our approach integrates a multisource feature interaction module with a multisource feature aggregation module, fostering the co-evolution of deep feature responses across various datasets. Notably, this includes a sophisticated triple-feature interaction mechanism that considers position, channel, and spatial correlation to enhance the aggregation of geometric features. In addition, we employ a multilevel feature aggregation decoder leveraging cross-attention, ensuring attribute context consistency and facilitating efficient tree height extraction. Quantitative analysis across datasets reveals our method's superior performance, with a 2% –7% increase in mean intersection over union for canopy segmentation and a robust correlation of 0.77 between estimated and reference tree heights, accompanied by an MAE of 0.25 m and an RMSE of 0.38 m. Comparative experiments indicate that our method outperforms current state-of-the-art networks, showing resilience to terrain undulations and offering reliable cross-region and cross-scale tree height estimation capabilities. [full text] [link]
-
Run Shao, Cheng Yang, Qiujun Li, Linrui Xu, Xiang Yang, Xian Li, Mengyao Li, Qing Zhu, , Yansheng Li, Yu Liu, Yong Tang, Dapeng Liu, Shizhong Yang, Haifeng Li. (2025) AllSpark: A Multimodal Spatiotemporal General Intelligence Model With Ten Modalities via Language as a Reference Framework. In: IEEE Transactions on Geoscience and Remote Sensing, 63.
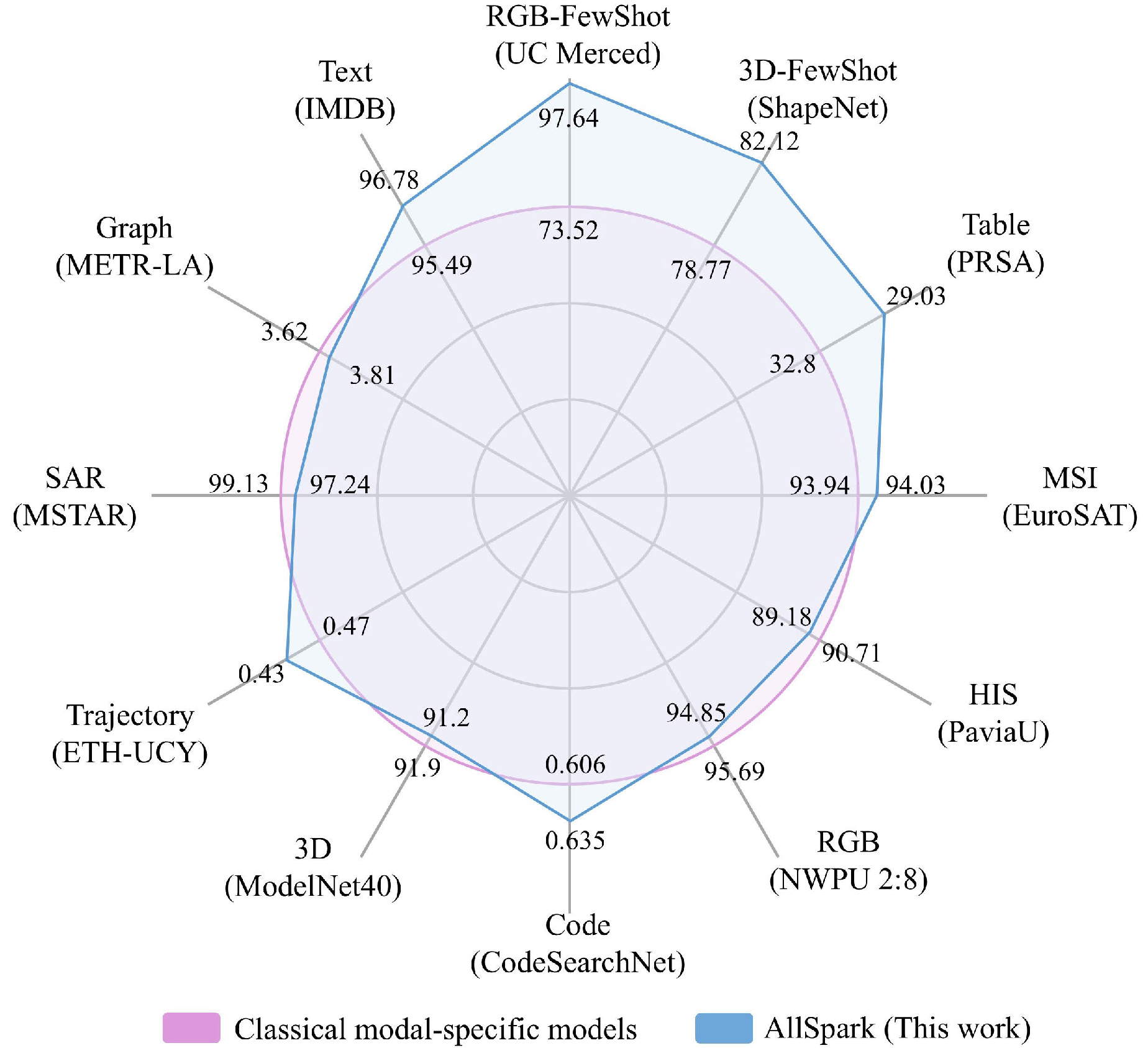
Abstract: RGB, multispectral, point, and other spatiotemporal modal data fundamentally represent different observational approaches for the same geographic object. Therefore, leveraging multimodal data is an inherent requirement for comprehending geographic objects. However, due to the high heterogeneity in structure and semantics among various spatiotemporal modalities, the joint interpretation of multimodal spatiotemporal data has long been an extremely challenging problem. The primary challenge resides in striking a trade-off between the cohesion and autonomy of diverse modalities. This trade-off becomes progressively nonlinear as the number of modalities expands. Inspired by the human cognitive system and linguistic philosophy, where perceptual signals from the five senses converge into language, we introduce the language as reference framework (LaRF), a fundamental principle for constructing a multimodal unified model. Building upon this, we propose AllSpark, a multimodal spatiotemporal general artificial intelligence model. Our model integrates ten different modalities into a unified framework, including 1-D (language, code, and table), 2-D (RGB, synthetic aperture radar (SAR), multispectral, hyperspectral, graph, and trajectory), and 3-D (point cloud) modalities. To achieve modal cohesion, AllSpark introduces a modal bridge and multimodal large language model (LLM) to map diverse modal features into the language feature space. To maintain modality autonomy, AllSpark uses modality-specific encoders to extract the tokens of various spatiotemporal modalities. Finally, observing a gap between the model’s interpretability and downstream tasks, we designed modality-specific prompts and task heads, enhancing the model’s generalization capability across specific tasks. Experiments indicate that the incorporation of language enables AllSpark to excel in few-shot classification tasks for RGB and point cloud modalities without additional training, surpassing baseline performance by up to 41.82%. Additionally, AllSpark, despite lacking expert knowledge in most spatiotemporal modalities and utilizing a unified structure, demonstrates strong adaptability across ten modalities. LaRF and AllSpark contribute to the shift in the research paradigm in spatiotemporal intelligence, transitioning from a modality-specific and task-specific paradigm to a general paradigm. The source code is available at https://github.com/GeoX-Lab/AllSpark. [full text] [link]
-
, Pengcheng Shi, Jiayuan Li. (2024) 3D LiDAR SLAM: A survey. In: The Photogrammetric Record 39(186), 457-517.
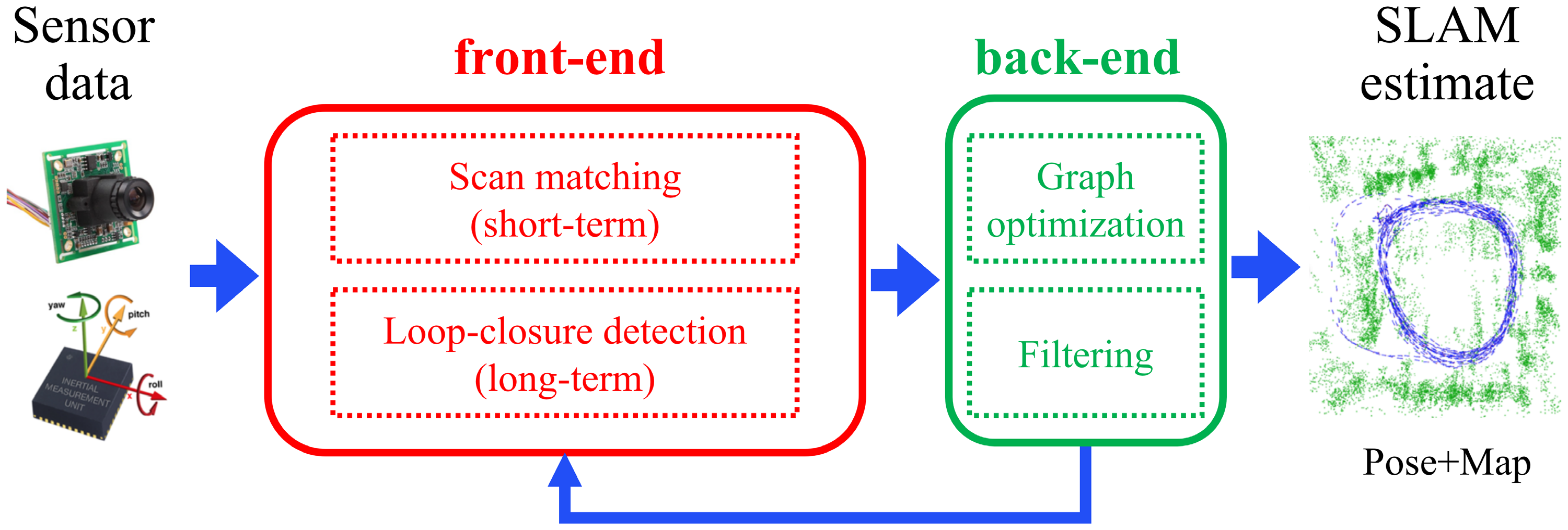
Abstract: Simultaneous localization and mapping (SLAM) is a very challenging yet fundamental problem in the field of robotics and photogrammetry, and it is also a prerequisite for intelligent perception of unmanned systems. In recent years, 3D LiDAR SLAM technology has made remarkable progress. However, to the best of our knowledge, almost all existing surveys focus on visual SLAM methods. To bridge the gap, this paper provides a comprehensive review that summarizes the scientific connotation, key difficulties, research status, and future trends of 3D LiDAR SLAM, aiming to give readers a better understanding of LiDAR SLAM technology, thereby inspiring future research. Specifically, it summarizes the contents and characteristics of the main steps of LiDAR SLAM, introduces the key difficulties it faces, and gives the relationship with existing reviews; it provides an overview of current research hotspots, including LiDAR‐only methods and multi‐sensor fusion methods, and gives milestone algorithms and open‐source tools in each category; it summarizes common datasets, evaluation metrics and representative commercial SLAM solutions, and provides the evaluation results of mainstream methods on public datasets; it looks forward to the development trend of LiDAR SLAM, and considers the preliminary ideas of multi‐modal SLAM, event SLAM, and quantum SLAM. [full text] [link]
-
Yansheng Li, Linlin Wang, Tingzhu Wang, Xue Yang, Luo Junwei, Qi Wang, Youming Deng, Wenbin Wang, Xian Sun, Haifeng Li, Bo Dang, , Yi Yu, Junchi Yan. (2024) STAR: A First-Ever Dataset and A Large-Scale Benchmark for Scene Graph Generation in Large-Size Satellite Imagery. In: IEEE Transactions on Pattern Analysis and Machine Intelligence.
Abstract: Scene graph generation (SGG) in satellite imagery (SAI) benefits promoting understanding of geospatial scenarios from perception to cognition. In SAI, objects exhibit great variations in scales and aspect ratios, and there exist rich relationships between objects (even between spatially disjoint objects), which makes it attractive to holistically conduct SGG in large-size very-high-resolution (VHR) SAI. However, there lack such SGG datasets. Due to the complexity of large-size SAI, mining triplets
-
Zhi Zheng, Yi Wan, , Zhonghua Hu, Dong Wei, Yongxiang Yao, Chenming Zhu, Kun Yang, Rang Xiao. (2024) Digital surface model generation from high‐resolution satellite stereos based on hybrid feature fusion network. In: The Photogrammetric Record.
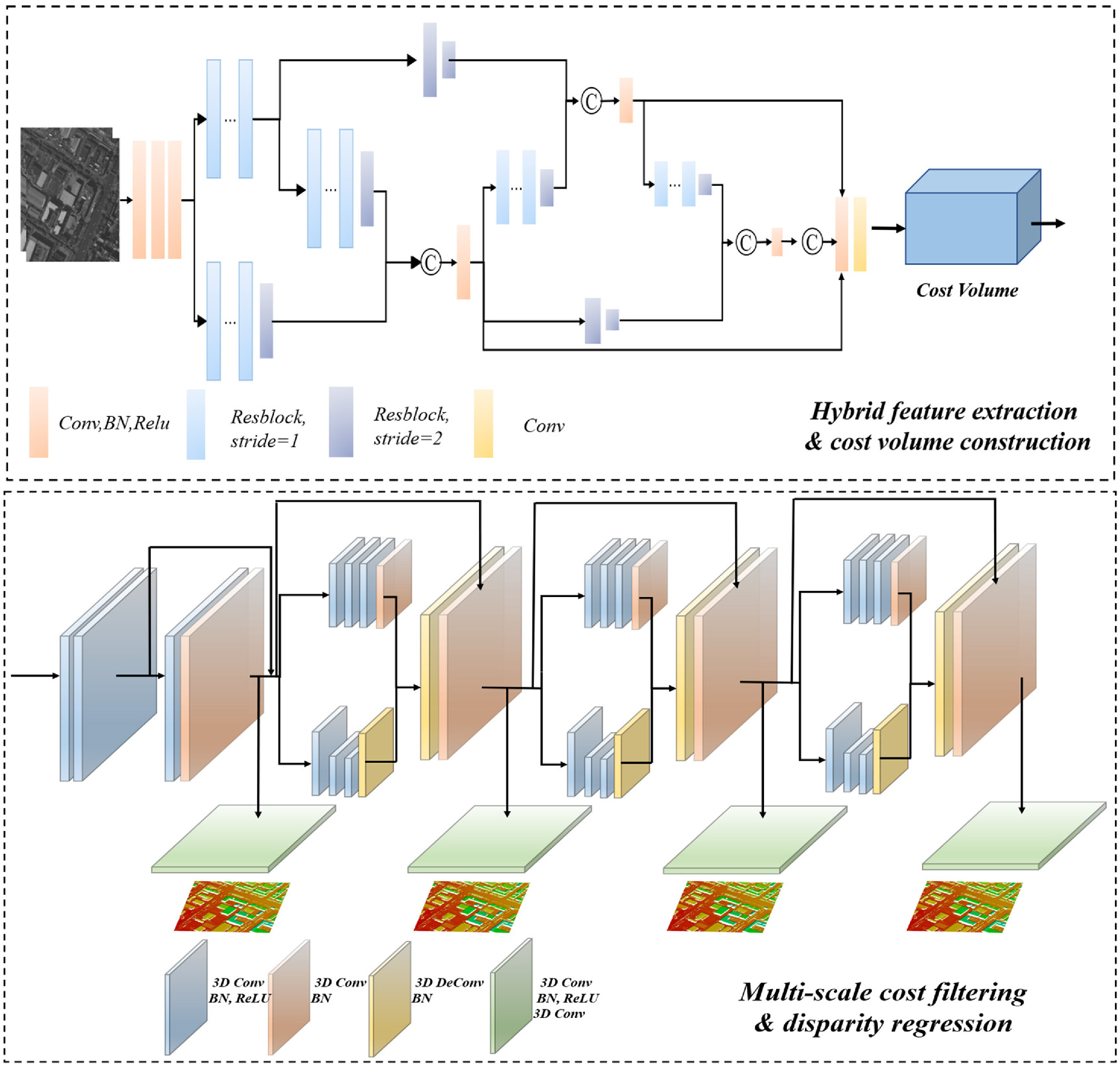
Abstract: Recent studies have demonstrated that deep learning-based stereo matching methods (DLSMs) can far exceed conventional ones on most benchmark datasets by both improving visual performance and decreasing the mismatching rate. However, applying DLSMs on high-resolution satellite stereos with broad image coverage and wide terrain variety is still challenging. First, the broad coverage of satellite stereos brings a wide disparity range, while DLSMs are limited to a narrow disparity range in most cases, resulting in incorrect disparity estimation in areas with contradictory disparity ranges. Second, high-resolution satellite stereos always comprise various terrain types, which is more complicated than carefully prepared datasets. Thus, the performance of DLSMs on satellite stereos is unstable, especially for intractable regions such as texture-less and occluded regions. Third, generating DSMs requires occlusion-aware disparity maps, while traditional occlusion detection methods are not always applicable for DLSMs with continuous disparity. To tackle these problems, this paper proposes a novel DLSM-based DSM generation workflow. The workflow comprises three steps: pre-processing, disparity estimation and post-processing. The pre-processing step introduces low-resolution terrain to shift unmatched disparity ranges into a fixed scope and crops satellite stereos to regular patches. The disparity estimation step proposes a hybrid feature fusion network (HF2Net) to improve the matching performance. In detail, HF2Net designs a cross-scale feature extractor (CSF) and a multi-scale cost filter. The feature extractor differentiates structural-context features in complex scenes and thus enhances HF2Net's robustness to satellite stereos, especially on intractable regions. The cost filter filters out most matching errors to ensure accurate disparity estimation. The post-processing step generates initial DSM patches with estimated disparity maps and then refines them for the final large-scale DSMs. Primary experiments on the public US3D dataset showed better accuracy than state-of-the-art methods, indicating HF2Net's superiority. We then created a self-made Gaofen-7 dataset to train HF2Net and conducted DSM generation experiments on two Gaofen-7 stereos to further demonstrate the effectiveness and practical capability of the proposed workflow. [full text] [link]
-
, Wenfei Zhang, Yongxiang Yao, Zhi Zheng, Yi Wan, Mingtao Xiong. (2024) Robust registration of multi-modal remote sensing images based on multi-dimensional oriented self-similarity features. In: International Journal of Applied Earth Observation and Geoinformation 127.
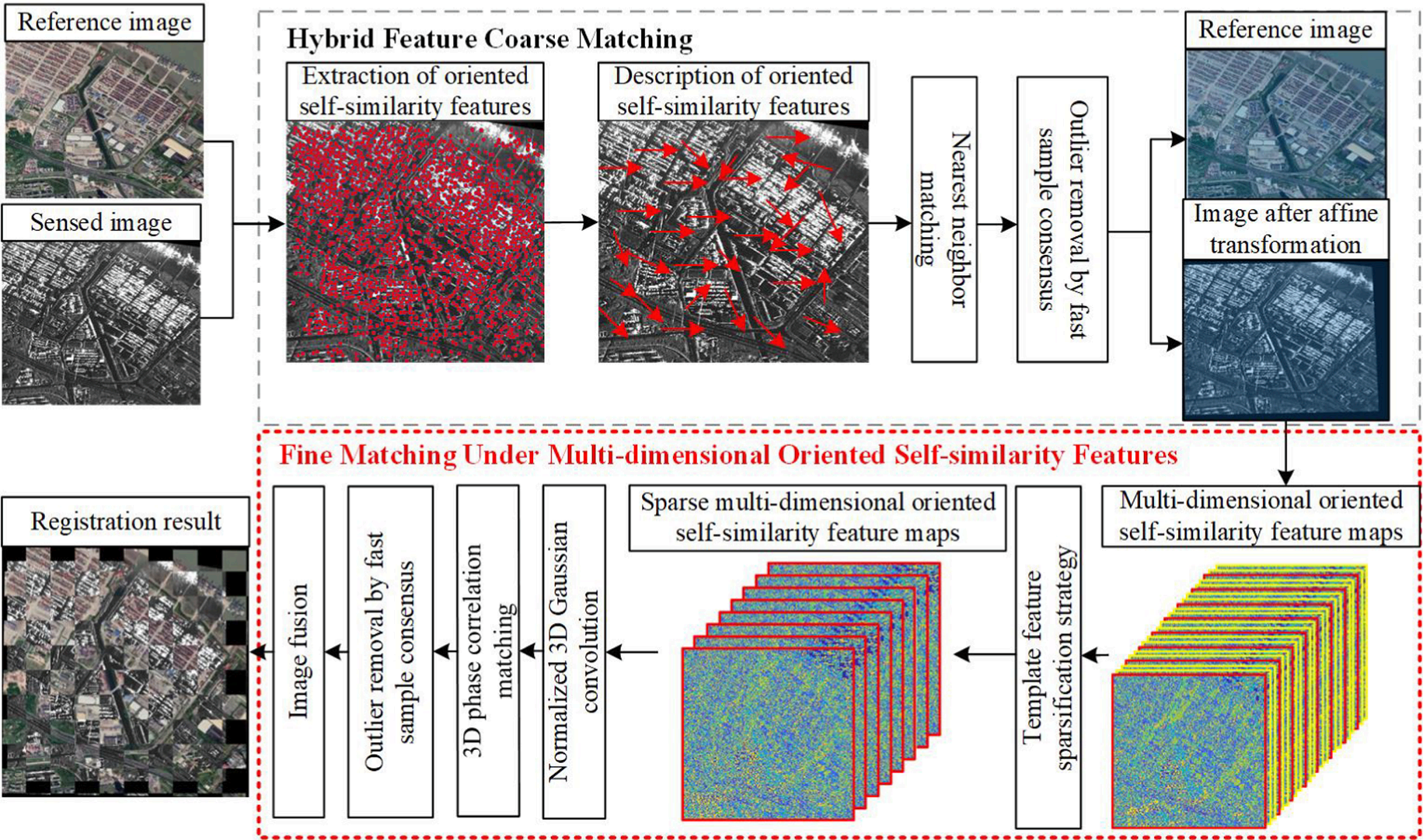
Abstract: Registration of multi-modal remote sensing images (MRSI) is crucial for unlocking the full potential of heterogeneous remote sensing imagery. However, achieving accurate registration among MRSI is challenging due to the trade-off between geometric invariance and matching accuracy, caused by differences in signal-to-noise ratio and nonlinear radiometric distortion (NRD) arising from varying imaging mechanisms. To tackle the challenge, this paper proposes a lightweight and hybrid feature-guided registration algorithm for MRSI called the hybrid registration algorithm based on multi-dimensional oriented self-similarity features (MOSS). MOSS leverages the advantages of multi-dimensional oriented self-similarity features to progressively enhance registration performance. In the hybrid feature coarse matching stage, oriented self-similarity features are extracted from MRSI, and their directional information is utilized for feature description to estimate the initial affine transformation. The fine matching under multi-dimensional oriented self-similarity features stage takes the outputs of the coarse matching stage to perform a template-like matching process. To evaluate the performance of MOSS, comprehensive experiments are conducted using six different combinations of MRSI, and seven state-of-the-art registration algorithms are selected for comparison. The experimental results demonstrate that MOSS outperforms the compared methods, with the number of correct matches being at least about 1.6 times higher than the comparison methods. Moreover, MOSS exhibits the lowest root mean square error across all experiments, with an average RMSE of 1.86 pixels, achieving an RMSE within 2 pixels. This highlights its effectiveness in achieving precise alignment and robust registration of MRSI. [full text] [link]
-
Haoyu Guo, Dong Wei, , Yi Wan, Zhi Zheng, Yongxiang Yao, Xinyi Liu, Zhuofan Li. (2024) The One-Point-One-Line geometry for robust and efficient line segment correspondence. In: ISPRS Journal of Photogrammetry and Remote Sensing 210, 80-96.
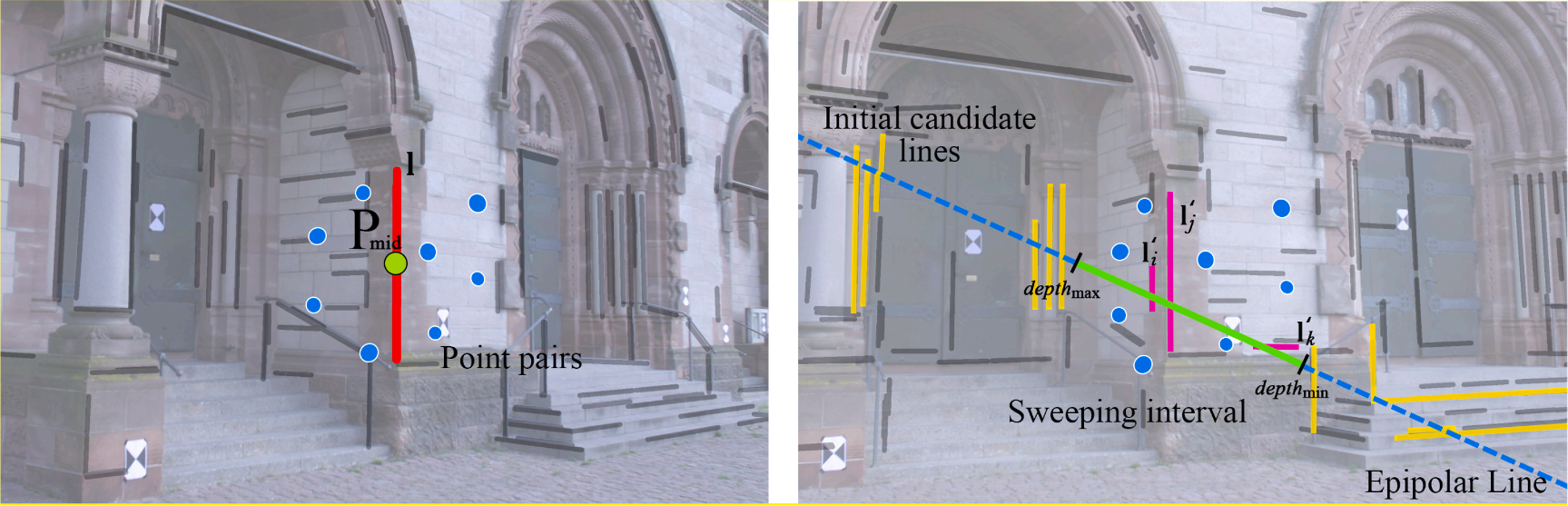
Abstract: Three-dimensional (3D) lines are common elements in artificial scenes and serve as basic, yet essential features for structural 3D reconstruction. The crucial step of 3D line reconstruction, namely two-view line segment matching, still faces challenges in terms of both accuracy and efficiency improvements. Therefore, robust and efficient constraints are needed to establish valid line candidates. This paper introduces a novel geometry constraint called “one-point-one-line geometry” (OPOL) to enhance the precision of line matching and reduce computational complexity. OPOL offers two remarkable advantages: (1) It takes point orientations as the constraint, which is not only invariant to projective transformations, but also alleviates computational requirements. (2) It needs only one point match to construct the geometry constraint, thus both the grouping and validation are greatly reduced. Additionally, we incorporate the line sweep strategy into OPOL, leveraging depth and space constraints derived from existing 3D points to further enhance efficiency. Extensive experiments conducted on large-coverage and high-resolution images (as large as 10336 × 7788 pixels) demonstrated that OPOL matched lines within a second for an image pair. Both quantitative and qualitative results also demonstrated the superior accuracy and efficiency performance of OPOL. We integrated OPOL into multiple view line reconstruction frameworks, and the promising experimental results reveal the performance of OPOL for robust line reconstruction. [full text] [link]
-
Weiwei Fan, Xinyi Liu, , Dongdong Yue, Senyuan Wang, Jiachen Zhong. (2024) Airborne LiDAR Point Cloud Filtering Algorithm Based on Supervoxel Ground Saliency. In: ISPRS Annals of the Photogrammetry Remote Sensing and Spatial Information Sciences 2024, 73-79.

Abstract: Objectives Localization is an important module of the light detection and ranging (LiDAR) simultaneous localization and mapping (SLAM) system, which provides basic information for perception, control, and planning, further assisting robots to accomplish higher-level tasks. However, LiDAR localization methods still face some problems: The localization accuracy and efficiency cannot meet the requirements of the robot products. In some textureless or large open environments, the lack of features easily leads to dangerous robot kidnappings. Consequently, aiming at the localization problems of mobile robots in large indoor environments, a global localization method based on cylindrical features is proposed.Methods First, an offline parameterized map is designed, which consists of some map cylinders and a raster map. Because the point cloud map contains a large number of 3D points and complete cylinders, random sample consensus (RANSAC) and geometric models are combined to directly segment the cylindrical points. The raster map is employed to describe the distributions of stable artificial structures. Then, some lightweight binary files are used to offline record the geometric model of cylinders and the feature distribution of the map. Next, based on three unique geometric characteristics of the cylinder (outlier, symmetry, and saliency), a real-time LiDAR point cloud cylinder segmentation method is proposed. Finally, two pose computation strategies are designed. The first is an optimization model based on heuristic search, which searches for the best matching cylinder between the map and real-time point cloud, and calculates the translation and rotation, respectively. The second is an optimization model based on multi-cylinder constraints, which employs both the topological relation (point-to-point and point-to-line constraints) and geometry attributes to find approximately congruent cylinders, then computes optimal pose.Results To verify the feasibility of the proposed method, we use a 16-line LiDAR to collect the experimental data in three real-world indoor environments, i.e., lobby, corridor, and hybrid scenarios. The global localization experiment is compared to a similar wall-based localization method, and the loop closure detection is compared to M2DP, ESF, Scan Context, and the wall-based localization. The experimental results show that the proposed method outperforms the baseline methods. The place recognition and localization performance of the proposed method reach the mainstream method level, with a localization success rate of 90% and an error of 0.073 m. Some data can reach millimeter localization accuracy, and the fastest speed is within 100 ms.Conclusions The proposed method can effectively realize the global localization and place recognition of the robots in typical open indoor environments. It meets the accuracy and efficiency requirements of autonomous driving for global localization in practical applications. It can be applied to solve the problems of position initialization, re-localization, and loop closure detection. [full text] [link]
-
Pengcheng Shi, Jiayuan Li, Xinyi Liu, . (2024) Indoor Cylinders Guided LiDAR Global Localization and Loop Closure Detection. In: Geomatics and Information Science of Wuhan University 49(07), 1088-1099.

Abstract: Objectives Localization is an important module of the light detection and ranging (LiDAR) simultaneous localization and mapping (SLAM) system, which provides basic information for perception, control, and planning, further assisting robots to accomplish higher-level tasks. However, LiDAR localization methods still face some problems: The localization accuracy and efficiency cannot meet the requirements of the robot products. In some textureless or large open environments, the lack of features easily leads to dangerous robot kidnappings. Consequently, aiming at the localization problems of mobile robots in large indoor environments, a global localization method based on cylindrical features is proposed.Methods First, an offline parameterized map is designed, which consists of some map cylinders and a raster map. Because the point cloud map contains a large number of 3D points and complete cylinders, random sample consensus (RANSAC) and geometric models are combined to directly segment the cylindrical points. The raster map is employed to describe the distributions of stable artificial structures. Then, some lightweight binary files are used to offline record the geometric model of cylinders and the feature distribution of the map. Next, based on three unique geometric characteristics of the cylinder (outlier, symmetry, and saliency), a real-time LiDAR point cloud cylinder segmentation method is proposed. Finally, two pose computation strategies are designed. The first is an optimization model based on heuristic search, which searches for the best matching cylinder between the map and real-time point cloud, and calculates the translation and rotation, respectively. The second is an optimization model based on multi-cylinder constraints, which employs both the topological relation (point-to-point and point-to-line constraints) and geometry attributes to find approximately congruent cylinders, then computes optimal pose.Results To verify the feasibility of the proposed method, we use a 16-line LiDAR to collect the experimental data in three real-world indoor environments, i.e., lobby, corridor, and hybrid scenarios. The global localization experiment is compared to a similar wall-based localization method, and the loop closure detection is compared to M2DP, ESF, Scan Context, and the wall-based localization. The experimental results show that the proposed method outperforms the baseline methods. The place recognition and localization performance of the proposed method reach the mainstream method level, with a localization success rate of 90% and an error of 0.073 m. Some data can reach millimeter localization accuracy, and the fastest speed is within 100 ms.Conclusions The proposed method can effectively realize the global localization and place recognition of the robots in typical open indoor environments. It meets the accuracy and efficiency requirements of autonomous driving for global localization in practical applications. It can be applied to solve the problems of position initialization, re-localization, and loop closure detection. [full text] [link]
-
, Pengcheng Shi, Jiayuan Li. (2024) LiDAR-Based Place Recognition For Autonomous Driving: A Survey. In: ACM Computing Surveys 57(04), 1-36.
Abstract: LiDAR has gained popularity in autonomous driving due to advantages like long measurement distance, rich three-dimensional information, and stability in harsh environments. Place Recognition (PR) enables vehicles to identify previously visited locations despite variations in appearance, weather, and viewpoints, even determining their global location within prior maps. This capability is crucial for accurate localization in autonomous driving. Consequently, LiDAR-based Place Recognition (LPR) has emerged as a research hotspot in robotics. However, existing reviews predominantly concentrate on Visual Place Recognition, leaving a gap in systematic reviews on LPR. This article bridges this gap by providing a comprehensive review of LPR methods, thus facilitating and encouraging further research. We commence by exploring the relationship between PR and autonomous driving components. Then, we delve into the problem formulation of LPR, challenges, and relations to previous surveys. Subsequently, we conduct an in-depth review of related research, which offers detailed classifications, strengths and weaknesses, and architectures. Finally, we summarize existing datasets and evaluation metrics and envision promising future directions. This article can serve as a valuable tutorial for newcomers entering the field of place recognition. [full text] [link]
-
, Dongdong Yue, Xinyi Liu, Siyuan Zou, Weiwei Fan, Zihang Liu. (2024) OccFaçade: enabling precise building façade parsing in large urban scenes with occlusion. In: International Journal of Remote Sensing 45(18), 6651-6674.
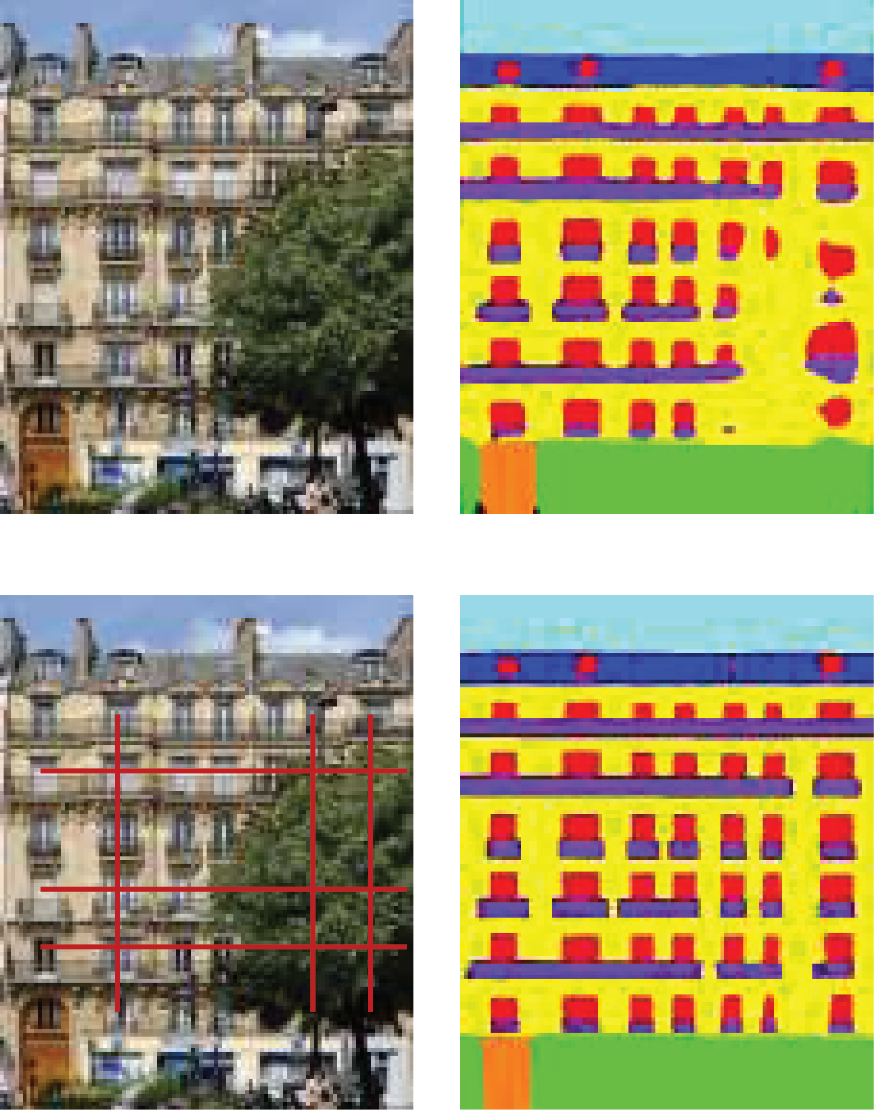
Abstract: Building façade parsing is to recognize the building façade image into different categories of individuals including walls, doors, windows, balconies, etc. However, obstructions such as trees present a significant challenge to conducting façade parsing. In this paper, we designed OccFaçade to achieve high-precision parsing of occluded building façades in large urban scenes. OccFaçade primarily incorporates two modules, Multi-layer Dilated Convolution Module (MD-Module) and Multi-scale Row-Column Convolution Module (MRC-Module), to capture repeated texture in local and row-column directions. This aims to leverage repetitive textures to address occlusion challenges in building façade parsing. Besides, we introduce our building façade dataset MeshFaçade from the Mesh data generated by drone imagery to study the occlusion problem of missing textures. The experimental results demonstrate that OccFaçade achieves state-of-the-art performance with mIOU of 85.01%, 84.09%, 72.95%, and 88.83% on the ENPC2014 dataset, ECP dataset, RueMonge2014 dataset, and our MeshFaçade dataset, respectively. [full text] [link]
-
Zihang Liu, Xinyi Liu, . (2024) Building Damage Assessment from Satellite Images Combining Global-Local Features and Dynamic Error Supervision. In: Geomatics and Information Science of Wuhan University.
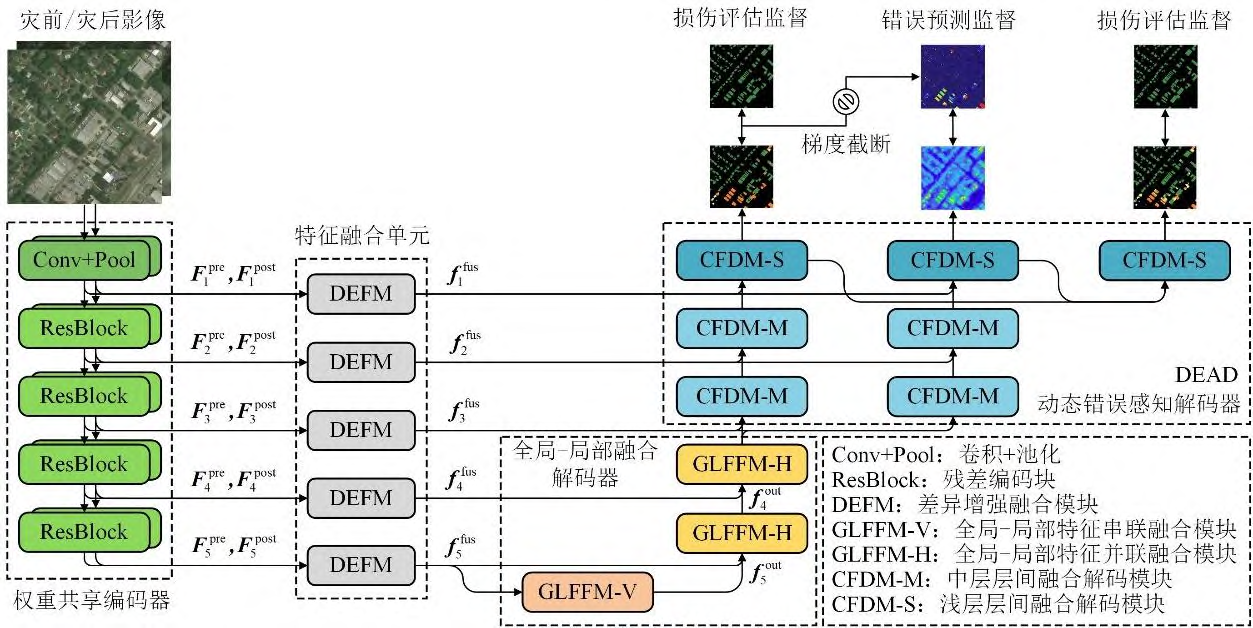
Abstract: After a disaster, it is essential to quickly and accurately assess the extent and severity of the disaster area for subsequent humanitarian relief and reconstruction. Traditional damage assessment methods are constrained by time efficiency, labor cost, and accessibility. In contrast, satellite images can uickly obtain the real situation of a wide range of disaster areas, and gradually become an important data source for building damage assessment. Automated building damage assessment from satellite images relies on deep learning methods, but current deep learning building damage assessment methods for satellite images face challenges such as insufficient modeling of feature differences, inadequate utilization of global-local features, and lack of difficult sample perception ability. Methods: To address these problems, a building damage assessment method based on global-local feature fusion and dynamic error supervision network (GLESNet) is proposed. At the encoding stage, the dual-temporal image features were extracted by a shared weight backbone, and the features were sent to the difference enhancement fusion module (DEFM) to enhance the difference between the features, filter out spurious changes, and obtain the fusion features. At the decoding stage, the fusion features are passed by the vertical and horizontal global-local feature fusion modules (GLFFM) and the dynamic error aware decoder (DEAD), to fuse the global and local features and percept the difficult samples. Results: The proposed GLESNet achieves 86.03% F1-score of building extraction, 75.20% F1-score of damage classification, and 78.45% overall F1-score on xBD, the largest global level high-resolution satellite image dataset for building damage assessment. Conclusions: The quantitative evaluation and visualization results are better than other advanced comparison methods. Ablation study verifies the effectiveness of each module. Transfer experiments and change detection experiments carried out on the IdaBD and LEVIR-CD datasets verify the generalization of the proposed GLESNet to different data and tasks. [full text] [link]
-
Panwang Xia, Yi Wan, Zhi Zheng, , Jiwei Deng. (2024) Enhancing Cross-View Geo-Localization With Domain Alignment and Scene Consistency. In: IEEE Transactions on Circuits and Systems for Video Technology 34(12), 13271-13281.
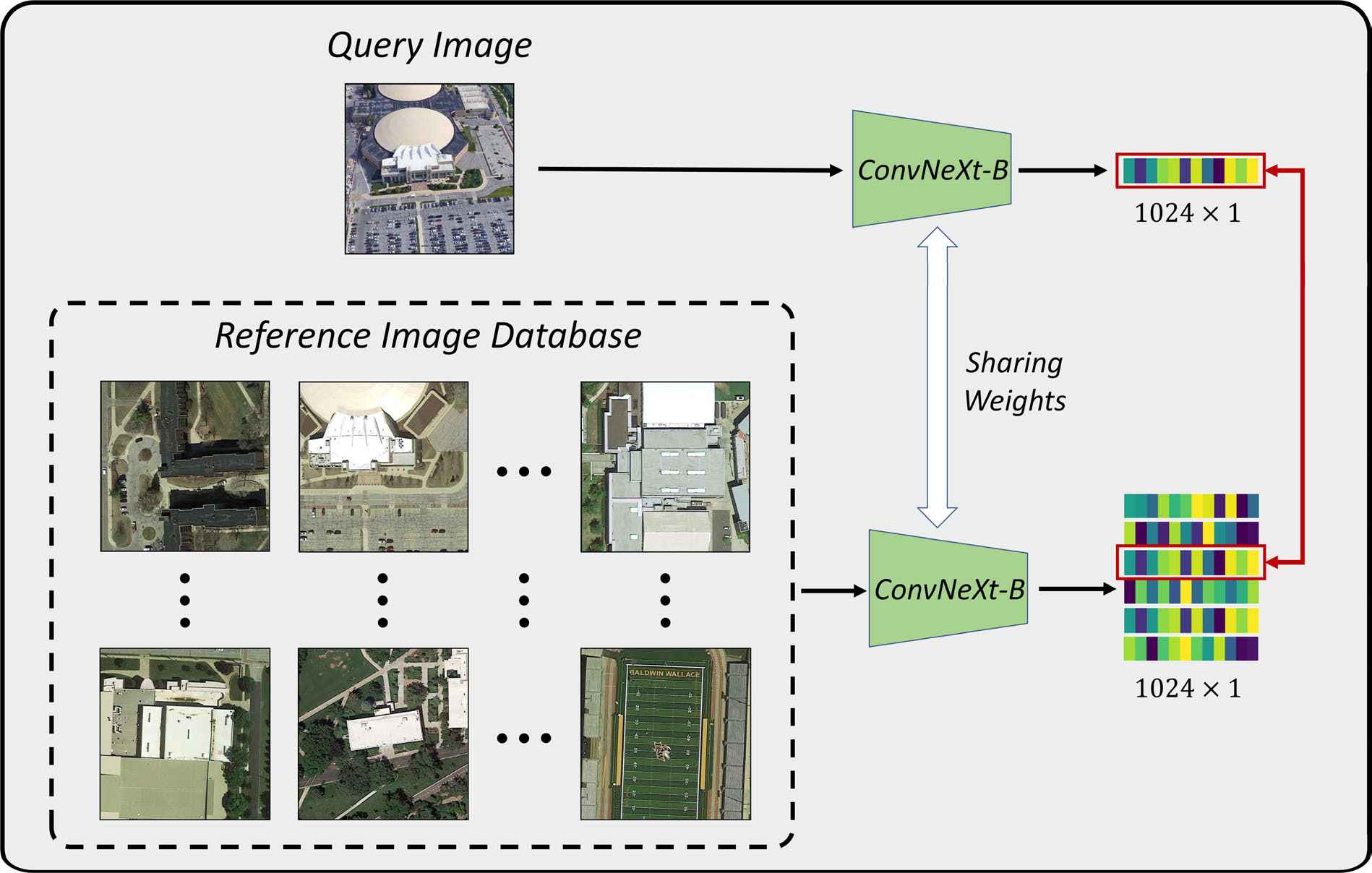
Abstract: Cross-View Geo-Localization task is aimed at establishing correspondences between images captured from different perspectives within the same geographical region. The major challenge lies in the significant appearance variations of the same scene in different views. Current methods predominantly rely on learning a representation of the coarse-grained information from images and then evaluating the similarity, while the fine-grained features are usually not well-treated. In this paper, a novel method, named DAC (Domain Alignment and scene Consistency) is proposed, which leverages contrastive learning to acquire the global information of images and simultaneously employs a domain space alignment module to align the fine-grained features. The comprehensive utilization of multi-grained vision information guarantees better feature representations. Additionally, a cross-batch scene consistency strategy is proposed in the network to establish the global supervision of the positive samples based on scene correspondence, which improves the distinctiveness of the image representations. Advanced performance is shown by our method in drone-view target localization and drone navigation applications, outperforming state-of-the-art methods in comprehensive tests on the popular public datasets University-1652 and SUES-200. Our method also outperforms existing methods in cross-region localization, showing an average improvement of 5.6% in the R@1. [full text] [link]
-
Pengcheng Shi, Shaocheng Yan, Yilin Xiao, Xinyi Liu, , Jiayuan Li. (2024) RANSAC Back to SOTA: A Two-Stage Consensus Filtering for Real-Time 3D Registration. In: IEEE Robotics and Automation Letters 09(12), 11881-11888.
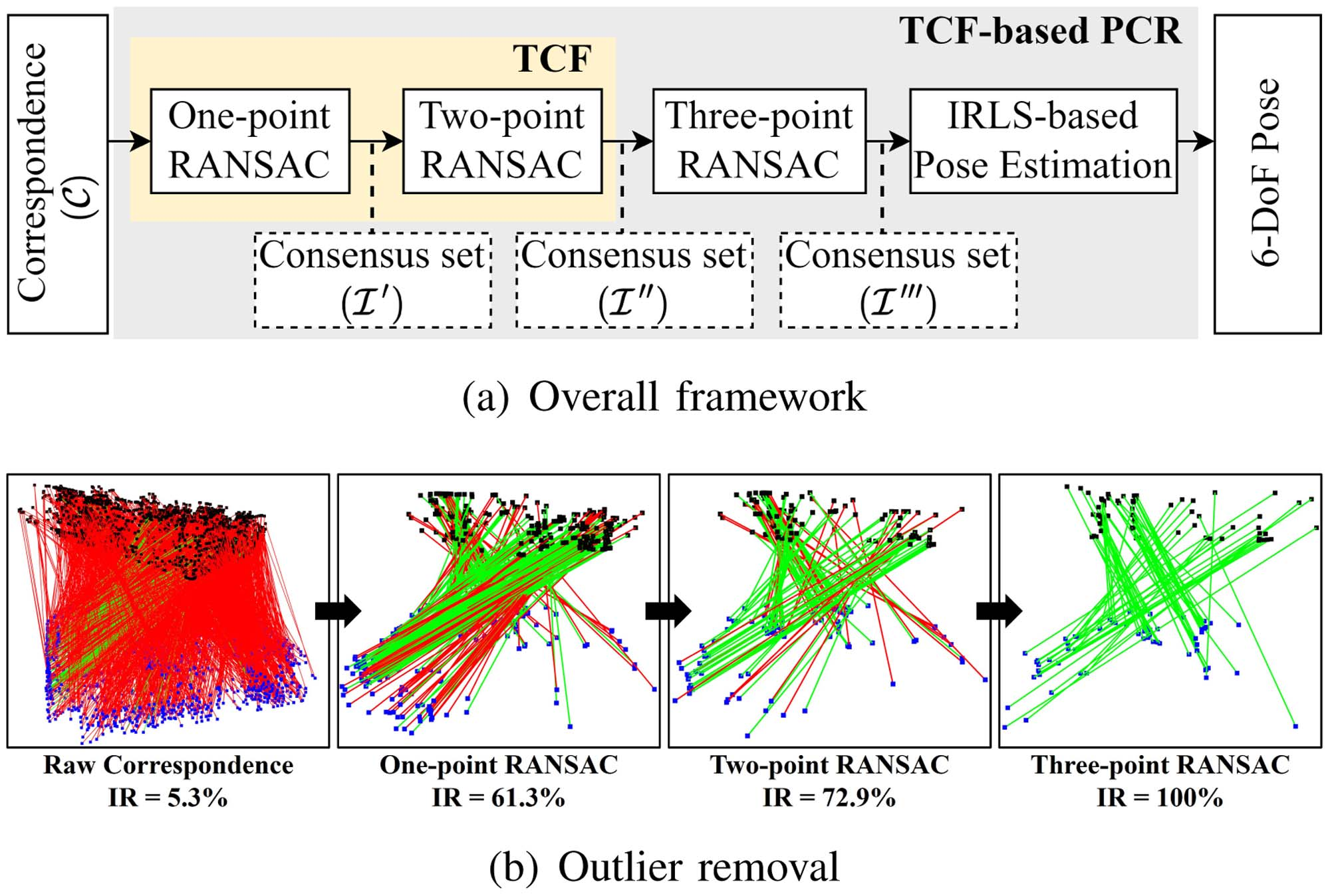
Abstract: Correspondence-based point cloud registration (PCR) plays a key role in robotics and computer vision. However, challenges like sensor noises, object occlusions, and descriptor limitations inevitably result in numerous outliers. RANSAC family is the most popular outlier removal solution. However, the requisite iterations escalate exponentially with the outlier ratio, rendering it far inferior to existing methods (SC2PCR [Chen et al., 2022], MAC [Zhang et al., 2023], etc.) in terms of accuracy or speed. Thus, we propose a two-stage consensus filtering (TCF) that elevates RANSAC to state-of-the-art (SOTA) speed and accuracy. Firstly, one-point RANSAC obtains a consensus set based on length consistency. Subsequently, two-point RANSAC refines the set via angle consistency. Then, three-point RANSAC computes a coarse pose and removes outliers based on transformed correspondence's distances. Drawing on optimizations from one-point and two-point RANSAC, three-point RANSAC requires only a few iterations. Eventually, an iterative reweighted least squares (IRLS) is applied to yield the optimal pose. Experiments on the large-scale KITTI and ETH datasets demonstrate our method achieves up to three-orders-of-magnitude speedup compared to MAC while maintaining registration accuracy and recall. [full text] [link]
-
Jiayuan Li, Qingwu Hu, Xinyi Liu, . (2024) Augmented Maximum Correntropy Criterion for Robust Geometric Perception. In: IEEE Transactions on Robotics 40, 4705-4724.

Abstract: Maximum correntropy criterion (MCC) is a robust and powerful technique to handle heavy-tailed nonGaussian noise, which has many applications in the fields of vision, signal processing, machine learning, etc. In this article, we introduce several contributions to the MCC and propose an augmented MCC (AMCC), which raises the robustness of classic MCC variants for robust fitting to an unprecedented level. Our first contribution is to present an accurate bandwidth estimation algorithm based on the probability density function (PDF) matching, which solves the instability problem of the Silverman's rule. Our second contribution is to introduce the idea of graduated nonconvexity (GNC) and a worst-rejection strategy into MCC, which compensates for the sensitivity of MCC to high outlier ratios. Our third contribution is to provide a definition of local distribution measure to evaluate the quality of inliers, which makes the MCC no longer limited to random outliers but is generally suitable for both random and clustered outliers. Our fourth contribution is to show the generalizability of the proposed AMCC by providing eight application examples in geometry perception and performing comprehensive evaluations on five of them. Our experiments demonstrate that 1) AMCC is empirically robust to 80% − 90% of random outliers across applications, which is much better than Cauchy M-estimation, MCC, and GNC-GM; 2) AMCC achieves excellent performance in clustered outliers, whose success rate is 60% − 70% percentage points higher than the second-ranked method at 80% of outliers; 3) AMCC can run in real-time, which is 10 − 100 times faster than RANSAC-type methods in low-dimensional estimation problems with high outlier ratios. This gap will increase exponentially with the model dimension. [full text] [link]
-
Ziyang Chen, Wenting Li, Zhongwei Cui, . (2024) Surface Depth Estimation From Multiview Stereo Satellite Images With Distribution Contrast Network. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 17, 17837-17845

Abstract: The calculation of surface depth based on multiview s tereo (MVS) satellite imagery is of significant importance in fields such as military and surveying. The challenge in extracting depth information from satellite imagery lies in the fact that these images often exhibit similar colors, necessitating the development of algorithms that can integrate shape and texture information. Moreover, the application of classical convolutional neural network (CNN) MVS is limited by its inability to capture long-range terrain relationships, which presents a bottleneck in existing surface depth estimation algorithms. To address the above problems, we propose the Distribution Contrast Network for Surface Depth Estimation from Satellite Multi V iew S tereo Images (DC-SatMVS), a novel satellite MVS network. In order to learn short-range and long-range features, we designed separate CNN and ViT branches. To emphasize the importance of shape and texture, we propose the Distribution Contrast Loss mechanism. This mechanism supervises the model training based on the similarity between the predicted depth and the ground truth depth distribution. Experimental results demonstrate that our method achieves state-of-the-art (SOTA) performance. We produce a remarkable 18.14% reduction in root mean square error compared to the Sat-MVSF on the WHU-TLC dataset. To validate the generalization performance of our framework, we trained and tested it on the DTU dataset, a common MVS dataset, and achieve SOTA results in this dataset as well. [full text] [link]
-
Bo Dang, Yansheng Li, , Jiayi Ma. (2024) Progressive Learning With Cross-Window Consistency for Semi-Supervised Semantic Segmentation. In: IEEE Transactions on Image Processing 33, 5219-5231.
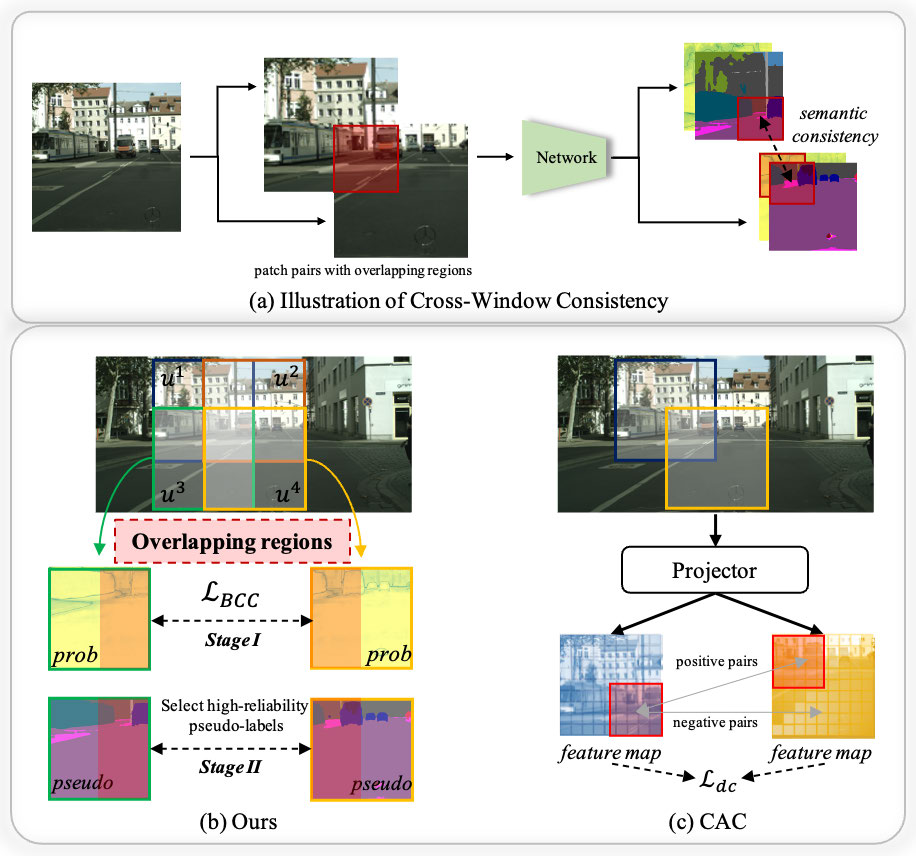
Abstract: Semi-supervised semantic segmentation focuses on the exploration of a small amount of labeled data and a large amount of unlabeled data, which is more in line with the demands of real-world image understanding applications. However, it is still hindered by the inability to fully and effectively leverage unlabeled images. In this paper, we reveal that cross-window consistency (CWC) is helpful in comprehensively extracting auxiliary supervision from unlabeled data. Additionally, we propose a novel CWC-driven progressive learning framework to optimize the deep network by mining weak-to-strong constraints from massive unlabeled data. More specifically, this paper presents a biased cross-window consistency (BCC) loss with an importance factor, which helps the deep network explicitly constrain confidence maps from overlapping regions in different windows to maintain semantic consistency with larger contexts. In addition, we propose a dynamic pseudo-label memory bank (DPM) to provide high-consistency and high-reliability pseudo-labels to further optimize the network. Extensive experiments on three representative datasets of urban views, medical scenarios, and satellite scenes with consistent performance gain demonstrate the superiority of our framework. [full text] [link]
-
Qiong Wu, Yi Wan, Zhi Zheng, , Guangshuai Wang, Zhenyang Zhao. (2024) CAMP : A Cross-View Geo-Localization Method Using Contrastive Attributes Mining and Position-Aware Partitioning. In: IEEE Transactions on Geoscience and Remote Sensing 62.
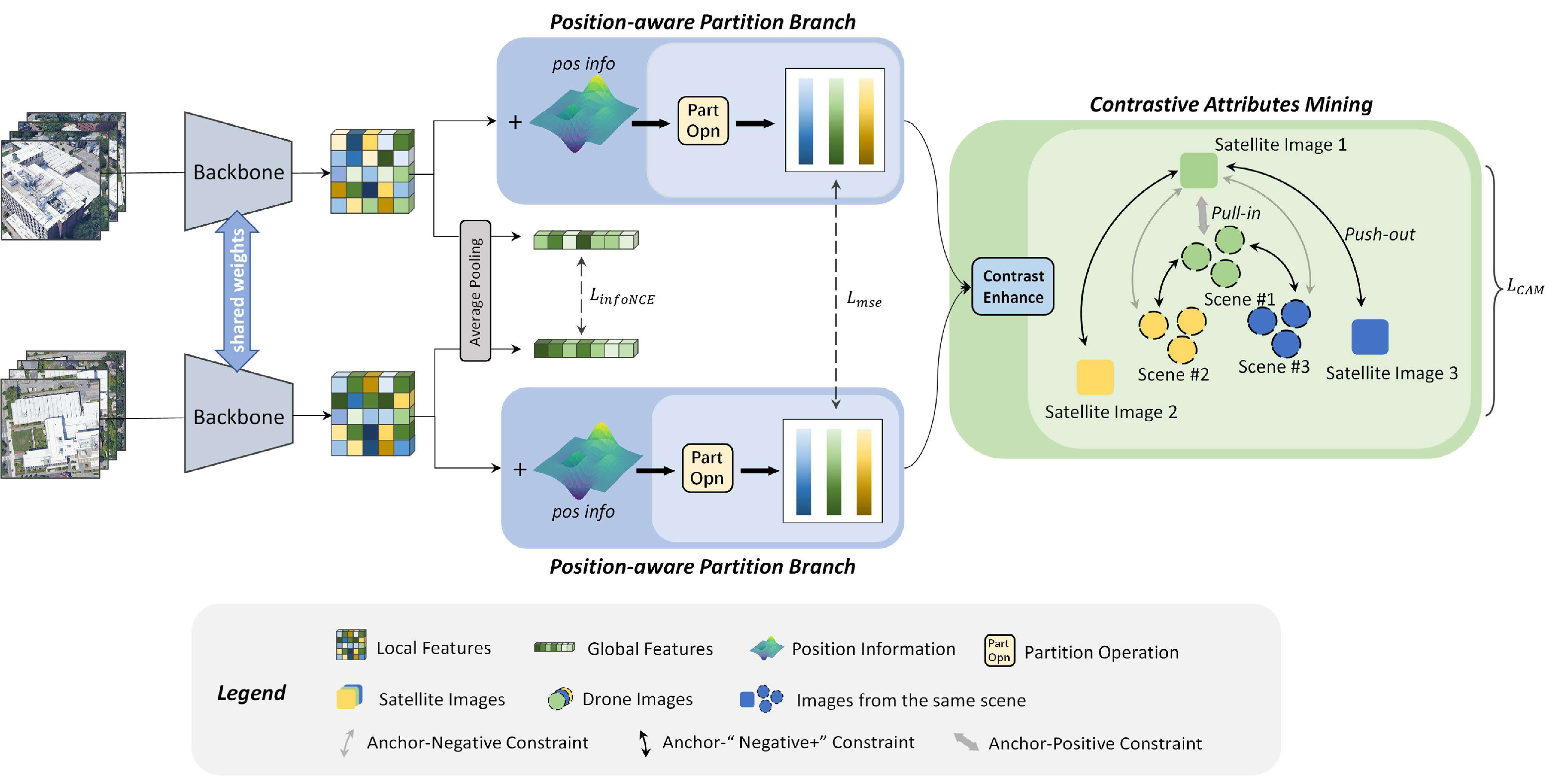
Abstract: Cross-view geo-localization (CVGL) task aims to utilize geographic data, such as maps or high-resolution satellite images, as reference to estimate the positions of a ground- or near-ground- captured query image. This task is particularly challenging due to the significant changes in visual appearance resulting from the extreme viewpoint variations. To address this challenge, a range of innovative methods have been proposed. However, intra-scene geometric information and inter-scene discriminative representation are not fully explored. In this article, we propose a novel CVGL method using contrastive attributes mining and position-aware partitioning (CAMP), which incorporates a position-aware partition branch (PPB) and a contrastive attributes mining (CAM) strategy. PPB learns fine-grained local features of different parts and captures their spatial information, providing a comprehensive understanding of scenes from both textual and spatial perspectives. CAM establishes supervision of the negative samples based on the images from the same platform, empowering the model to better discern differences between distinct scenes without extra memory cost. The proposed CAMP surpasses existing methods, achieving state-of-the-art results on the satellite-drone CVGL datasets University-1652 and SUES200. Additionally, our method also outperforms existing methods in cross-dataset generalization, achieving an 8.85% increase in R@1 when trained on the University-1652 dataset and tested on the SUES-200 dataset at a height of 150 m. [full text] [link]
-
Wangshan Yang, , Xinyi Liu, Boyong Gao. (2024) Scene Adaptive Building Individual Segmentation Based on Large-Scale Airborne LiDAR Point Clouds. In: IEEE Transactions on Geoscience and Remote Sensing 62.

Abstract: Building individual segmentation plays a crucial role in building querying, management, analysis, and attribute addition. Previous research on this topic has primarily concentrated on small-scale scenes and single-type buildings. However, when dealing with complex scenes that contain diverse buildings, existing methods for building individual segmentation often encounter challenges, such as excessive undersegmentation and oversegmentation. To tackle this issue, we propose a scene adaptive building individual segmentation (SABIS) based on large-scale airborne LiDAR point clouds. The method first segments the roof object and then extract elevation feature and area feature of the roof object. Based on these features, the building point cloud is classified into two categories: urban scene buildings and rural residential scene buildings. Finally, for urban scene buildings, the building individual segmentation method based on the cylinder model consistency is used. For rural residential scene buildings, the building individual segmentation method based on bidirectional saliency features is employed. In this article, the proposed SABIS algorithm is quantitatively evaluated by using three large scene datasets at home and abroad and four benchmark methods. All kinds of accuracy are significantly better than the most advanced algorithms. [full text] [link]
-
Fei Wang, Xianzhang Zhu, Xiaojian Liu, , Yansheng Li. (2024) Scene Graph-Aware Hierarchical Fusion Network for Remote Sensing Image Retrieval With Text Feedback. In: IEEE Transactions on Geoscience and Remote Sensing 62.
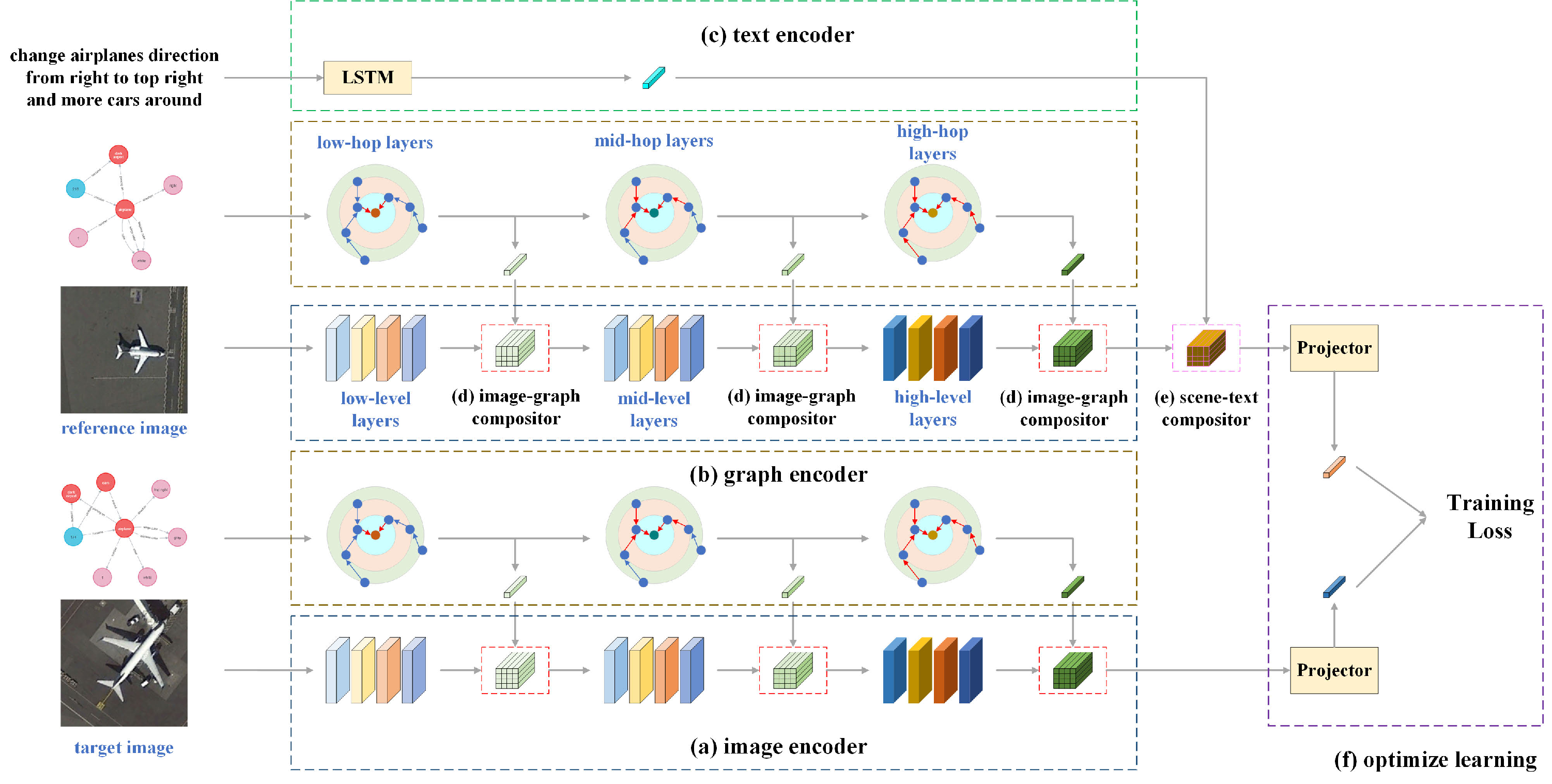
Abstract: In the realm of image retrieval with text feedback, existing studies have predominantly concentrated on the intrinsic attribute of target objects, neglecting extrinsic information essential for remote sensing (RS) images, such as spatial relationships. This research addresses this gap by incorporating RS image scene graphs as side information, given their capacity to encapsulate internal object attributes, external structural features between objects, and the relationships among images. To fully leverage the features from the reference RS image, scene graph, and modifier sentence, we propose a scene graph-aware hierarchical fusion network (SHF), which optimally integrates the multimodal features in a two-stage fusion process. Initially, image and scene graph features are fused hierarchically, followed by transforming content information with a proposed multimodal global content (MGC) block, ultimately transforming style information. To validate the superiority of SHF, we constructed three datasets with images from several popular RS datasets, named Airplane (3461 image + text–image pairs), Tennis (1924 image + text–image pairs), and WHIRT (3344 image + text–image pairs). Extensive experiments conducted on these datasets show that SHF significantly outperforms state-of-the-art methods. [full text] [link]
-
Yansheng Li, Junwei Luo, , Yihua Tan, Jin-Gang Yu, Song Bai. (2024) Learning to Holistically Detect Bridges From Large-Size VHR Remote Sensing Imagery. In: IEEE Transactions on Pattern Analysis and Machine Intelligence 46: 11507-11523.
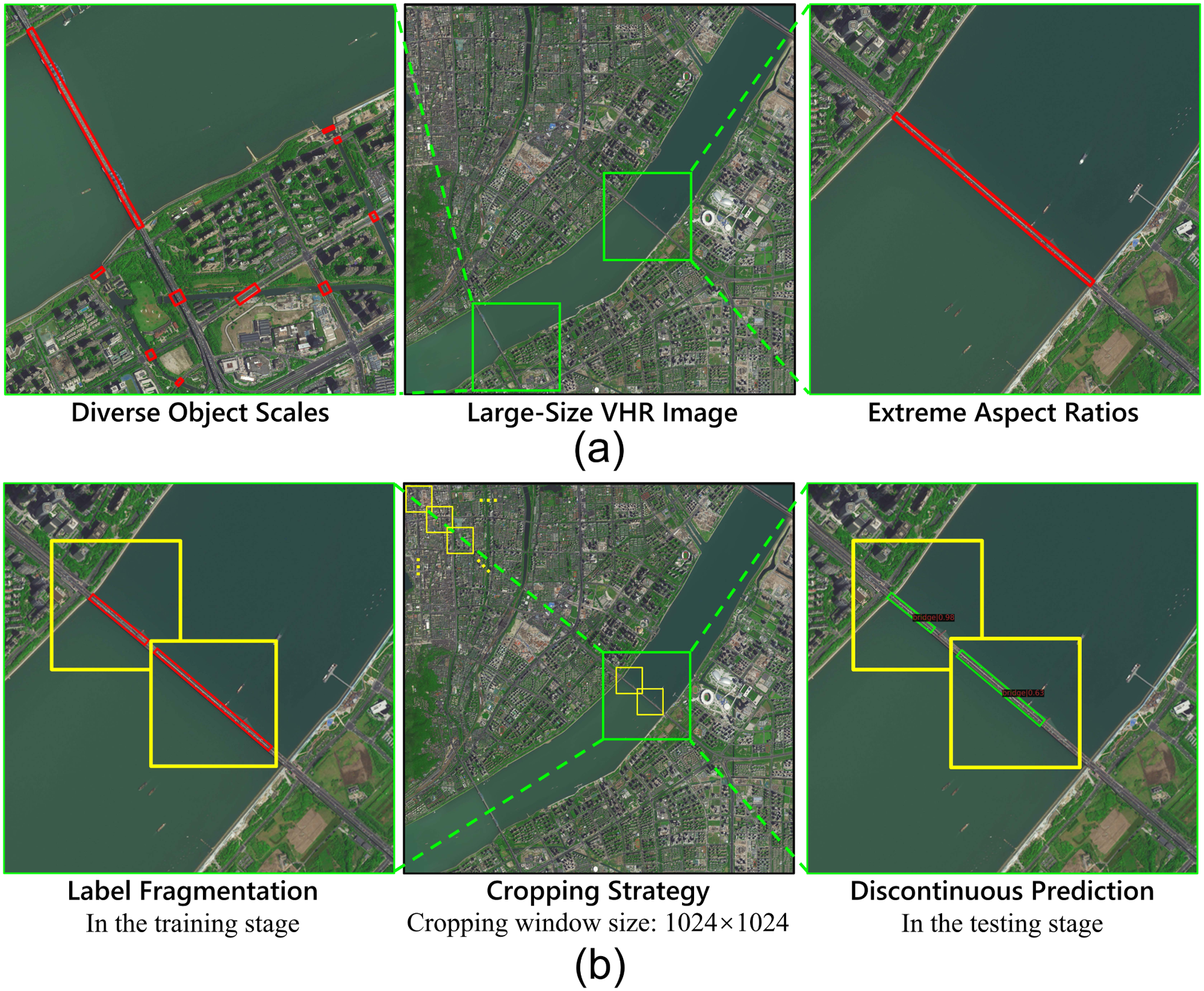
Abstract: Bridge detection in remote sensing images (RSIs) plays a crucial role in various applications, but it poses unique challenges compared to the detection of other objects. In RSIs, bridges exhibit considerable variations in terms of their spatial scales and aspect ratios. Therefore, to ensure the visibility and integrity of bridges, it is essential to perform holistic bridge detection in large-size very-high-resolution (VHR) RSIs. However, the lack of datasets with large-size VHR RSIs limits the deep learning algorithms’ performance on bridge detection. Due to the limitation of GPU memory in tackling large-size images, deep learning-based object detection methods commonly adopt the cropping strategy, which inevitably results in label fragmentation and discontinuous prediction. To ameliorate the scarcity of datasets, this paper proposes a large-scale dataset named GLH-Bridge comprising 6,000 VHR RSIs sampled from diverse geographic locations across the globe. These images encompass a wide range of sizes, varying from 2,048 × 2,048 to 16,384 × 16,384 pixels, and collectively feature 59,737 bridges. These bridges span diverse backgrounds, and each of them has been manually annotated, using both an oriented bounding box (OBB) and a horizontal bounding box (HBB). Furthermore, we present an efficient network for holistic bridge detection (HBD-Net) in large-size RSIs. The HBD-Net presents a separate detector-based feature fusion (SDFF) architecture and is optimized via a shape-sensitive sample re-weighting (SSRW) strategy. The SDFF architecture performs inter-layer feature fusion (IFF) to incorporate multi-scale context in the dynamic image pyramid (DIP) of the large-size image, and the SSRW strategy is employed to ensure an equitable balance in the regression weight of bridges with various aspect ratios. Based on the proposed GLH-Bridge dataset, we establish a bridge detection benchmark including the OBB and HBB tasks, and validate the effectiveness of the proposed HBD-Net. Additionally, cross-dataset generalization experiments on two publicly available datasets illustrate the strong generalization capability of the GLH-Bridge dataset. [full text] [link]
-
Pengcheng Shi, Yilin Xiao, Wenqing Chen, Jiayuan Li, . (2024) A New Horizon: Employing Map Clustering Similarity for LiDAR-based Place Recognition. In: IEEE Transactions on Intelligent Vehicles 57: 1-36.
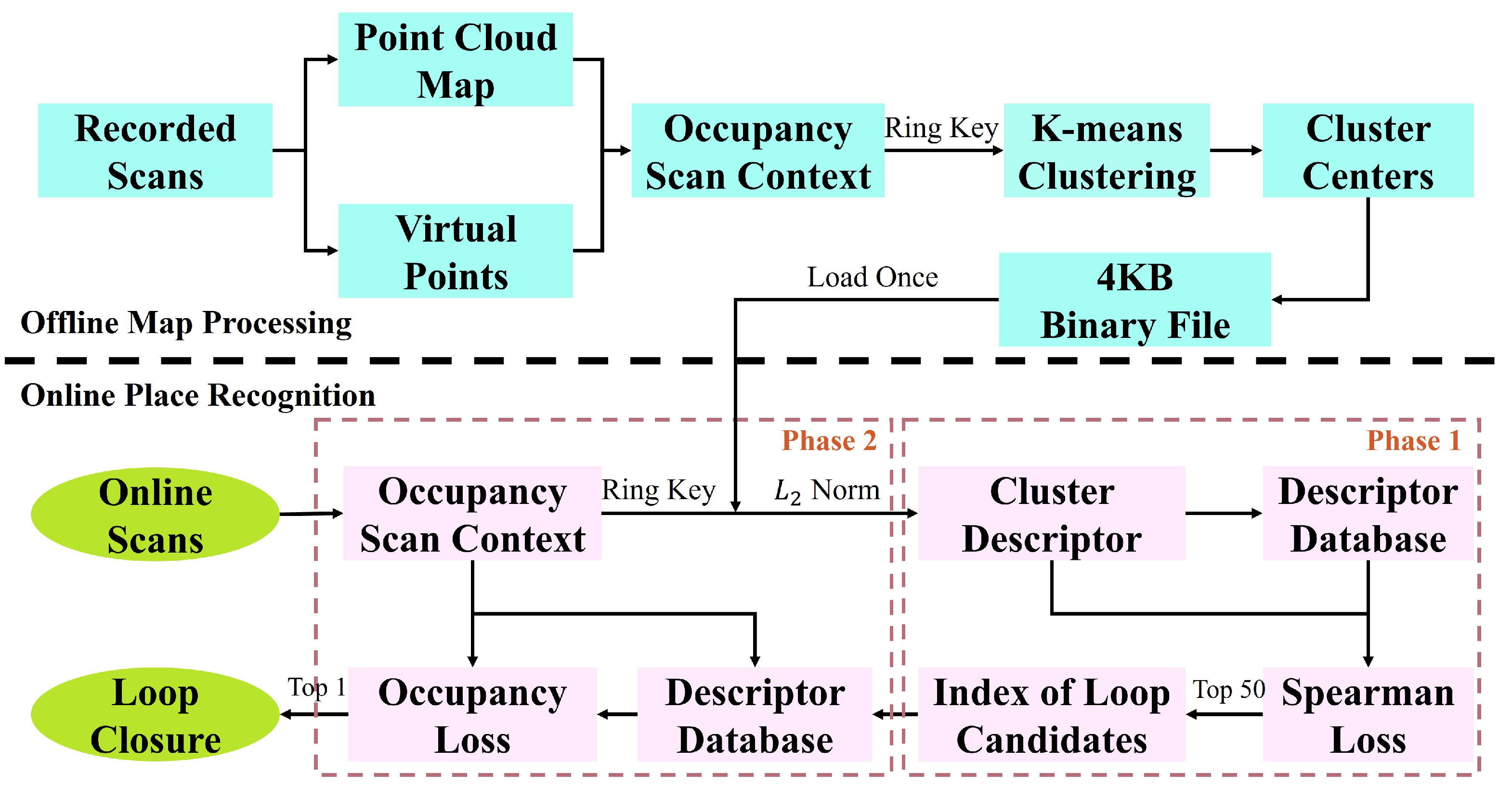
Abstract: Lidar-based Place Recognition (LPR) is crucial for intelligent vehicle navigation. Existing methods generally create LiDAR descriptors for pairwise comparisons or employ prior maps for metric localization but face challenges in computational complexity, limited robustness, and excessive memory overhead. Thus, this paper offers a fresh perspective called Map Clustering Similarity (MCS), improving robustness while reducing memory and remarkably boosting efficiency. We start by treating the ground as potential vehicle locations, i.e., virtual points, and introduce a compact LiDAR descriptor called Occupancy Scan Context (OcSC) to capture environmental occupancy from a bird's-eye view. We then employ the point cloud map, virtual points, and k-means clustering to condense the map data into 4Kb cluster centers. Eventually, we devise a two-phase online search algorithm. In the first phase, we extract the OcSC's ring key from online single-frame data, gauge its resemblance to map cluster centers to derive a cluster descriptor, and search loop candidates using the Spearman loss. In the second phase, we propose an occupancy loss to compare all candidates' OcSC descriptors to find the optimal candidate. Our method introduces a novel framework and merges advantages from existing solutions. Experiments on the KITTI dataset and two self-collected indoor sequences showcase MCS-BF's superior performance over mainstream methods in place recognition recall, F1 score, and memory consumption. Additionally, MCS successfully balances runtime with accuracy. [full text] [link]
-
Shiqing Wei, Tao Zhang, Dawen Yu, Shunping Ji, , Jianya Gong. (2024) From Lines to Polygons: Polygonal Building Contour Extraction from High-Resolution Remote Sensing Imagery. In: ISPRS Journal of Photogrammetry and Remote Sensing 209: 213-232.
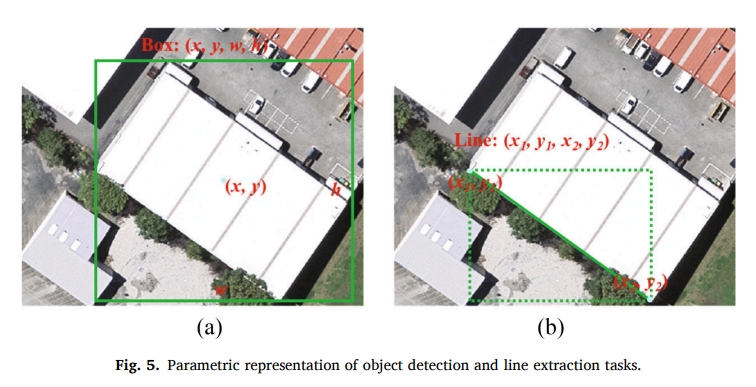
Abstract: Automated extraction of polygonal building contours from high-resolution remote sensing images is important for various applications. However, it remains a difficult task to achieve automated extraction of polygonal buildings at the level of human delineation due to diverse building structures and imperfect image conditions. In this paper, we propose Line2Poly, an end-to-end approach that uses feature lines as geometric primitives to achieve polygonal building extraction by recovering topological relationships among these lines within an individual building. To extract building feature lines with precision, we adopt a two-stage strategy that combines Convolutional Neural Network (CNN) and transformer architectures. A CNN-based module extracts preliminary feature lines, which serve as positional priors for initializing positional queries in the subsequent transformer-based module. For polygonal building contour reconstruction, we devise a learnable polygon topology reconstruction module that predicts adjacency relationships among discrete lines, and integrates lines into building polygons. The resultant building polygons, based on feature lines, exhibit inherent regularity that aligns with manual labeling standards. Extensive experiments on the Vectorizing World Buildings dataset, the WHU aerial building dataset and the WHU-Mix (vector) dataset validate Line2Poly’s impressive performance in building feature line extraction and instance-level building detection. Moreover, Line2Poly’s predictions exhibit the highest level of concurrence with manual delineations, with over 83% agreement on the WHU aerial building test set and 68.7/59.7% on the WHU-Mix (vector) test set I and II, respectively. [full text] [link]
-
Yansheng Li , Mengze Hao, Rongjie Liu, Zhichao Zhang, Hu Zhu, . (2023) Semantic-Aware Attack and Defense on Deep Hashing Networks for Remote-Sensing Image Retrieval. In: IEEE Transactions on Geoscience and Remote Sensing, 61, 5627214.

Abstract: Deep hashing networks have been successful in retrieving interesting images from massive remote-sensing images. There is no doubt that security and reliability are critical in remote-sensing image retrieval (RSIR). Recent studies about natural image retrieval have shown the vulnerability of deep hashing networks to adversarial examples, but there are no existing research studies about the attack and defense of deep hashing networks in RSIR. Due to the large intraclass difference and high interclass similarity of remote-sensing images, the attack and defense methods on deep hashing networks for natural images cannot be directly applied to the remote-sensing images. Different from the widely adopted instance-aware hash codes that often present the suboptimum performance of the attack and defense on deep hashing networks, this article recommends the usage of semantic-aware hash codes, which take into account multiple samples in the given semantic categories, in both attack and defense. To pursue the strongest attack on RSIR, a novel semantic-aware attack with weights via multiple random initialization (RWC) is proposed. To alleviate the retrieval degradation caused by adversarial attacks, a new adversarial training defense method on deep hashing networks with the adversarial semantic-aware consistency constraint (ACN) is proposed. Extensive experiments on three typical open remote-sensing image datasets (i.e., UCM, AID, and NWPU-RESISC45) show that the proposed attack and defense methods on various deep hashing networks achieve better performance compared with the state-of-the-art methods. The source code will be made publicly available along with this article. [full text] [link]
-
, Xinyi Lu, Yansong Duan, Dong We, Xianzhang Zhu, Bin Zhang, Bohui Pang. (2023) Robust Surface Crack Detection with Structure Line Guidance International. In: Journal of Applied Earth Observation and Geoinformation, 124: 103527.
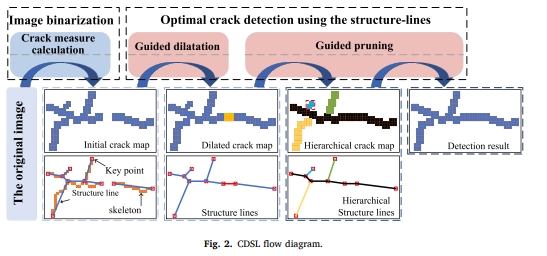
Abstract: Crack detection plays a pivotal role in civil engineering applications, where vision-based methods find extensive use. In practice, crack images are sourced from Unmanned Aerial Vehicles (UAV) and handheld photography, and the balance between the utilization of global and local information is the key to detecting cracks from images of different sources: the former tends to eliminate interferences with a global perspective, whereas the latter pays more attention to the description of local details of cracks. However, many existing methods primarily target crack detection in handheld photographs and may not perform optimally on UAV-generated images or those with variable backgrounds or from different sources. In response to this challenge, we propose a robust and innovative method called Crack Detection with Structure Line (CDSL). The primary steps of this method can be summarized as follows: first, based on local information, an indicator called the “crack measure” is derived to directly generate a continuous crack map for effective image binarization; then, based on global information, the crack map is simplified in a unified and analyzable form using structure lines to perform a robust optimization for high-precision crack detection. The experiments we conducted on two publicly available datasets showed that CDSL provided competitive crack detection performance and outperformed four classical or current state-of-the-art methods by at least 13.0 % in the UAV dataset we collected. [full text] [link]
-
Jiayuan Li, Qingwu Hu, . (2023) Multimodal Image Matching: A Scale-Invariant Algorithm and an Open Dataset. In: ISPRS Journal of Photogrammetry and Remote Sensing 204: 77-88.
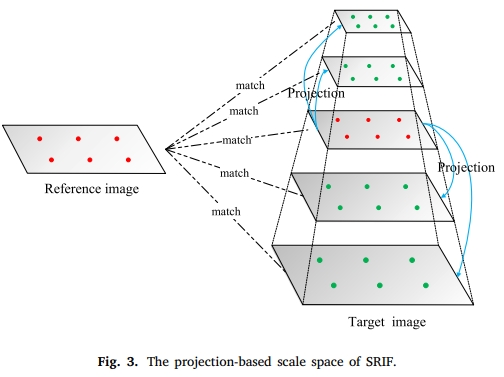
Abstract: Multimodal image matching is a core basis for information fusion, change detection, and image-based navigation. However, multimodal images may simultaneously suffer from severe nonlinear radiation distortion (NRD) and complex geometric differences, which pose great challenges to existing methods. Although deep learning-based methods had shown potential in image matching, they mainly focus on same-source images or single types of multimodal images such as optical-synthetic aperture radar (SAR). One of the main obstacles is the lack of public data for different types of multimodal images. In this paper, we make two major contributions to the community of multimodal image matching: First, we collect six typical types of images, including optical-optical, optical-infrared, optical-SAR, optical-depth, optical-map, and nighttime, to construct a multimodal image dataset with a total of 1200 pairs. This dataset has good diversity in image categories, feature classes, resolutions, geometric variations, etc. Second, we propose a scale and rotation invariant feature transform (SRIF) method, which achieves good matching performance without relying on data characteristics. This is one of the advantages of our SRIF over deep learning methods. SRIF obtains the scales of FAST keypoints by projecting them into a simple pyramid scale space, which is based on the study that methods with/without scale space have similar performance under small scale change factors. This strategy largely reduces the complexity compared to traditional Gaussian scale space. SRIF also proposes a local intensity binary transform (LIBT) for SIFT-like feature description, which can largely enhance the structure information inside multimodal images. Extensive experiments on these 1200 image pairs show that our SRIF outperforms current state-of-the-arts by a large margin, including RIFT, CoFSM, LNIFT, and MS-HLMO. Both the created dataset and the code of SRIF will be publicly available in https://github.com/LJY-RS/SRIF [full text] [link]
-
Shunping Ji, Chang Zeng, , Yulin Duan. (2023) An Evaluation of Conventional and Deep Learning-Based Image-Matching Methods on Diverse Datasets. In: The Photogrammetric Record, 38(182): 137-159.
Abstract: Image matching plays an important role in photogrammetry, computer vision and remote sensing. Modern deep learning-based methods have been proposed for image matching; however, whether they will surpass and take the place of the conventional handcrafted methods in the remote sensing field still remains unclear. A comprehensive evaluation on stereo remote sensing images is also lacking. This paper comprehensively evaluates the performance of conventional and deep learning‐based image-matching methods by dividing the matching process into feature point extraction, description and similarity measure on various datasets, including images captured from close‐range indoor and outdoor scenarios, unmanned aerial vehicles (UAVs) and satellite platforms. Different combinations of the three steps are evaluated. The experimental results reveal that, first, the performance of the different combinations varies between individual datasets, and it is difficult to determine the best combination. Second, by using more comprehensive indicators on all of the datasets, that is, the average rank and absolute rank, the combination of scale‐invariant feature transform (SIFT), ContextDesc and the nearest neighbour distance ratio (NNDR), and also the original SIFT, achieve the best results, and are recommended for use in remote sensing. Third, the deep learning‐based Sub‐SuperPoint extractor obtains a good performance, and is second only to SIFT. The learning based ContextDesc descriptor is as effective as the SIFT descriptor, and the learning based SuperGlue matcher is not as stable as NNDR, but leads to a few top‐performing combinations. Finally, the handcrafted methods are generally faster than the deep learning‐based methods, but the efficiency of the latter is acceptable. We conclude that although a full deep learning‐based method/combination has not yet beaten the conventional methods, there is still much room for improvement with the deep learning‐based methods because large‐scale aerial and satellite training datasets remain to be constructed, and specific methods for remote sensing images remain to be developed. The performance of the different combinations of feature extractor, descriptor and similarity measure varies between individual datasets. The combination of SIFT, ContextDesc and NNDR, and also the original SIFT, achieve the best results when using more comprehensive indicators on all the datasets. For extractor, the learning based Sub‐SuperPoint is second only to SIFT; for descriptor, learning‐based ContextDesc is as effective as the SIFT descriptor; and for matcher, learning‐based SuperGlue is not as stable as NNDR. [full text] [link]
-
Zhongbin Li, , Mengqiu Wang. (2023) Solar Energy Projects Put Food Security at Risk. In: Science, 381 (6659).

Abstract: 18 AUGUST 2023• VOL 381 ISSUE 6659 741 SCIENCE science. org built on farmland, threatening food security (2, 3). Given the ambitious climate pledges of signatory countries to the Paris Agreement, the area of land required to deploy global solar photovoltaics in the coming decades is expected to rise (4). Governments must act now to mitigate the fierce competition for land between solar energy and crops. Solar energy projects have encroached on farmland across the Northern Hemisphere (3). In 2017 alone, China deployed photovoltaic panels on about 100 km2 of farmlands in the North China Plain (3), one of China's most important agricultural regions. Solar photovoltaic panels have also been deployed over deserts, abandoned mines (5), artificial canals (6), reservoirs (7), and rooftops (8), but these options are less attractive to developers because they are more scarce, more unstable, or more expensive than farmlands. To ensure national food security, some countries have released strict farmland protection regulations [eg, China's Basic Farmland Protection Regulations in 1994, Germany's Federal Regional Planning Act in 1997, and South Korea's Farmland Act in 1994 (9)]. However, solar energy investors and developers continue to occupy farmland illegally (10). Local authorities provide inadequate enforcement, allowing development to proceed at the expense of agriculture. Mitigating solar energy's land competition will require technological innovation and more sustainable deployment strategies. For example, agrivoltaic systems have been proposed that would allow crops to grow under solar panels (11). However, the solar panels hinder mechanized farming and harvesting, and the solar photovoltaics need to be deployed at a position much higher than crops, making the project more expensive. Scientists have also developed foldable solar cells that can be integrated into buildings (12). Until these technologies are cost-effective and scalable, governments should preferentially use unproductive lands for large-scale photovoltaic deployment, prevent installations on finite arable land, and provide stricter enforcement of farmland protection policies. Satellite remote sensing technologies should be used to closely monitor solar photovoltaic panels' illegal farmland encroachment and quantify their impacts on food production. Illegally deployed solar photovoltaics should be demolished so that farmland can be restored. Governments, corporations, and nonprofit organizations should also provide funding to scientists to research and develop cost-effective, ecofriendly, energy-efficient solar cells, including agrivoltaic technology. Scientists should also work to better understand the adverse and unintended consequences of large-scale solar photovoltaic deployment to ensure that the technology provides net benefits in the future. [full text] [link]
-
Yameng Wang, Yi Wan, , Bin Zhang, Zhi Gao. (2023) Imbalance Knowledge-driven Multi-modal Network for Land-cover Semantic Segmentation using Aerial Images and LiDAR Point Clouds. In: ISPRS Journal of Photogrammetry and Remote Sensing 202: 385-404.
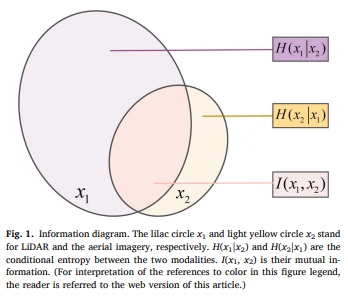
Abstract: Despite the good results that have been achieved in unimodal segmentation, the inherent limitations of individual data increase the difficulty of achieving breakthroughs in performance. For that reason, multi-modal learning is increasingly being explored within the field of remote sensing. The present multi-modal methods usually map high-dimensional features to low-dimensional spaces as a preprocess before feature extraction to address the nonnegligible domain gap, which inevitably leads to information loss. To address this issue, in this paper we present our novel Imbalance Knowledge-Driven Multi-modal Network (IKD-Net) to extract features from multi-modal heterogeneous data of aerial images and LiDAR directly. IKD-Net is capable of mining imbalance information across modalities while utilizing a strong modal to drive the feature map refinement of the weaker ones in the global and categorical perspectives by way of two sophisticated plug-and-play modules: the Global Knowledge-Guided (GKG) and Class Knowledge-Guided (CKG) gated modules. The whole network then is optimized using a joint loss function. While we were developing IKD-Net, we also established a new dataset called the National Agriculture Imagery Program and 3D Elevation Program Combined dataset in California (N3C-California), which provides a particular benchmark for multi-modal joint segmentation tasks. In our experiments, IKD-Net outperformed the benchmarks and state-of-the-art methods both in the N3C-California and the small-scale ISPRS Vaihingen dataset. IKD-Net has been ranked first on the real-time leaderboard for the GRSS DFC 2018 challenge evaluation until this paper's submission. Our code and N3C-California dataset are available at https://github.com/wymqqq/IKDNet-pytorch. [full text] [link]
-
Bin Zhang, , Yansheng Li, Yi Wan, Haoyu Guo, Zhi Zheng, Kun Yang. (2023) Semi-Supervised Deep Learning via Transformation Consistency Regularization for Remote Sensing Image Semantic Segmentation. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 16: 5782-5796.

Abstract: Deep convolutional neural networks (CNNs) have gotten a lot of press in the last several years, especially in domains like computer vision (CV) and remote sensing (RS). However, achieving superior performance with deep networks highly depends on a massive amount of accurately labeled training samples. In real-world applications, gathering a large number of labeled samples is time-consuming and labor-intensive, especially for pixel-level data annotation. This dearth of labels in land-cover classification is especially pressing in the RS domain because high-precision, high-quality labeled samples are extremely difficult to acquire, but unlabeled data is readily available. In this study, we offer a new semi-supervised deep semantic labeling framework for semantic segmentation of high-resolution RS images to take advantage of the limited amount of labeled examples and numerous unlabeled samples. Our model uses transformation consistency regularization (TCR) to encourage consistent network predictions under different random transformations or perturbations. We try three different transforms to compute the consistency loss and analyze their performance. Then, we present a deep semi-supervised semantic labeling technique by using a hybrid transformation consistency regularization (HTCR). A weighted sum of losses, which contains a supervised term computed on labeled samples and an unsupervised regularization term computed on unlabeled data, may be used to update the network parameters in our technique. Our comprehensive experiments on two RS datasets confirmed that the suggested approach utilized latent information from unlabeled samples to obtain more precise predictions and outperformed existing semi-supervised algorithms in terms of performance. Our experiments further demonstrated that our semi-supervised semantic labeling strategy has the potential to partially tackle the problem of limited labeled samples for high-resolution RS image land-cover segmentation. [full text] [link]
-
Zhi Gao, Wenbo Sun, Yao Lu, Yichen Zhang, Weiwei Song, , Ruifang Zhai. (2023) Joint Learning of Semantic Segmentation and Height Estimation for Remote Sensing Image Leveraging Contrastive Learning. In: IEEE Transactions on Geoscience and Remote Sensing, 61: 1-15.
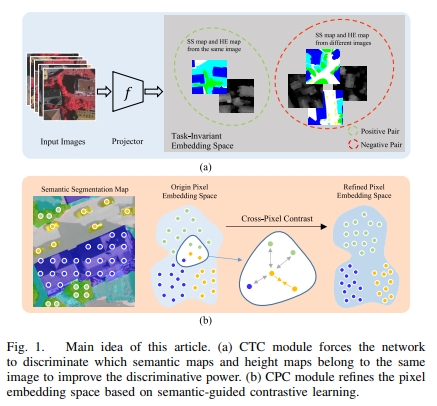
Abstract: Semantic segmentation (SS) and height estimation (HE) are two critical tasks in remote sensing scene understanding that are highly correlated with each other. To address both the tasks simultaneously, it is natural to consider designing a unified deep learning model that aims to improve performance by jointly learning complementary information among the associated tasks. In this article, we learn the two tasks jointly under a deep multitask learning (MTL) framework and propose two novel objective functions, called cross-task contrastive (CTC) loss and cross-pixel contrastive (CPC) loss, respectively, to enhance MTL performance through contrastive learning. Specifically, the CTC loss is designed to maximize the mutual information of different task features and enforce the model to learn the consistency between SS and height estimation. In addition, our method goes beyond previous approaches that only apply contrastive learning at the instance level. Instead, we design a pixelwise contrastive loss function that pulls together pixel embeddings belonging to the same semantic class, while pushing apart pixel embeddings from different semantic classes. Furthermore, we find that this semantic-guided contrastive loss simultaneously improves the performance of the HE task. Our proposed approach is simple and effective and does not introduce any additional overhead to the model during the testing phase. We extensively evaluate our method on the Vaihingen and Potsdam datasets, and the experimental results demonstrate that our approach significantly outperforms the state-of-the-art methods in both HE and SS. [full text] [link]
-
Jiayuan Li, Pengcheng Shi, Qingwu Hu, . (2023) QGORE: Quadratic-Time Guaranteed Outlier Removal for Point Cloud Registration. In: IEEE Transactions on Pattern Analysis and Machine Intelligence.
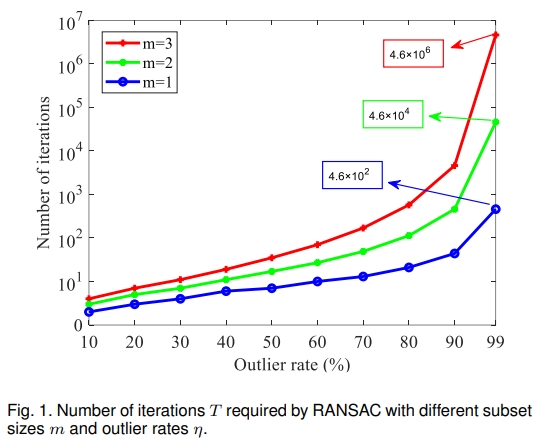
Abstract: With the development of 3D matching technology, correspondence-based point cloud registration gains more attention. Unfortunately, 3D keypoint techniques inevitably produce a large number of outliers, i.e., outlier rate is often larger than 95%. Guaranteed outlier removal (GORE) Bustos and Chin has shown very good robustness to extreme outliers. However, the high computational cost (exponential in the worst case) largely limits its usages in practice. In this paper, we propose the first O(N2) time GORE method, called quadratic-time GORE (QGORE), which preserves the globally optimal solution while largely increases the efficiency. QGORE leverages a simple but effective voting idea via geometric consistency for upper bound estimation, which achieves almost the same tightness as the one in GORE. We also present a one-point RANSAC by exploring “rotation correspondence” for lower bound estimation, which largely reduces the number of iterations of traditional 3-point RANSAC. Further, we propose a lpp -like adaptive estimator for optimization. Extensive experiments show that QGORE achieves the same robustness and optimality as GORE while being 1 ∼ 2 orders faster. The source code will be made publicly available. [full text] [link]
-
Pengcheng Shi, Jiayuan Li, . (2023) LiDAR Localization at 100 FPS: A Map-aided and Template Descriptor-based Global Method. In: International Journal of Applied Earth Observation and Geoinformation, 120: 103336.
Abstract: With the development of multi-beam Light Detection and Ranging (LiDAR) sensors, fast and accurate LiDAR-based localization has become a crucial issue in robotics and autonomous driving. However, balancing accuracy and efficiency remains challenging in existing methods. In this paper, we propose a super-fast LiDAR global localization approach that can achieve state-of-the-art (SOTA) accuracy with superior efficiency. Our method leverages template descriptors to capture structural environments and approximates the vehicle’s position via map candidate points. Additionally, we create an offline map database to evenly simulate vehicle orientations. We design a loss function to improve localization accuracy. We extensively evaluated the proposed method in public KITTI outdoor sequences and self-collected indoor datasets. The experimental results show that our approach can run at close to 100 frames per second (FPS) on a single-thread CPU, which is much faster than current SOTA methods. Our average absolute translation errors (ATEs) are 0.20m (indoor) and 0.44m (outdoor), and the average localization success rates are 93% (indoor) and 90% (outdoor). The average localization success rates can exceed 97% in large outdoor scenarios with fine-tuned parameters. The source code will be available in https://github.com/ShiPC-AI. [full text] [link]
-
Yansheng Li, Xinwei Li, , Daifeng Peng, Lorenzo Bruzzone. (2023) Cost-Efficient Information Extraction From Massive Remote Sensing Data: When Weakly Supervised Deep Learning Meets Remote Sensing Big Data. In: International Journal of Applied Earth Observation and Geoinformation, 120: 103345.
Abstract: With many platforms and sensors continuously observing the earth surface, the large amount of remote sensing data presents a big data challenge. While remote sensing data acquisition capability can fully meet the requirements of many application domains, there is still a need to further explore how to efficiently mine the useful information from remote sensing big data (RSBD). Many researchers in the remote sensing community have introduced deep learning in the process of RSBD, and deep learning-based methods have achieved better performance compared with traditional methods. However, there are still substantial obstacles to the application of deep learning in remote sensing. One of the major challenges is the generation of pixel-level labels with high quality for training samples, which is essential to deep learning models. Weakly supervised deep learning (WSDL) is a promising solution to address this problem as WSDL can utilize greedily labeled datasets that are easy to collect but not ideal to train the deep networks. In this review, we summarize the achievements of WSDL-driven cost-efficient information extraction from RSBD. We first analyze the opportunities and challenges of information extraction from RSBD. Based on the analysis of the theoretical foundations of WSDL in the computer vision (CV) domain, we conduct a survey on the WSDL-based information extraction methods under the data characteristic and task demand of RSBD in four different tasks: (i) scene classification, (ii) object detection, (iii) semantic segmentation and (iv) change detection. Finally, potential research directions are outlined to guide researchers to further exploit WSDL-based information extraction from RSBD. [full text] [link]
-
, Wenpin Wu, Yiliang Li, Yansheng Li. (2023) An Investigation of PM2.5 Concentration Changes in Mid-Eastern China Before and After COVID-19 Outbreak. In: Environment International, 175, 107941.
Abstract: With the Chinese government revising ambient air quality standards and strengthening the monitoring and management of pollutants such as PM2.5, the concentrations of air pollutants in China have gradually decreased in recent years. Meanwhile, the strong control measures taken by the Chinese government in the face of COVID-19 in 2020 have an extremely profound impact on the reduction of pollutants in China. Therefore, investigations of pollutant concentration changes in China before and after COVID-19 outbreak are very necessary and concerning, but the number of monitoring stations is very limited, making it difficult to conduct a high spatial density investigation. In this study, we construct a modern deep learning model based on multi-source data, which includes remotely sensed AOD data products, other reanalysis element data, and ground monitoring station data. Combining satellite remote sensing techniques, we finally realize a high spital density PM2.5 concentration change investigation method, and analyze the seasonal and annual, the spatial and temporal characteristics of PM2.5 concentrations in Mid-Eastern China from 2016 to 2021 and the impact of epidemic closure and control measures on regional and provincial PM2.5 concentrations. We find that PM2.5 concentrations in Mid-Eastern China during these years is mainly characterized by “north-south superiority and central inferiority”, seasonal differences are evident, with the highest in winter, the second highest in autumn and the lowest in summer, and a gradual decrease in overall concentration during the year. According to our experimental results, the annual average PM2.5 concentration decreases by 3.07 % in 2020, and decreases by 24.53 % during the shutdown period, which is probably caused by China's epidemic control measures. At the same time, some provinces with a large share of secondary industry see PM2.5 concentrations drop by more than 30 %. By 2021, PM2.5 concentrations rebound slightly, rising by 10 % in most provinces. [full text] [link]
-
Siyuan Zou, Xinyi Liu, Xu Huang, , Senyuan Wang, Shuang Wu, Zhi Zheng, Bingxin Liu. (2023) Edge-Preserving Stereo Matching Using LiDAR Points and Image Line Features. In: IEEE Geoscience and Remote Sensing Letters, 2023, 20: 6000205.

Abstract: This letter proposes a LiDAR and image line-guided stereo matching method (L2GSM), which combines sparse but high-accuracy LiDAR points and sharp object edges of images to generate accurate and fine-structure point clouds. After extracting depth discontinuity lines on the image by using LiDAR depth information, we propose a trilateral update of cost volume and depth discontinuity lines-aware semi-global matching (SGM) strategies to integrate LiDAR data and depth discontinuity lines into the dense matching algorithm. The experimental results for the indoor and aerial datasets show that our method significantly improves the results of the original SGM and outperforms two state-of-the-art LiDAR constraints' SGM methods, especially in recovering the 3-D structure of low-textured and depth discontinuity regions. In addition, the 3-D point clouds generated by our proposed method outperform the LiDAR data and dense matching point clouds generated by Metashape and SURE aerial in terms of completeness and edge accuracy. [full text] [link]
-
Senyuan Wang, Xinyi Liu, , Jonathan Li, Siyuan Zou, Jipeng Wu, Chuang Tao, Quan Liu, Guorong Cai. (2023) Semantic-guided 3D Building Reconstruction from Triangle Meshes. In: International Journal of Applied Earth Observation and Geoinformation, 119, 103324.
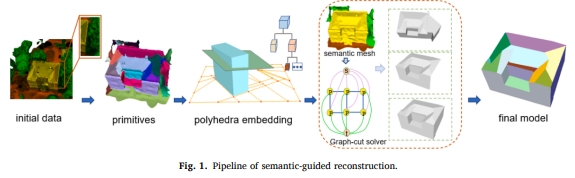
Abstract: Planar primitives tend to be incorrectly detected or incomplete in complex scenes where adhesions exist between different objects, resulting in topology errors in the reconstructed models. We propose a semantic-guided building reconstruction method known as semantic-guided reconstruction (SGR), which is capable of achieving the independence and integrity of building models in two key stages. In the first stage, the space partition is represented by a 2.5D convex cell complex and is capable of restoring planar primitives that are easily lost and can further infer the potential structural adaptivity. The second stage incorporates semantic information into a graph-cut formulation that can assist in the independent reconstruction of buildings while eliminating interference from the surrounding environment. Our experimental results confirmed that the SGR method can authentically reconstruct weakly observed surfaces. Furthermore, qualitative and quantitative evaluations show that SGR is suitable for reconstructing surfaces from insufficient data with semantic and geometric ambiguity or semantic errors and can obtain watertight models considering fidelity, integrity and time complexity. [full text] [link]
-
Xinyi Liu, Xianzhang Zhu, , Senyuan Wang, Chen Jia. (2023) Generation of Concise 3D Building Model from Dense Meshes by Extracting and Completing Planar Primitives. In: The Photogrammetric Record, 38(181): 22-46.
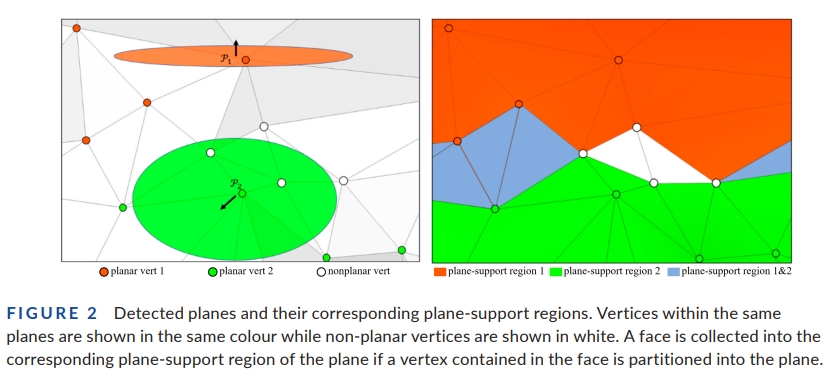
Abstract: The generation of a concise building model has been and continues to be a challenge in photogrammetry and computer graphics. The current methods typically focus on the simplicity and fidelity of the model, but those methods either fail to preserve the structural information or suffer from low computational efficiency. In this paper, we propose a novel method to generate concise building models from dense meshes by extracting and completing the planar primitives of the building. From the perspective of probability, we first extract planar primitives from the input mesh and obtain the adjacency relationships between the primitives. Since primitive loss and structural defects are inevitable in practice, we employ a novel structural completion approach to eliminate linkage errors. Finally, the concise polygonal mesh is reconstructed by connectivity-based primitive assembling. Our method is efficient and robust to various challenging data. Experiments on various building models revealed the efficacy and applicability of our method. [full text] [link]
-
Yansheng Li, Fanyi Wei, , Wei Chen, Jiayi Ma. (2023) HS2P: Hierarchical spectral and structure-preserving fusion network for multimodal remote sensing image cloud and shadow removal. In: Information Fusion, 94: 215-228.
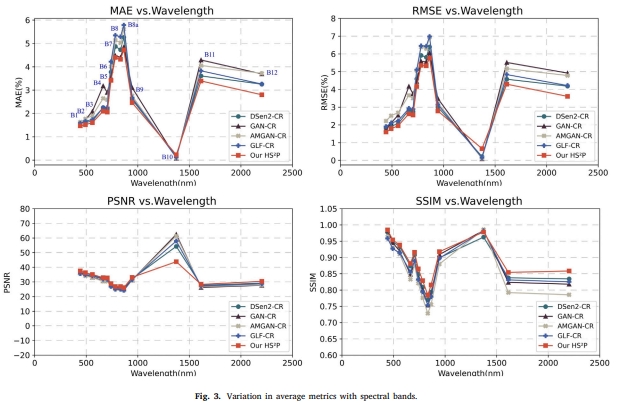
Abstract: Optical remote sensing images are often contaminated by clouds and shadows, resulting in missing data, which greatly hinders consistent Earth observation missions. Cloud and shadow removal is one of the most important tasks in optical remote sensing image processing. Due to the characteristics of active imaging that enable synthetic aperture radar (SAR) to penetrate cloud cover and other climatic conditions, SAR data are extensively utilized to guide optical remote sensing image cloud and shadow removal. Nevertheless, SAR data are highly corrupted by speckle noise, which generates artifact pollution to spectral features extracted from optical images and makes SAR-optical fusion ill-posed to generate cloud and shadow removal results while retaining high spectral fidelity and reasonable spatial structures. To overcome the aforementioned drawbacks, this paper presents a novel hierarchical spectral and structure-preserving fusion network (HS2P), which can recover cloud and shadow regions in optical remote sensing imagery based on the hierarchical fusion of optical and SAR remote sensing imagery. In HS2P, we present a deep hierarchical architecture with stacked residual groups (ResGroups), which progressively constrains the reconstruction. To pursue the adaptive selection of more informative features for fusion and reduce attention to the features with artifacts brought by clouds and shadows in optical data or speckle noise in SAR data, residual blocks with a channel attention mechanism (RBCA) are recommended. Additionally, a novel collaborative optimization loss function is proposed to preserve spectral features while enhancing structural details. Extensive experiments on the publicly open dataset (i.e., SEN12MS-CR) demonstrate that the proposed method can robustly recover diverse ground information in optical remote sensing imagery with various cloud types. Compared with the state-of-the-art cloud and shadow removal methods, our HS2P achieves significant improvements in terms of quantitative and qualitative results. The source code is publicly available at https://github.com/weifanyi515/HS2P. [full text] [link]
-
, Yongxiang Yao, Yi Wan, Weiyu Liu, Wupeng Yang, Zhi Zheng, Rang Xiao. (2023) Histogram of the Orientation of the Weighted Phase Descriptor for Multi-modal Remote Sensing Image Matching. In: ISPRS Journal of Photogrammetry and Remote Sensing 196: 1-15.
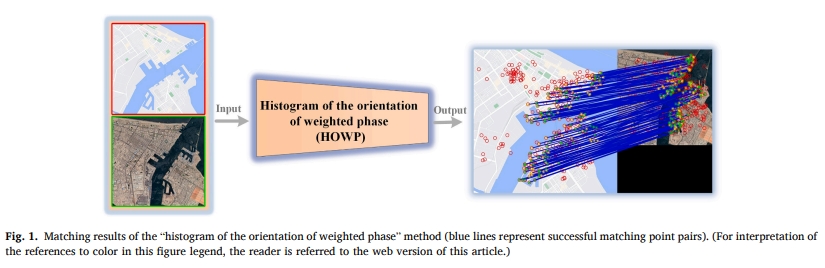
Abstract: Multi-modal remote sensing image (MRSI) has nonlinear radiation distortion (NRD) and significant contrast differences to which image gradient features are usually sensitive. Although image phase features are more robust against NRD, they might not be much helpful in resolving the problems of directional inversion or phase extreme value mutations that are common in the phase feature calculation. To address these issues, a new MRSI matching method—“histogram of the orientation of weighted phase” (HOWP)—is proposed in this paper. This method distinguishes itself from other methods in three aspects: (1) a feature aggregation strategy is used to optimize feature points by extracting the corner and blob features separately; (2) a novel weighted phase orientation model is established to replace the traditional image gradient orientation features; and (3) a regularization-based log-polar descriptor is constructed to generate robust feature description vectors. To evaluate the performance of the proposed method, we selected 50 sets of typical MRSIs with translation, scale, and rotation differences for comparison with the other four state-of-the-art methods. The results show that our method is more resistant to radiometric distortion and the contrasting differences in MRSIs. It also performs better in tackling the problems of direction reversal and phase extreme value mutation, as evidenced by more, the number of correct matches (NCM). Since the method has improved the average NCM by 1.6-4.5 times, the average success rate by 35.5%, and the average rate of correct matches by 11.1% with an average root of mean-squared error of 1.93 pixels. Moreover, we have put forward an extended version of the HOWP method (Simplified-HOWP) when there is no image rotation, which manifests in an average 0.75 times improvement in NCM of Simplified-HOWP performance over that of the HOWP method. The executable code and test data are linked in https://skyearth.org/publication/project/HOWP/. [full text] [link]
-
Xiaojian Liu, , Huimin Zou, Fei Wang, Xin Cheng, Wenpin Wu, Xinyi Liu, Yansheng Li. (2023) Multi-source Knowledge Graph Reasoning for Ocean Oil Spill Detection from Satellite SAR Images. In: International Journal of Applied Earth Observation and Geoinformation, 116: 103153.
Abstract: Marine oil spills can cause severe damage to the marine environment and biological resources. Using satellite remote sensing technology is one of the best ways to monitor the sea surface in near real-time to obtain oil spill information. The existing methods in the literature either use deep convolutional neural networks in synthetic aperture radar (SAR) images to directly identify oil spills or use traditional methods based on artificial features sequentially to distinguish oil spills from sea surface. However, both approaches currently only use image information and ignore some valuable auxiliary information, such as marine weather conditions, distances from oil spill candidates to oil spill sources, etc. In this study, we proposed a novel method to help detect marine oil spills by constructing a multi-source knowledge graph, which was the first one specifically designed for oil spill detection in the remote sensing field. Our method can rationally organize and utilize various oil spill-related information obtained from multiple data sources, such as remote sensing images, vectors, texts, and atmosphere-ocean model data, which can be stored in a graph database for user-friendly query and management. In order to identify oil spills more effectively, we also proposed 13 new dark spot features and then used a feature selection technique to create a feature subset that was favorable to oil spill detection. Furthermore, we proposed a knowledge graph-based oil spill reasoning method that combines rule inference and graph neural network technology, which pre-inferred and eliminated most non-oil spills using statistical rules to alleviate the problem of imbalanced data categories (oil slick and non-oil slick). Entity recognition is ultimately performed on the remaining oil spill candidates using a graph neural network algorithm. To verify the effectiveness of our knowledge graph approach, we collected 35 large SAR images to construct a new dataset, for which the training set contained 110 oil slicks and 66264 non-oil slicks from 18 SAR images, the validation set contained 35 oil slicks and 69005 non-oil slicks from 10 SAR images, and the testing set contained 36 oil slicks and 36281 non-oil slicks from the remaining 7 SAR images. The results showed that some traditional oil spill detection methods and deep learning models failed when the dataset suffered a severe imbalance, while our proposed method identified oil spills with a sensitivity of 0.8428, specificity of 0.9985, and precision of 0.2781 under those same conditions. The knowledge graph method we proposed using multi-source data can not only help solve the problem of information island in oil spill detection, but serve as a guide for construction of remote sensing knowledge graphs in many other applications as well. The dataset gathered has been made freely available online (https://pan.baidu.com/s/1DDaqIljhjSMEUHyaATDIYA?pwd=qmt6). [full text] [link]
-
Zhiyong Peng, Jun Wu, , Xianhua Lin. (2023) MFVNet: A Deep Adaptive Fusion Network with Multiple Field-of-Views for Remote Sensing Image Semantic Segmentation. In: Science China Information Science 2023, 66: 140305.
Abstract: In recent years, the remote sensing image (RSI) semantic segmentation attracts increasing research interest due to its wide application. RSIs are difficult to be processed holistically on current GPU cards on account of their large field-of-views (FOVs). However, the prevailing practices such as downsampling and cropping will inevitably decrease the quality of semantic segmentation. To address this conflict, this paper proposes a new deep adaptive fusion network with multiple FOVs (MFVNet), which is specially designed for RSI semantic segmentation. Different from existing methods, MFVNet takes into consideration the differences among multiple FOVs. By pyramid sampling the RSI, we first obtain images on different scales with multiple FOVs. Images on the high scale with a large FOV can capture larger spatial contexts and complete object contours, while images on the low scale with a small FOV can keep the higher spatial resolution and more detailed information. Then scale-specific models are chosen to make the best predictions for all scales. Next, the output feature maps and score maps are aligned through the scale alignment module to overcome spatial misregistration among scales. Finally, the aligned score maps are fused with the help of adaptive weight maps generated by the adaptive fusion module, producing the fused prediction. The performance of MFVNet surpasses the previous state-of-the-art semantic segmentation models on three typical RSI datasets, demonstrating the effectiveness of the proposed MFVNet. [full text] [link]
-
Shunping Ji, Chang Zeng, , Yulin Duan, (2023) An evaluation of conventional and deep learning-based image-matching methods on diverse datasets. In: Photogrammetric Record, 2023, 38(182), 137-159.

Abstract: Image matching plays an important role in photogrammetry, computer vision and remote sensing. Modern deep learning-based methods have been proposed for image matching; however, whether they will surpass and take the place of the conventional handcrafted methods in the remote sensing field still remains unclear. A comprehensive evaluation on stereo remote sensing images is also lacking. This paper comprehensively evaluates the performance of conventional and deep learning-based image-matching methods by dividing the matching process into feature point extraction, description and similarity measure on various datasets, including images captured from close-range indoor and outdoor scenarios, unmanned aerial vehicles (UAVs) and satellite platforms. Different combinations of the three steps are evaluated. The experimental results reveal that, first, the performance of the different combinations varies between individual datasets, and it is difficult to determine the best combination. Second, by using more comprehensive indicators on all of the datasets, that is, the average rank and absolute rank, the combination of scale-invariant feature transform (SIFT), ContextDesc and the nearest neighbour distance ratio (NNDR), and also the original SIFT, achieve the best results, and are recommended for use in remote sensing. Third, the deep learning-based Sub-SuperPoint extractor obtains a good performance, and is second only to SIFT. The learning based ContextDesc descriptor is as effective as the SIFT descriptor, and the learning based SuperGlue matcher is not as stable as NNDR, but leads to a few top-performing combinations. Finally, the handcrafted methods are generally faster than the deep learning-based methods, but the efficiency of the latter is acceptable. We conclude that although a full deep learning-based method/combination has not yet beaten the conventional methods, there is still much room for improvement with the deep learning-based methods because large-scale aerial and satellite training datasets remain to be constructed, and specific methods for remote sensing images remain to be developed. The performance of the different combinations of feature extractor, descriptor and similarity measure varies between individual datasets. The combination of SIFT, ContextDesc and NNDR, and also the original SIFT, achieve the best results when using more comprehensive indicators on all the datasets. For extractor, the learning based Sub-SuperPoint is second only to SIFT; for descriptor, learning-based ContextDesc is as effective as the SIFT descriptor; and for matcher, learning-based SuperGlue is not as stable as NNDR. [full text] [link]
-
Ling Chen, Xing Tang, Weiqi Chen, Yuntao Qian, Yansheng Li, . (2022) DACHA: A Dual Graph Convolution Based Temporal Knowledge Graph Representation Learning Method Using Historical Relation. In: ACM Transactions on Knowledge Discovery from Data. 16(3): June 2022, pp 1-18.
Abstract: Temporal knowledge graph (TKG) representation learning embeds relations and entities into a continuous low-dimensional vector space by incorporating temporal information. Latest studies mainly aim at learning entity representations by modeling entity interactions from the neighbor structure of the graph. However, the interactions of relations from the neighbor structure of the graph are neglected, which are also of significance for learning informative representations. In addition, there still lacks an effective historical relation encoder to model the multi-range temporal dependencies. In this article, we propose a dual graph convolution network based TKG representation learning method using historical relations (DACHA). Specifically, we first construct the primal graph according to historical relations, as well as the edge graph by regarding historical relations as nodes. Then, we employ the dual graph convolution network to capture the interactions of both entities and historical relations from the neighbor structure of the graph. In addition, the temporal self-attentive historical relation encoder is proposed to explicitly model both local and global temporal dependencies. Extensive experiments on two event based TKG datasets demonstrate that DACHA achieves the state-of-the-art results. [full text] [link]
-
Jun Lu, Tao He, Shunlin Liang, . (2022) An Automatic Radiometric Cross-Calibration Method for Wide-Angle Medium-Resolution Multispectral Satellite Sensor Using Landsat Data. In:IEEE Transactions on Geoscience and Remote Sensing, 2022, 60.
Abstract: Radiometric calibration of the medium-resolution satellite data is critical for monitoring and quantifying changes in the Earth's environment and resources. Many medium-resolution satellite sensors have irregular revisits and, sometimes, have a large difference in illumination viewing geometry compared with a reference sensor, posing a great challenge for routine cross-calibration practices. To overcome these issues, this study proposed a cross-calibration method to calibrate medium-resolution multispectral data. The Chinese Gaofen-4 (GF-4) panchromatic and multispectral sensor (PMS) data with large viewing angles were used as the test data, and Landsat-8 operational land imager (OLI) data were used as the reference data. A bidirectional reflectance distribution function (BRDF) correction method was proposed to eliminate the effects of differences in illumination viewing geometry between GF-4 and Landsat-8. The validation using concurrent image shows that the mean relative error (MRE) of cross calibration is less than 6.65%. Validation using ground measurements shows that our calibration results have an improvement of around 14.8% compared with the official released calibration coefficients. The time series cross calibration reveals that, without the requirements of simultaneous nadir observations (SNOs), our calibration activities can be carried out more often in practice. Gradual and continuous radiometric sensor degradation is identified with the monthly updated calibration coefficients, demonstrating the reliability and importance of the timely cross calibration. Besides, the cross-calibration approach does not rely on any specific calibration site, and the difference in illumination viewing geometry can be well considered. Thus, it can be easily adapted and applied to other optical satellite data. [full text] [link]
-
, Siyuan Zou, Xinyi Liu, Xu Huang, Yi Wan, Yongxiang Yao. (2022) LiDAR-Guided Stereo Matching with a Spatial Consistency Constraint. In:ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 183, 164-177.

Abstract: The complementary fusion of light detection and ranging (LiDAR) data and image data is a promising but challenging task for generating high-precision and high-density point clouds. This study proposes an innovative LiDAR-guided stereo matching approach called LiDAR-guided stereo matching (LGSM), which considers the spatial consistency represented by continuous disparity or depth changes in the homogeneous region of an image. The LGSM first detects the homogeneous pixels of each LiDAR projection point based on their color or intensity similarity. Next, we propose a riverbed enhancement function to optimize the cost volume of the LiDAR projection points and their homogeneous pixels to improve the matching robustness. Our formulation expands the constraint scopes of sparse LiDAR projection points with the guidance of image information to optimize the cost volume of pixels as much as possible. We applied LGSM to semi-global matching and AD-Census on both simulated and real datasets. When the percentage of LiDAR points in the simulated datasets was 0.16%, the matching accuracy of our method achieved a subpixel level, while that of the original stereo matching algorithm was 3.4 pixels. The experimental results show that LGSM is suitable for indoor, street, aerial, and satellite image datasets and provides good transferability across semi-global matching and AD-Census. Furthermore, the qualitative and quantitative evaluations demonstrate that LGSM is superior to two state-of-the-art optimizing cost volume methods, especially in reducing mismatches in difficult matching areas and refining the boundaries of objects. [full text] [link]
-
Weiwei Song, Zhi Gao, Renwei Dian, Pedram Ghamisi, , Jon Atil Benediktsson. (2022) Asymmetric Hash Code Learning for Remote Sensing Image Retrieval. In:IEEE Transactions on Geoscience and Remote Sensing, 2022, 60, 5617514.
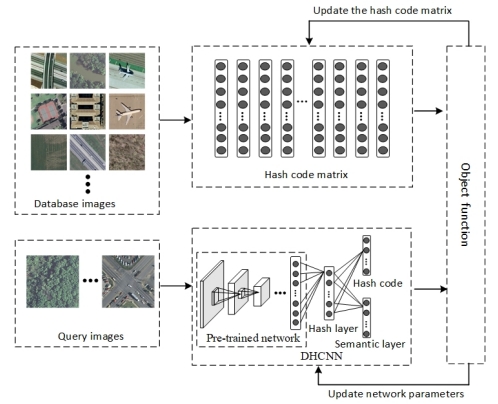
Abstract: Remote sensing image retrieval (RSIR), aiming at searching for a set of similar items to a given query image, is a very important task in remote sensing applications. Deep hashing learning as the current mainstream method has achieved satisfactory retrieval performance. On one hand, various deep neural networks are used to extract semantic features of remote sensing images. On the other hand, the hashing techniques are subsequently adopted to map the high-dimensional deep features to the low-dimensional binary codes. This kind of method attempts to learn one hash function for both the query and database samples in a symmetric way. However, with the number of database samples increasing, it is typically time-consuming to generate the hash codes of large-scale database images. In this article, we propose a novel deep hashing method, named asymmetric hash code learning (AHCL), for RSIR. The proposed AHCL generates the hash codes of query and database images in an asymmetric way. In more detail, the hash codes of query images are obtained by binarizing the output of the network, while the hash codes of database images are directly learned by solving the designed objective function. In addition, we combine the semantic information of each image and the similarity information of pairs of images as supervised information to train a deep hashing network, which improves the representation ability of deep features and hash codes. The experimental results on three public datasets demonstrate that the proposed method outperforms symmetric methods in terms of retrieval accuracy and efficiency. The source code is available at https://github.com/weiweisong415/Demo_AHCL_for_TGRS2022. [full text] [link]
-
Yongxiang Yao, , Yi Wan, Xinyi Liu, Xiaohu Yan, Jiayuan Li. (2022) Multi-Modal Remote Sensing Image Matching Considering Co-Occurrence Filter. In:IEEE Transactions on Image Processing, 2022, 31, 2584-2597.

Abstract: Traditional image feature matching methods cannot obtain satisfactory results for multi-modal remote sensing images (MRSIs) in most cases because different imaging mechanisms bring significant nonlinear radiation distortion differences (NRD) and complicated geometric distortion. The key to MRSI matching is trying to weakening or eliminating the NRD and extract more edge features. This paper introduces a new robust MRSI matching method based on co-occurrence filter (CoF) space matching (CoFSM). Our algorithm has three steps: (1) a new co-occurrence scale space based on CoF is constructed, and the feature points in the new scale space are extracted by the optimized image gradient; (2) the gradient location and orientation histogram algorithm is used to construct a 152-dimensional log-polar descriptor, which makes the multi-modal image description more robust; and (3) a position-optimized Euclidean distance function is established, which is used to calculate the displacement error of the feature points in the horizontal and vertical directions to optimize the matching distance function. The optimization results then are rematched, and the outliers are eliminated using a fast sample consensus algorithm. We performed comparison experiments on our CoFSM method with the scale-invariant feature transform (SIFT), upright-SIFT, PSO-SIFT, and radiation-variation insensitive feature transform (RIFT) methods using a multi-modal image dataset. The algorithms of each method were comprehensively evaluated both qualitatively and quantitatively. Our experimental results show that our proposed CoFSM method can obtain satisfactory results both in the number of corresponding points and the accuracy of its root mean square error. The average number of obtained matches is namely 489.52 of CoFSM, and 412.52 of RIFT. As mentioned earlier, the matching effect of the proposed method was significantly greater than the three state-of-art methods. Our proposed CoFSM method achieved good effectiveness and robustness. Executable programs of CoFSM and MRSI datasets are published: https://skyearth.org/publication/project/CoFSM/. [full text] [link]
-
Jiayuan Li, Wangyi Xu, Pengcheng Shi, , Qingwu Hu. (2022) LNIFT: Locally Normalized Image for Rotation Invariant Multimodal Feature Matching. In:IEEE Transactions on Geoscience and Remote Sensing, 2022, 60, 5621314.

Abstract: Severe nonlinear radiation distortion (NRD) is the bottleneck problem of multimodal image matching. Although many efforts have been made in the past few years, such as the radiation-variation insensitive feature transform (RIFT) and the histogram of orientated phase congruency (HOPC), almost all these methods are based on frequency-domain information that suffers from high computational overhead and memory footprint. In this article, we propose a simple but very effective multimodal feature matching algorithm in the spatial domain, called locally normalized image feature transform (LNIFT). We first propose a local normalization filter to convert original images into normalized images for feature detection and description, which largely reduces the NRD between multimodal images. We demonstrate that normalized matching pairs have a much larger correlation coefficient than the original ones. We then detect oriented FAST and rotated brief (ORB) keypoints on the normalized images and use an adaptive nonmaximal suppression (ANMS) strategy to improve the distribution of keypoints. We also describe keypoints on the normalized images based on a histogram of oriented gradient (HOG), such as a descriptor. Our LNIFT achieves rotation invariance the same as ORB without any additional computational overhead. Thus, LNIFT can be performed in near real-time on images with 1024 times 1024 pixels (only costs 0.32 s with 2500 keypoints). Four multimodal image datasets with a total of 4000 matching pairs are used for comprehensive evaluations, including synthetic aperture radar (SAR)-optical, infrared-optical, and depth-optical datasets. Experimental results show that LNIFT is far superior to RIFT in terms of efficiency (0.49 s versus 47.8 s on a 1024 times 1024 image), success rate (99.9% versus 79.85%), and number of correct matches (309 versus 119). The source code and datasets will be publicly available at https://ljy-rs.github.io/web. [full text] [link]
-
Hong Ji, Zhi Gao, , Yu Wan, Can Li, Tiancan Mei. (2022) Few-Shot Scene Classification of Optical Remote Sensing Images Leveraging Calibrated Pretext Tasks. In:IEEE Transactions on Geoscience and Remote Sensing, 2022, 60, 5625513.
Abstract: Small data hold big artificial intelligence (AI) potential. As one of the promising small data AI approaches, few-shot learning has the goal to learn a model efficiently that can recognize novel classes with extremely limited training samples. Therefore, it is critical to accumulate useful prior knowledge obtained from large-scale base class dataset. To realize few-shot scene classification of optical remote sensing images, we start from a baseline model that trains all base classes using a standard cross-entropy loss leveraging two auxiliary objectives to capture intrinsical characteristics across the semantic classes. Specifically, rotation prediction learns to recognize the 2-D rotation of an input to guide the learning of class-transferable knowledge, and contrastive learning aims to pull together the positive pairs while pushing apart the negative pairs to promote intraclass consistency and interclass inconsistency. We jointly optimize two such pretext tasks and semantic class prediction task in an end-to-end manner. To further overcome the overfitting issue, we introduce a regularization technique, adversarial model perturbation, to calibrate the pretext tasks so as to enhance the generalization ability. Extensive experiments on public remote sensing benchmarks including Northwestern Polytechnical University (NWPU)-RESISC45, aerial image dataset (AID), and Wuhan University (WHU)-remote sensing (RS)-19 demonstrate that our method works effectively and achieves best performance that significantly outperforms many state-of-the-art approaches. [full text] [link]
-
Bin Zhang, , Yansheng Li, Yi Wan, Haoyu Guo, Zhi Zheng, Kun Yang. (2022) Semi-Supervised Deep Learning via Transformation Consistency Regularization for Remote Sensing Image Semantic Segmentation. In:IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022.
Abstract: Deep convolutional neural networks (CNNs) have gotten a lot of press in the last several years, especially in domains like computer vision (CV) and remote sensing (RS). However, achieving superior performance with deep networks highly depends on a massive amount of accurately labeled training samples. In real-world applications, gathering a large number of labeled samples is time-consuming and labor-intensive, especially for pixel-level data annotation. This dearth of labels in land-cover classification is especially pressing in the RS domain because high-precision, high-quality labeled samples are extremely difficult to acquire, but unlabeled data is readily available. In this study, we offer a new semi-supervised deep semantic labeling framework for semantic segmentation of high-resolution RS images to take advantage of the limited amount of labeled examples and numerous unlabeled samples. Our model uses transformation consistency regularization (TCR) to encourage consistent network predictions under different random transformations or perturbations. We try three different transforms to compute the consistency loss and analyze their performance. Then, we present a deep semi-supervised semantic labeling technique by using a hybrid transformation consistency regularization (HTCR). A weighted sum of losses, which contains a supervised term computed on labeled samples and an unsupervised regularization term computed on unlabeled data, may be used to update the network parameters in our technique. Our comprehensive experiments on two RS datasets confirmed that the suggested approach utilized latent information from unlabeled samples to obtain more precise predictions and outperformed existing semi-supervised algorithms in terms of performance. Our experiments further demonstrated that our semi-supervised semantic labeling strategy has the potential to partially tackle the problem of limited labeled samples for high-resolution RS image land-cover segmentation. [full text] [link]
-
Zhi Zheng, Yi Wan,, Kun Yang, Rang Xiao, Chao Lin, Qiong Wu, Daifeng Peng. (2022) EMS-CDNet: an Efficient Multi-Scale-Fusion Change Detection Network for very High-resolution Remote Sensing Images. In:International Journal of Remote Sensing, 2022, 43(14), 5252-5279.
Abstract: Remote sensing image change detection (RSICD) is an essential measure for monitoring the earth's surface changes. In recent years, the explosive growth of very high-resolution (VHR) satellite sensors and the booming innovations in deep learning technology have significantly boosted RSICD development. However, most of the current RSICD models focus on locating accurate change areas while ignoring the efficiency of their method, which limits the practical application of RSICD models, especially for large-scale and emergency RSICD tasks. In this paper, we propose an Efficient Multi-scale-fusion Change Detection Network (EMS-CDNet) for bi-temporal RSICD tasks. Our EMS-CDNet pays more attention to the model's inference speed and the accuracy-efficiency trade-off rather than only pursuing detection accuracy. We designed a multi-scale fusion module for EMS-CDNet, which adopts multi-scale and multi-branch operations to extract multi-scale features simultaneously and aggregate features at different feature levels. In addition to EMS-CDNet's ability to achieve sufficient feature extraction, the multi-scale image input within the designed module alleviates the influence of image registration errors in practical applications, thereby strengthening EMS-CDNet's value for practical RSICD tasks. We also integrated a novel partition unit in EMS-CDNet to lighten the model while maintaining the detection ability of small targets, thus shortening its processing time without a severe accuracy decrease. We conducted experiments on two state-of-the-art (SOTA) public RSICD datasets and our own collected dataset. The public datasets were utilized to comparatively measure the overall accuracy and efficiency measurement of EMS-CDNet, and the dataset of images we collected was used to observe EMS-CDNet's performance under the influence of image registration errors. Our experimental results show that EMS-CDNet achieved a better accuracy-efficiency trade-off than the SOTA public datasets methods. For example, EMS-CDNet reduced the inference time by about 33% while maintaining identical detection accuracy to CLNet (the optimal method among the comparison methods). Furthermore, EMS-CDNet achieved higher accuracy on our collected dataset, with an F1 of 74% and mIoU of 0.806, demonstrating its robustness to image registration errors and showing its value for practical RSICD applications. [full text] [link]
-
Wenke Jiao, , Bin Zhang, Yi Wan. (2022) SCTRANS: A Transformer Network Based on the Spatial and Channel Attention for Cloud Detection. In:International Geoscience and Remote Sensing Symposium (IGARSS), 2022, 2022-July, 615-618.
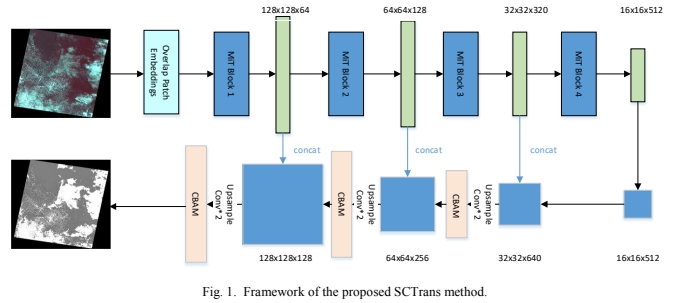
Abstract: Cloud detection is an important preprocessing step for remote sensing image processing and analysis. The current deep-learning-based cloud detection methods are mostly based on Convolutional Neural Network (CNN) which pay more attention to local information. To make more use of the global information, in this article, we propose a transformer-based cloud detection method (SCTrans) based on the spatial and channel attention mechanism. The experiment results show that when using only three-band images on the Landsat7 dataset, the mIoU of the validation set reaches 85.92% and the mIoU of the test set reaches 87.86%. The experimental results show that the proposed network has a higher mIoU and F1 score than Fmask and other networks. [full text] [link]
-
Weiwei Song, Zhi Gao, . (2022) Discriminative Feature Extraction and Fusion for Classification of Hyperspectral and Lidar Data. In:International Geoscience and Remote Sensing Symposium (IGARSS), 2022, 2022-July, 2271-2274.
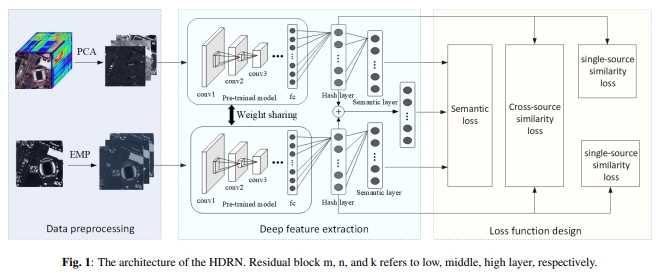
Abstract: Multisource remote sensing data provide the abundant and complementary information for land cover classification. In this paper, we propose a deep hashing-based feature extraction and fusion framework for joint classification of hyper-spectral and LiDAR data. Firstly, HSIs and LiDAR data are fed into a two-stream network to extract deep features after data preprocessing. Then, we adopt hashing technique to constrain single-source and cross-source similarities, i.e., samples with same classes should have small feature distance and samples with different classes should have large feature distance. Furthermore, a feature-level fusion strategy is exploited to fuse the two kind of multisource information. Finally, we design an object function to consider the similarity information between sample pairs and semantic information of each sample, which can deliver the discriminative features for classification. The experiments on Houston data demonstrate the effectiveness of the proposed method over some competitive approaches. [full text] [link]
-
Bin Zhang, Yi Wan, , Yansheng Li. (2022) JSH-Net: Joint Semantic Segmentation and Height Estimation using Deep Convolutional Networks from Single High-resolution Remote Sensing Imagery. In:International Journal of Remote Sensing, 2022, 43(17), 6307-6332.

Abstract: Semantic segmentation for high-resolution remote sensing imagery is a pivotal component of land use and land cover categorization, and height estimation is essential for rebuilding the 3D information of an image. Because of the higher intra-class variation and smaller inter-class dissimilarity, these two challenging tasks are generally treated separately. This paper proposes a fully convolutional network that can tackle these problems simultaneously by estimating the land-cover categories and height values of pixels from a single aerial image. To handle these tasks, we develop a multi-task learning architecture (JSH-Net) that employs a shared feature representation and exploits their potential consistency across tasks, resulting in robust features and better prediction accuracy. Specifically, we propose a novel skip connection module that aggregates the contexts from the encoder part to the decoder part, bridging the semantic gap between them. In addition, we propose a progressive refinement strategy to recover detailed information about the objects. Moreover, we also proposed a height estimation branch on the head of the model to utilize shared features. The experiments we conducted on ISPRS 2D Labelling dataset verified that our network provided precise results of semantic segmentation and height estimation from two output branches and outperformed other state-of-the-art approaches. [full text] [link]
-
Youming Deng, Yansheng Li, , Xiang Xiang, Jian Wang, Jingdong Chen, Jiayi Ma. (2022) Hierarchical Memory Learning for Fine-Grained Scene Graph Generation. In:Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2022, 13687 LNCS, 266-283.
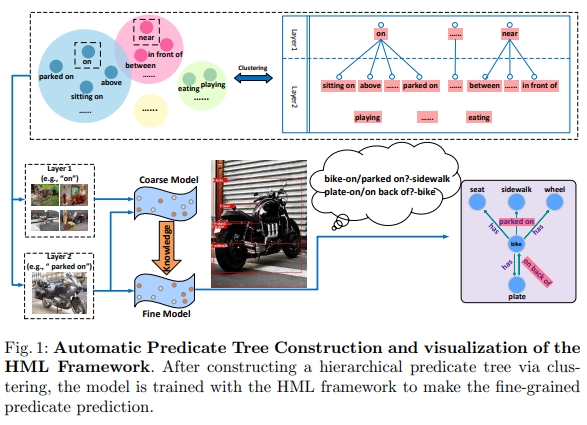
Abstract: Regarding Scene Graph Generation (SGG), coarse and fine predicates mix in the dataset due to the crowd-sourced labeling, and the long-tail problem is also pronounced. Given this tricky situation, many existing SGG methods treat the predicates equally and learn the model under the supervision of mixed-granularity predicates in one stage, leading to relatively coarse predictions. In order to alleviate the impact of the suboptimum mixed-granularity annotation and long-tail effect problems, this paper proposes a novel Hierarchical Memory Learning (HML) framework to learn the model from simple to complex, which is similar to the human beings' hierarchical memory learning process. After the autonomous partition of coarse and fine predicates, the model is first trained on the coarse predicates and then learns the fine predicates. In order to realize this hierarchical learning pattern, this paper, for the first time, formulates the HML framework using the new Concept Reconstruction (CR) and Model Reconstruction (MR) constraints. It is worth noticing that the HML framework can be taken as one general optimization strategy to improve various SGG models, and significant improvement can be achieved on the SGG benchmark. [full text] [link]
-
Wangshan Yang, Xinyi Liu, , Yi Wan, Zheng Ji. (2022) Object Based Building Instance Segmentation from Airborne LiDAR Point Clouds. In:International Journal of Remote Sensing, 2022, 43(18), 6783-6808.
Abstract: DBuilding instance segmentation is of very importance to parallel reconstruction, management and analysis of building instance. Previous studies of building instance segmentation mainly focused on the building scenes where the building spacing is much larger than the point spacing, while the accuracy of building instance segmentation for complex buildings scenes and the building point clouds where the space between buildings is similar with point spacing is low. To improve the accuracy of building instance segmentation for complex building scenes, we propose a novel object-based building instance segmentation (OBBIS) method from airborne light detection and ranging (LiDAR) point clouds. Firstly, our proposed method divides building point clouds into objects, and then the objects are classified according to the characteristics of building roof plane objects, roof accessory objects and building facade objects. Secondly, we use node to represent object and then a fix-size feature vector is inferred for each node. Thirdly, vertical cylinder neighbour node graph is constructed. Finally, the energy function is constructed according to the relationship between the nodes, and then the objects are merged according to the energy minimum (that is, objects are merged with a minimum energy to obtain the building instances). Comprehensive experiments on benchmark datasets demonstrate that the proposed OBBIS method performs better than eight state-of-the-art building instance segmentation methods. [full text] [link]
-
Ling Chen, Jun Cui,Xing Tang, Yuntao Qian, Yansheng Li, . (2022) RLPath: A Knowledge Graph Link Prediction Method using Reinforcement Learning based Attentive Relation Path Searching and Representation Learning. In:Applied Intelligence, 2022, 52(4), 4715-4726.

Abstract: Due to containing rich patterns between entities, relation paths have been widely used in knowledge graph link prediction. The state-of-the-art link prediction methods considering relation paths obtain relation paths by reinforcement learning with an untrainable reward setting, and realize link prediction by path-ranking algorithm (PRA), which ignores information in entities. In this paper, we propose a new link prediction method RLPath to employ information in both relation paths and entities, which alternately trains a reinforcement learning model with a trainable reward setting to search high-quality relation paths, and a translation-based model to realize link prediction. Simultaneously, we propose a novel reward setting for the reinforcement learning model, which shares the parameters with the attention of the translation-based model, so that these parameters can not only measure the contributions of relation paths, but also guide agents to search relation paths that have high contributions for link prediction, forming mutual promotion. In experiments, we compare RLPath with the state-of-the-art link prediction methods. The results show that RLPath has competitive performance. [full text] [link]
-
Jiayuan Li, Qingwu Hu, , Mingyao Ai. (2022) Robust Symmetric Iterative Closest Point. In:ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 185, 219-231.

Abstract: Point cloud registration (PCR) is an important technique of 3D vision, which has been widely applied in many areas such as robotics and photogrammetry. The iterative closest point (ICP) is a de facto standard for PCR. However, it mainly suffers from two drawbacks: small convergence basin and the sensitivity to outliers and partial overlaps. In this paper, we propose a robust symmetric ICP (RSICP) to tackle these drawbacks. First, we present a new symmetric point-to-plane distance metric whose functional zero-set is a set of locally-second-order surfaces. It has a wider convergence basin and higher convergence speed than the point-to-point metric, point-to-plane metric, and even original symmetric metric. Second, we introduce an adaptive robust loss to construct our robust symmetric metric. This robust loss bridges the gap between the non-robust ℓ2 cost and robust M-estimates. In the optimization, we gradually improve the degrees of robustness via the decay of a robustness control parameter. This loss has a high “breakdown” point or low computational overhead compared with recent work (e.g., Sparse ICP and Robust ICP). We also present a simple but effective linearization for the alignment function based on Rodrigues rotation parameterization with the small incremental rotation assumption. Extensive experiments on challenging datasets with noise, outliers or partial overlaps show that the proposed algorithm significantly outperforms Sparse ICP and Robust ICP in terms of both accuracy and efficiency. Our source code will be publicly available in https://ljy-rs.github.io/web. [full text] [link]
-
Yansheng Li, Yuhan Zhou, , Liheng Zhang, Jian Wang, Jingdong Chen. (2022) DKDFN: Domain Knowledge-Guided Deep Collaborative Fusion Network for Multimodal Unitemporal Remote Sensing Land Cover Classification. In:ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 186, 170-189.

Abstract: Land use and land cover maps provide fundamental information that has been used in different types of studies, ranging from public health to carbon cycling. However, the existing remote sensing image classification methods thus far suffer from the insufficient usage of multiple modalities, underconsideration of prior domain knowledge, and poor performance on minority classes. To alleviate these problems, we propose a novel domain knowledge-guided deep collaborative fusion network (DKDFN) with performance boosting for minority categories for land cover classification. More specifically, the DKDFN adopts a multihead encoder and a multibranch decoder structure. The architecture of the encoder probablizes sufficient mining of complementary information from multiple modalities, which are Sentinel-2, Sentinel-1, and SRTM Digital Elevation Data (SRTM) in our case. The multibranch decoder enables land cover classification in a multitask learning setup, performing semantic segmentation and reconstructing multimodal remote sensing indices, which are selected as representatives of domain knowledge. This design incorporates domain knowledge in an effective end-to-end manner. The training stage of our DKDFN is supervised by our proposed asymmetry loss function (ALF), which boosts performance on nearly all categories, especially the categories with a low frequency of occurrence. Ablation studies of the network suggest that our design logic is worth testing in any network with an encoder-decoder structure. The study is conducted in Hunan, China and is verified using a self-labeled multimodal unitemporal remote sensing image dataset. The comparative experiments between DKDFN and 6 state-of-the-art models (U-Net, SegNet, PSPNet, DeepLab, HRNet, MP-ResNet) testify to the superiority of our method and suggest its potential to be applied more widely to map land cover in other geographical areas given the availability of Sentinel-2, Sentinel-1, and SRTM data. The dataset can be downloaded by https://github.com/LauraChow/HunanMultimodalDataset. [full text] [link]
-
Yansheng Li, Bo Dang, , Zhenhong Du. (2022) Water Body Classification from High-Resolution Optical Remote Sensing Imagery: Achievements and Perspectives. In:ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 187, 306-327.
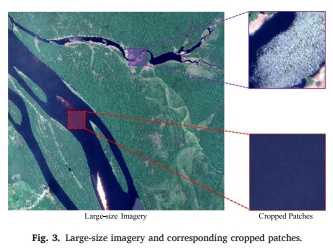
Abstract: Water body classification from high-resolution optical remote sensing (RS) images, aiming at classifying whether each pixel of the image is water or not, has become a hot issue in the area of RS and has extensive practical applications in a variety of fields. Numerous existing methods have drawn broad attention and achieved remarkable advancements, meanwhile, serious challenges and potential opportunities also exist, which deserves in thinking and discussing deeply. By taking into account the comprehensive survey is still lacking, through the compilation of approximately 200 papers, this paper summarizes and analyzes the achievements, and discusses the perspectives of future research directions. Specifically, we first analyze 5 challenges according to the characteristics of water bodies in high-resolution optical RS imagery, and 5 corresponding significant opportunities combined with advanced deep learning techniques are discussed to respond mentioned challenges. Then, we divide the existing methods into several groups in light of their core ideas and introduce them chiefly. In addition, some practical applications and publicly open benchmarks are listed intuitively. 10 and 9 representative methods are implemented on two widely used datasets to assess their performance, respectively. To facilitate the qualitative and quantitative comparison in the research avenue, the two benchmarks employed in the comparative experiments and links to other relevant datasets and open-source codes will be summarized and released in https://github.com/Jack-bo1220/Benchmarks-for-Water-Body-Extraction-from-HRORS-Imagery. Finally, we discuss a range of promising research directions to provide some references and inspiration for the following research. The studies of our paper, including the existing methods, challenges, opportunities, derived applications, and future research directions, provide a fuller understanding of water body classification from high-resolution optical remote sensing imagery. [full text] [link]
-
Yansheng Li, Song Ouyang, . (2022) Combining Deep Learning and Ontology Reasoning for Remote Sensing Image Semantic Segmentation. In:Knowledge-Based Systems, 2022, 243, 108469.

Abstract: Because of its wide potential applications, remote sensing (RS) image semantic segmentation has attracted increasing research interest in recent years. Until now, deep semantic segmentation network (DSSN) has achieved a certain degree of success on semantic segmentation of RS imagery and can obviously outperform the traditional methods based on hand-crafted features. As a classic data-driven technique, DSSN can be trained by an end-to-end mechanism and is competent for employing low-level and mid-level cues (i.e., the discriminative image structure) to understand RS images. However, its interpretability and reliability are poor due to the nature weakness of the data-driven deep learning methods. By contrast, human beings have an excellent inference capacity and can reliably interpret RS imagery with the basic RS domain knowledge. Ontological reasoning is an ideal way to imitate and employ the domain knowledge of human beings. However, it is still rarely explored and adopted in the RS domain. As a solution of the aforementioned critical limitation of DSSN, this study proposes a collaboratively boosting framework (CBF) to combine the data-driven deep learning module and knowledge-guided ontology reasoning module in an iterative manner. The deep learning module adopts the DSSN architecture and takes the integration of the original image and inferred channels as the input of the DSSN. In addition, the ontology reasoning module is composed of intra- and extra-taxonomy reasoning. More specifically, the intra-taxonomy reasoning directly corrects misclassifications of the deep learning module based on the domain knowledge, which is the key to improve the classification performance. The extra-taxonomy reasoning aims to generate the inferred channels beyond the current taxonomy to improve the discriminative performance of DSSN in the original RS image space. On the one hand, benefiting from the referred channels from the ontology reasoning module, the deep learning module using the integration of the original image and referred channels can achieve better classification performance than only using the original image. On the other hand, better classification results from the deep learning module further improve the performance of the ontology reasoning module. As a whole, the deep learning and ontology reasoning modules are mutually boosted in the iterations. Extensive experiments on two publicly open RS datasets such as UCM and ISPRS Potsdam show that our proposed CBF can outperform the competitive baselines with a large margin. [full text] [link]
-
Fei Wang, Yansheng Li, , Dong Wei. (2022) KLGCN: Knowledge Graph-aware Light Graph Convolutional Network for recommender systems. In:Expert Systems with Applications, 2022, 195, 116513.
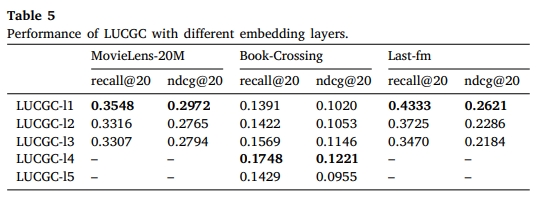
Abstract: Most popular recommender systems learn the embedding of users and items through capturing valuable information from user-item interactions or item knowledge graph (KG) with Graph Convolutional Network. However, only a few methods capture information from both source data, and they introduce many trainable parameters that increase training difficulty. In this work, we aim to aggregate information from both the user-item interaction graph and the item KG in a light and effective manner. We first experimentally verify the effectiveness of removing feature transformation and nonlinear activation in KG-aware recommendation, which has been proven to greatly reduce parameters while improving performance in the collaborative filtering-based recommendation. Then we propose a new Knowledge graph-aware Light Graph Convolutional Network (KLGCN), which can learn partial embeddings of users and items by aggregating features on the source graphs for recommendation and introduces no extra parameters. Extensive experiments on three public datasets demonstrate that KLGCN achieves substantial improvement over several state-of-the-art models and maintains satisfactory performance on cold-start scenarios. [full text] [link]
-
Yansheng Li, . (2022) A New Paradigm of Remote Sensing Image Interpretation by Coupling Knowledge Graph and Deep Learning | 耦合知识图谱和深度学习的新一代遥感影像解译范式. In: Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomatics and Information Science of Wuhan University, 2022, 47(8), 1176-1190.
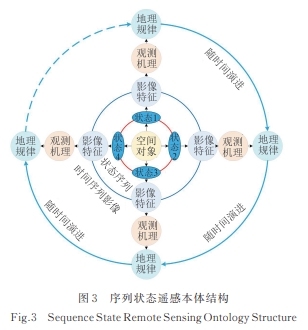
Abstract: Objectives In the remote sensing (RS) big data era, intelligent interpretation of remote sensing images (RSI) is the key technology to mine the value of big RS data and promote several important applications. Traditional knowledge-driven RS interpretation methods, represented by expert systems, are highly interpretable, but generally show poor performance due to the interpretation knowledge being difficult to be completely and accurately expressed. With the development of deep learning in computer vision and other fields, it has gradually become the mainstream technology of RSI interpretation. However, the deep learning technique still has some fatal flaws in the RS field, such as poor interpretability and weak generalization ability. In order to overcome these problems, how to effectively combine knowledge inference and data learning has become an important research trend in the field of RS big data intelligent processing. Generally, knowledge inference relies on a strong domain knowledge base, but the research on RS knowledge graph (RS-KG) is very scarce and there is no available large-scale KG database for RSI interpretation now. Methods To overcome the above considerations, this paper focuses on the construction and evolution of the RS-KG for RSI interpretation and establishes the RS-KG takes into account the RS imaging mechanism and geographic knowledge. Supported by KG in the RS field, this paper takes three typical RSI interpretation tasks, namely, zero-shot RSI scene classification, interpretable RSI semantic segmentation, and large-scale RSI scene graph generation, as examples, to discuss the performance of the novel generation RSI interpretation paradigm which couples KG and deep learning. Results and Conclusions A large number of experimental results show that the combination of RS-KG inference and deep data learning can effectively improve the performance of RSI interpretation.The introduction of RS-KG can effectively improve the interpretation accuracy, generalization ability, anti-interference ability, and interpretability of deep learning models. These advantages make RS-KG promising in the novel generation RSI interpretation paradigm. [full text] [link]
-
Weiyu Liu, Yi Wan, . (2022) An Efficient Matching Method of LiDAR Depth Map and Aerial Image Based on Phase Mean Convolution | 基于相位均匀卷积的LiDAR深度图与航空影像高效匹配方法. In: Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomatics and Information Science of Wuhan University, 2022, 47(8), 1309-1317.
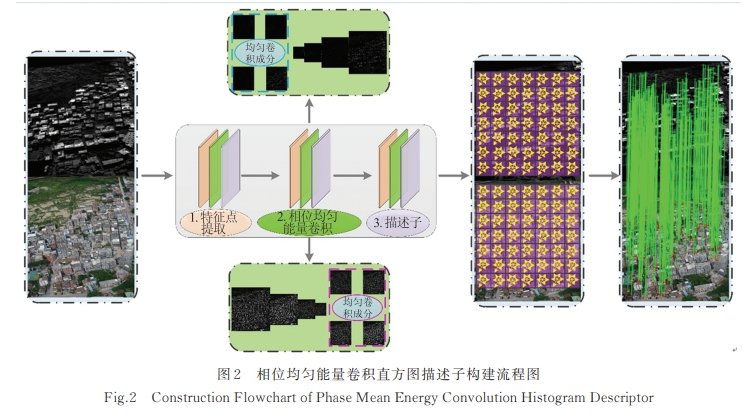
Abstract: Objectives Multi-source image matching is primarily disturbed by nonlinear intensity difference, contrast difference and inconspicuous regional structure features, while the significant differences of texture features result in lack of part structure seriously between light detection and ranging(LiDAR)depth map and aerial image, and this problem causes a mutation in the phase extremum, which further increases the difficulty of matching. Methods In this paper, a method of efficient matching of LiDAR depth map and aerial image based on phase mean convolution is proposed. In the image feature matching stage, a histogram of phase mean energy convolution(HPMEC) is established, which extended the phase consistency model in order to solve a mean convolution sequence and phase maximum label map by constructing phase mean energy convolution equation. Then the nearest neighbor matching algorithm was completed the initial match and marginalizing sample consensus plus was used to remove outliers. Based on the thread pool parallel strategy, the images were matched by dividing the overlapping grid. Multiple sets of LiDAR depth map and aerial image with different types of ground coverage are used to as dataset to experiment with position scale orientation-scale invariant feature transform (PSO-SIFT), Log-Gabor histogram descriptor (LGHD), radiation-variation insensitive feature transform (RIFT) and histogram of absolute phase consistency gradients (HAPCG) methods respectively. Results The results show that the performance of HPMEC method is superior to the other four methods in the matching of LiDAR depth map and aerial image, the average running time is 13.3 times of PSO-SIFT, 10.9 times of LGHD, 10.4 times of HAPCG and 7.0 times of RIFT, at the same time the average correct matching points are significantly higher than the other four methods, the root mean square error is lightly better than the other four methods within 1.9 pixels. Conclusions The proposed HPMEC method could achieve efficient and robust matching between LiDAR depth map and aerial image. [full text] [link]
-
, Xin Cheng,Yansheng Li. (2022) Research on Land and Resources Management and Retrieval Using Knowledge Graph | 利用知识图谱的国土资源数据管理与检索研究. In: Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomatics and Information Science of Wuhan University, 2022, 47(8), 1165-1175.
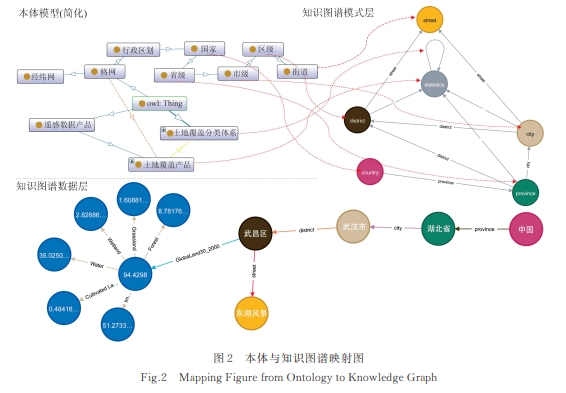
Abstract: Objectives Aiming at the problem of difficult effective management and rapid application between different data products of land and resources, the study uses the graph database to store the public land cover datasets, including GlobaLand30, FROM-GLC10_2017, GLC_FCS30_2020, etc., on the semantic level to establish a knowledge graph of land resources. It provides a new processing framework for the management, rapid application, and data quality assessment of land and resources data. Methods A new application framework for land cover data product management, knowledge extraction, and data acquisition and update based on administrative divisions is proposed. Anomaly data retrieval algorithms based on graphs are used to explore the consistency of different products, and a knowledge-based fast retrieval algorithm for graph nodes of interest (GNOI) in the graph. Results Through the introduction of the knowledge graph, a dynamically updateable nationwide land resource knowledge graph containing 447 817 nodes and 447 816 relationships has been formed, and it is found that the data accuracy of 92 units may have large errors in the 2 875 administrative units covering the whole country. Conclusions The research has greatly improved the utilization rate of multi-source land cover data products, shortened the time of data preprocessing for researchers, and provided new ideas for the knowledge management and application of land resources. [full text] [link]
-
Liang-jian Deng, Gemine Vivone, Mercedes E.Paoletti, Giuseppe Scarpa, Jiang He, . (2022) Machine Learning in Pansharpening: A Benchmark, from Shallow to Deep Networks. In: IEEE Geoscience and Remote Sensing Magazine, 2022, 10(3), 279-315.
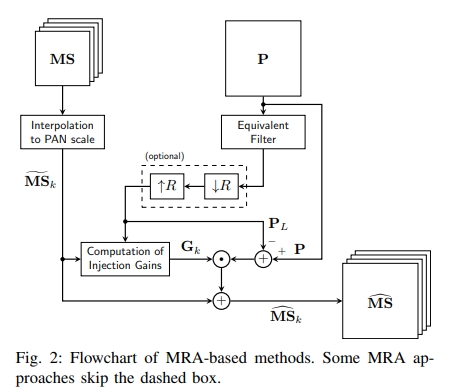
Abstract: Machine learning (ML) is influencing the literature in several research fields, often through state-of-the-art approaches. In the past several years, ML has been explored for pansharpening, i.e., an image fusion technique based on the combination of a multispectral (MS) image, which is characterized by its medium/low spatial resolution, and higher-spatial-resolution panchromatic (PAN) data. Thus, ML for pansharpening represents an emerging research line that deserves further investigation. In this article, we go through some powerful and widely used ML-based approaches for pansharpening that have been recently proposed in the related literature. Eight approaches are extensively compared. Implementations of these eight methods, exploiting a common software platform and ML library, are developed for comparison purposes. The ML framework for pansharpening will be freely distributed to the scientific community. Experimental results using data acquired by five commonly used sensors for pansharpening and well-established protocols for performance assessment (both at reduced resolution and at full resolution) are shown. The ML-based approaches are compared with a benchmark consisting of classical and variational optimization (VO)-based methods. The pros and cons of each pansharpening technique, based on the training-by-examples philosophy, are reported together with a broad computational analysis. The toolbox is provided in https://github.com/liangjiandeng/DLPan-Toolbox. [full text] [link]
-
Yongtao Yu, Long Huang, Weibin Lu, Haiyan Guan, Lingfei Ma, Shenghua Jin, Changhui Yu, , Peng Tang, Zuojun Liu, Wenhao Wang, Jonathan Li. (2022) WaterHRNet: A Multibranch Hierarchical Attentive Network for Water Body Extraction with Remote Sensing Images. In: International Journal of Applied Earth Observation and Geoinformation, 2022, 115, 103103.
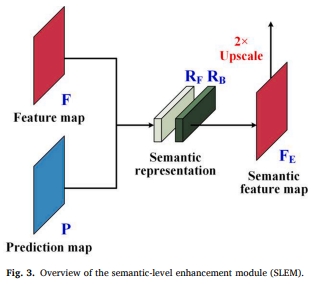
Abstract: Water is a kind of vital natural resource, which acts as the lifeblood of the ecosystem and the energy source for the living and production activities of humans. Regularly mapping the conditions of water resources and taking effective measures to prevent them from pollutions and shortages are very important and necessary to maintain the sustainability of the ecosystem. As a preliminary step for image-based water resource analysis, the complete recognition and accurate extraction of water bodies are important prerequisites in many applications. Nevertheless, due to the issues of topology diversities, appearance variabilities, and land cover interferences, there is still a large gap to achieve the human-level water bodies interpretation quality. This paper presents a hierarchical attentive high-resolution network, abbreviated as WaterHRNet, for extracting water bodies from remote sensing imagery. First, by building a multibranch high-resolution feature extractor integrated with global feature semantics aggregation, the WaterHRNet behaves laudably to supply high-quality, strong-semantic feature representations. Furthermore, by inlaying an effective feature attention scheme with the comprehensive exploitation of both the spatial and channel feature significances, the WaterHRNet is forced to strengthen the semantic-determinate, task-aware feature encodings. In addition, by designing a hierarchical processing principle with the progressive enhancement of category-attentive feature semantics, the WaterHRNet performs effectively to export semantic-discriminative, target-oriented feature representations for precise water body segmentation. The WaterHRNet is elaborately verified both quantitatively and qualitatively on three remote sensing datasets. Evaluation results show that the WaterHRNet achieves an average precision of 98.44%, average recall of 97.84%, average IoU of 96.35%, and average F1-score of 98.14%. Comparative analyses also demonstrate the superior performance and excellent feasibility of the WaterHRNet in segmenting water bodies. [full text] [link]
-
Zhiyong Peng, Jun Wu, , Xianhua Lin. (2021) A High Speed Feature Matching Method of High Resolution Aerial Images. In: Journal of Real-Time Image Processing, 18: 705-722.
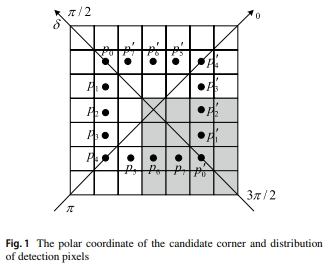
Abstract: This paper presents a novel corner detection and scale estimation algorithm for image feature description and matching. Inspired by Adaboost's weak classifier, a series of sub-detectors is elaborately designed to obtain reliable corner pixels. The new corner detection algorithm is more robust than the FAST and HARRIS algorithm, and it is especially suitable for the implementation in FPGA. The new scale estimation method can be directly implemented in the original image without building Gaussian pyramid and searching max response value in each level, which not only increase computational efficiency but also greatly reduces memory requirement. Based on the proposed algorithm, a CPU-FPGA cooperative parallel processing architecture is presented. The architecture overcomes the memory space limitation of FPGA and achieves high-speed feature matching for massive high-resolution aerial images. The speed of the CPU-FPGA cooperative process is hundred times faster than SIFT algorithm running on CPU, and dozens of times faster than SIFT running in CPU + GPU system. [full text] [link]
-
Yameng Wang, Shunping Ji, . (2021) A Learnable Joint Spatial and Spectral Transformation for High Resolution Remote Sensing Image Retrieval. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14: 8100-8112.
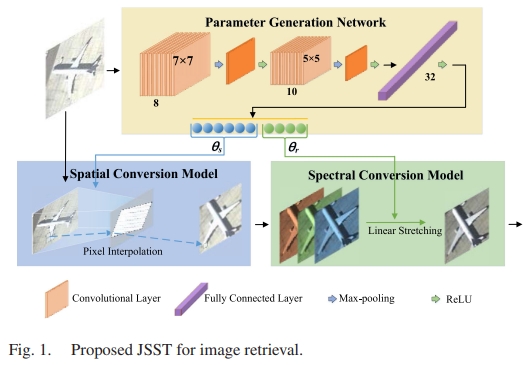
Abstract: Geometric and spectral distortions of remote sensing images are key obstacles for deep learning-based supervised classification and retrieval, which are worsened by cross-dataset applications. A learnable geometric transformation model imbedded in a deep learning model has been used as a tool for handling geometric distortions to process close-range images with different view angles. However, a learnable spectral transformation model, which is more noteworthy in remote image processing, has not yet been designed and explored up to now. In this paper, we propose a learnable joint spatial and spectral transformation (JSST) model for remote sensing image retrieval (RSIR), which is composed of three modules: a parameter generation network (PGN); a spatial conversion module; and a spectral conversion module. The PGN adaptively learns the geometric and spectral transformation parameters simultaneously from the different input image content, and these parameters then guide the spatial and spectral conversions to produce a new modified image with geometric and spectral correction. Our learnable JSST is imbedded in the front-end of the deep-learning-based retrieval network. The spatial and spectral-modified inputs provided by the JSST endow the retrieval network with better generalization and adaptation ability for cross-dataset RSIR. Our experiments on four open-source RSIR datasets confirmed that our proposed JSST embedded retrieval network outperformed state-of-the-art approaches comprehensively. [full text] [link]
-
Xianzhang Zhu, Xinyi Liu, , Yi Wan, Yansong Duan. (2021) Robust 3D Plane Segmentation from Airborne Point Clouds based on Quasi-A-Contrario Theory. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14: 7133-7147.
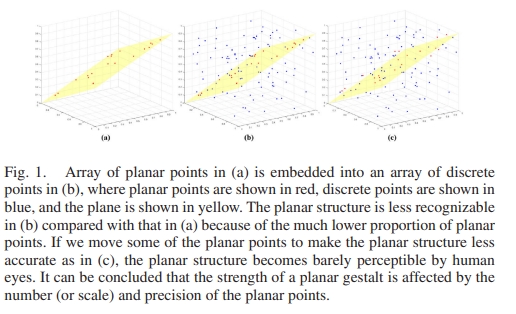
Abstract: Three-dimensional (3-D) plane segmentation has been and continues to be a challenge in 3-D point cloud processing. The current methods typically focus on the planar subsets separation but ignore the requirement of the precise plane fitting. We propose a quasi-a-contrario theory-based plane segmentation algorithm, which is capable of dealing with point clouds of severe noise level, low density, and high complexity robustly. The main proposition is that the final plane can be composed of basic planar subsets with high planar accuracy. We cast planar subset extraction from the point set as a geometric rigidity measuring problem. The meaningfulness of the planar subset is estimated by the number of false alarms (NFA), which can be used to eliminate false-positive effectively. Experiments were conducted to analyze both the planar subset extraction and the 3-D plane segmentation. The results show that the proposed algorithms perform well in terms of accuracy and robustness compared with state-of-art methods. Experimental datasets, results, and executable program of the proposed algorithm are available at https://skyearth.org/publication/project/QTPS. [full text] [link]
-
Shunping Ji, Peiyu Dai, Meng Lu, . (2021) Simultaneous Cloud Detection and Removal from Bitemporal Remote Sensing Images Using Cascade Convolutional Neural Networks. In: IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(1), 732-748, 9099032.
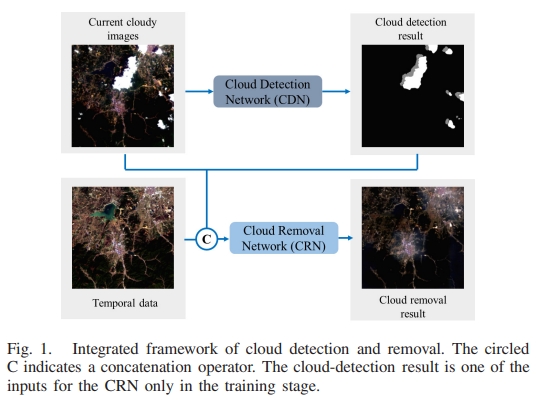
Abstract: Clouds and cloud shadows heavily affect the quality of the remote sensing images and their application potential. Algorithms have been developed for detecting, removing, and reconstructing the shaded regions with the information from the neighboring pixels or multisource data. In this article, we propose an integrated cloud detection and removal framework using cascade convolutional neural networks, which provides accurate cloud and shadow masks and repaired images. First, a novel fully convolutional network (FCN), embedded with multiscale aggregation and the channel-attention mechanism, is developed for detecting clouds and shadows from a cloudy image. Second, another FCN, with the masks of the detected cloud and shadow, the cloudy image, and a temporal image as the input, is used for the cloud removal and missing-information reconstruction. The reconstruction is realized through a self-training strategy that is designed to learn the mapping between the clean-pixel pairs of the bitemporal images, which bypasses the high demand of manual labels. Experiments showed that our proposed framework can simultaneously detect and remove the clouds and shadows from the images and the detection accuracy surpassed several recent cloud-detection methods; the effects of image restoring outperform the mainstream methods in every indicator by a large margin. The data set used for cloud detection and removal is made open. [full text] [link]
-
Dong Wei, , Xinyi Liu, Chang Li, Zhoufan Li. (2021) Robust Line Segment Matching Across Views via Ranking the Line-Point Graph. In: ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 171, 49-62.
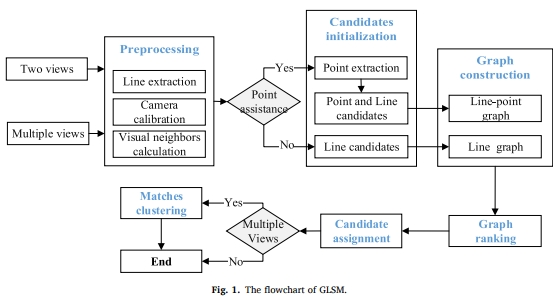
Abstract: Line segment matching in two or multiple views is helpful to 3D reconstruction and pattern recognition. To fully utilize the geometry constraint of different features for line segment matching, a novel graph-based algorithm denoted as GLSM (Graph-based Line Segment Matching) is proposed in this paper, which includes: (1) the employment of three geometry types, i.e., homography, epipolar, and trifocal tensor, to constrain line and point candidates across views; (2) the method of unifying different geometry constraints into a line-point association graph for two or multiple views; and (3) a set of procedures for ranking, assigning, and clustering with the line-point association graph. The experimental results indicate that GLSM can obtain sufficient matches with a satisfactory accuracy in both two and multiple views. Moreover, GLSM can be employed with large image datasets. The implementation of GLSM will be available soon at https://skyearth.org/research/. [link] [full text]
-
, Zuxun Zhang, Jianya Gong. (2021) Generalized Photogrammetry of Spaceborne, Airborne and Terrestrial Multi-Source Remote Sensing Datasets | 天空地多源遥感数据的广义摄影测量学. In: Cehui Xuebao/Acta Geodaetica et Cartographica Sinica, 2021, 50(1), 1-11.

Abstract: Since the 21st century, with the rapid development of cloud computing, big data, internet of things, machine learning and other information technology fields, human beings have entered a new era of artificial intelligence. The subject of photogrammetry has also followed the tide of the new round of scientific and technological revolution and developed rapidly into the brand-new generalized photogrammetry and entered the era of integrated intelligent photogrammetry. Its carrier platform, instruments and data processing theories as well as application fields have also changed significantly. The multi-sensor and multi-level integrated stereo observation technologies from spaceborne, airborne and terrestrial platforms have been greatly developed. In this paper, the novel concept of generalized photogrammetry is first put forward, and its subject connotation, development characteristics and some key technologies and applications are discussed in details. Under the brand-new generalized photogrammetry framework, data acquisition presents the characteristics of multi-angle imaging, multi-modal collaboration, multi-time integration, multi-scale linkage, while data processing presents the trends of multi-feature coupling, multi-control constraints, multi architecture processing, and multi-disciplinary intersection. The all-round development and intelligent service of the general photogrammetry still need to make greater breakthroughs in the aspects of spaceborne, airborne and terrestrial multi perspective or multi-modal image processing, intelligent information extraction and monitoring, combined 3D modeling with point cloud and image, autonomous control of unmanned system, visual inspection of intelligent manufacturing system, etc. Finally, new theories and technologies from real-time or quasi real-time intelligent geometric processing of multi-source remote sensing datasets to information extraction and intelligent service need to be established, which will make a well foundation to meet the new eara of intelligent surveying and mapping. [full text] [link]
-
Te Shi, Yansheng Li, . (2021) Rotation Consistency-Preserved Generative Adversarial Networks for Cross-Domain Aerial Image Semantic Segmentation. In: International Geoscience and Remote Sensing Symposium (IGARSS), 2021, 8668-8671.
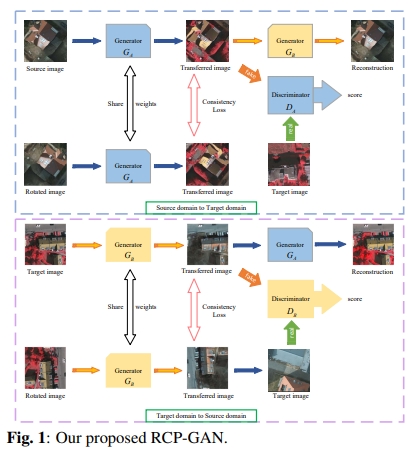
Abstract: Due to its wide applications, aerial image semantic segmentation attracts increasing research interest in recent years. As well known, deep semantic segmentation network (DSSN) has been widely used to deal with aerial image segmentation and achieves spectacular success. However, when applying the DSSN trained with the labeled aerial images (i.e., the source domain) to predict the aerial images acquired with different acquisition conditions (i.e., the target domain), the performance often dramatically degrades. To alleviate the negative influence of cross-domain data shift, this paper proposes a domain adaptation approach to deal with cross-domain aerial image semantic segmentation. More precisely, this paper proposes a novel rotation consistency-preserved generative adversarial network (RCP-GAN) to carry out domain adaptation for mapping aerial images in the source domain to the target domain. Furthermore, the mapped aerial imageries with labels are used to train DSSN, which is further used to classify aerial imagery in the target domain. To verify the validity of the presented approach, we give two cross-domain experimental settings including: (I) variation of geographic location; (II) variation of both geographic location and imaging mode. Extensive experiments under two typical cross-domain settings show that our proposed method can effectively address the domain shift problem and outperform the state-of-the-art methods with a large margin. [full text] [link]
-
Yansheng Li, Deyu Kong, , Ruixian Chen, Jingdong Chen. (2021) Representation Learning of Remote Sensing Knowledge Graph for Zero-Shot Remote Sensing Image Scene Classification. In: International Geoscience and Remote Sensing Symposium (IGARSS), 2021, 2021-July, 1351-1354.
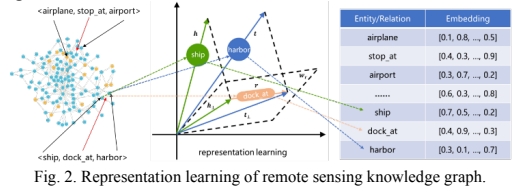
Abstract: Although deep learning has revolutionized remote sensing image scene classification, current deep learning-based approaches highly depend on the massive supervision of the predetermined scene categories and have disappointingly poor performance on new categories which go beyond the predetermined scene categories. In reality, the classification task often has to be extended along with the emergence of new applications that inevitably involve new categories of remote sensing image scenes, so how to make the deep learning model own the inference ability to recognize the remote sensing image scenes from unseen categories becomes incredibly important. By fully exploiting the remote sensing domain characteristic, this paper proposes a novel remote sensing knowledge graph-guided deep alignment network to address zero-shot remote sensing image scene classification. To improve the semantic representation ability of remote sensing-oriented scene categories, this paper, for the first time, tries to generate the semantic representations of remote sensing scene categories by representation learning of remote sensing knowledge graph (SR-RSKG). In addition, this paper proposes a novel deep alignment network with a series of constraints (DAN) to conduct robust cross-modal alignment between visual features and semantic representations. Extensive experiments on one merged remote sensing image scene dataset, which is the integration of multiple publicly open remote sensing image scene datasets, show that the presented SR-RSKG obviously outperforms the existing semantic representation methods (e.g., the natural language processing models and manually annotated attribute vectors), and our proposed DAN shows better performance compared with the state-of-the-art methods under different kinds of semantic representations. [full text] [link]
-
Dong Wei, , Chang Li. (2021) Robust Line Segment Matching via Reweighted Random Walks on the Homography Graph. In: Pattern Recognition, 2021, 111, 107693.
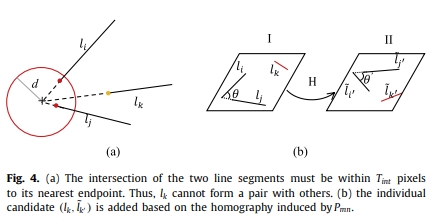
Abstract: This paper presents a novel method for matching line segments between stereo images. Given the fundamental matrix, the local homography can be over determined with pairwise line segment candidates. We exploit this constraint to initialize the candidate and construct the novel homography graph. Because the constraint between the node is based on the epipolar geometry, the homography graph is invariant to the local projective transformation. We employ the reweighted random walk on the graph to rank the candidate, then, we propose the constrained-greedy algorithm to obtain the reliable match. To the best of our knowledge, this is the first study to embed the epipolar geometry into the graph matching theory for the line segment matching. When evaluated on the 32 image patches, our method outperformed the state of the art methods, especially in the scenes of the wide baseline, steep viewpoint changes and dense line segments. The proposed algorithm is available at https://github.com/weidong-whu/line-match-RRW. [full text] [link]
-
Yansheng Li, Jiayi Ma, . (2021) Image Retrieval from Remote Sensing Big Data: A Survey. In: Information Fusion, 2021, 67, 94-115.
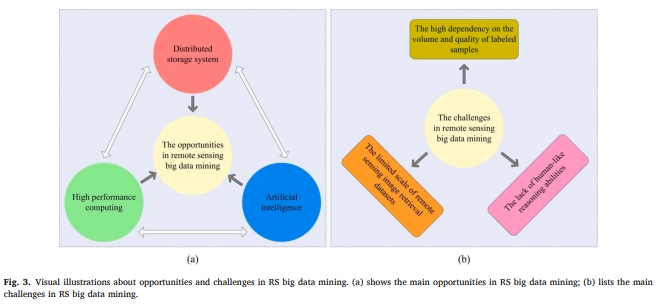
Abstract: The blooming proliferation of aeronautics and astronautics platforms, together with the ever-increasing remote sensing imaging sensors on these platforms, has led to the formation of rapidly-growing earth observation data with the characteristics of large volume, large variety, large velocity, large veracity and large value, which raises awareness about the importance of large-scale image processing, fusion and mining. Unconsciously, we have entered an era of big earth data, also called remote sensing (RS) big data. Although RS big data provides great opportunities for a broad range of applications such as disaster rescue, global security, and so forth, it inevitably poses many additional processing challenges. As one of the most fundamental and important tasks in RS big data mining, image retrieval (i.e., image information mining) from RS big data has attracted continuous research interests in the last several decades. This paper mainly works for systematically reviewing the emerging achievements for image retrieval from RS big data. And then this paper further discusses the RS image retrieval based applications including fusion-oriented RS image processing, geo-localization and disaster rescue. To facilitate the quantitative evaluation of the RS image retrieval technique, this paper gives a list of publicly open datasets and evaluation metrics, and briefly recalls the mainstream methods on two representative benchmarks of RS image retrieval. Considering the latest advances from multiple domains including computer vision, machine learning and knowledge engineering, this paper points out some promising research directions towards RS big data mining. From this survey, engineers from industry may find skills to improve their RS image retrieval systems and researchers from academia may find ideas to conduct some innovative work. [full text] [link]
-
, Wangshan Yang, Xinyi Liu, Yi Wan, Xianzhang Zhu, Yuhui Tan. (2021) Unsupervised Building Instance Segmentation of Airborne Lidar Point Clouds for Parallel Reconstruction Analysis. In: Remote Sensing, 2021, 13(6), 1136.

Abstract: Efficient building instance segmentation is necessary for many applications such as parallel reconstruction, management and analysis. However, most of the existing instance segmentation methods still suffer from low completeness, low correctness and low quality for building instance segmentation, which are especially obvious for complex building scenes. This paper proposes a novel unsupervised building instance segmentation (UBIS) method of airborne Light Detection and Ranging (LiDAR) point clouds for parallel reconstruction analysis, which combines a clustering algorithm and a novel model consistency evaluation method. The proposed method first divides building point clouds into building instances by the improved kd tree 2D shared nearest neighbor clustering algorithm (Ikd-2DSNN). Then, the geometric feature of the building instance is obtained using the model consistency evaluation method, which is used to determine whether the building instance is a single building instance or a multi-building instance. Finally, for multiple building instances, the improved kd tree 3D shared nearest neighbor clustering algorithm (Ikd-3DSNN) is used to divide multi-building instances again to improve the accuracy of building instance segmen-tation. Our experimental results demonstrate that the proposed UBIS method obtained good per-formances for various buildings in different scenes such as high-rise building, podium buildings and a residential area with detached houses. A comparative analysis confirms that the proposed UBIS method performed better than state-of-the-art methods. [full text] [link]
-
Yansheng Li, , Zhihui Zhu. (2021) Error-Tolerant Deep Learning for Remote Sensing Image Scene Classification. In: IEEE Transactions on Cybernetics, 2021, 51(4), 1756-1768, 9093113.
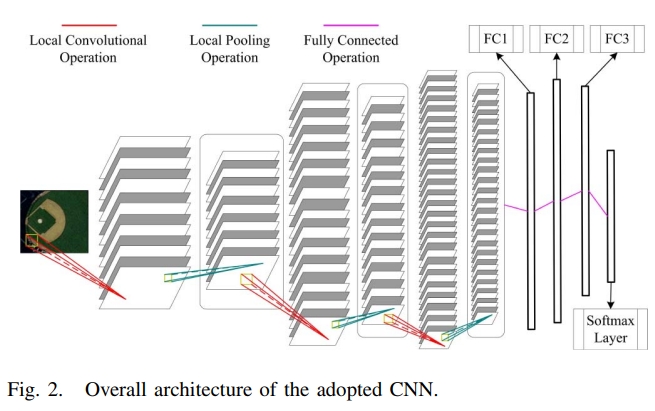
Abstract: Due to its various application potentials, the remote sensing image scene classification (RSSC) has attracted a broad range of interests. While the deep convolutional neural network (CNN) has recently achieved tremendous success in RSSC, its superior performances highly depend on a large number of accurately labeled samples which require lots of time and manpower to generate for a large-scale remote sensing image scene dataset. In contrast, it is not only relatively easy to collect coarse and noisy labels but also inevitable to introduce label noise when collecting large-scale annotated data in the remote sensing scenario. Therefore, it is of great practical importance to robustly learn a superior CNN-based classification model from the remote sensing image scene dataset containing non-negligible or even significant error labels. To this end, this article proposes a new RSSC-oriented error-tolerant deep learning (RSSC-ETDL) approach to mitigate the adverse effect of incorrect labels of the remote sensing image scene dataset. In our proposed RSSC-ETDL method, learning multiview CNNs and correcting error labels are alternatively conducted in an iterative manner. It is noted that to make the alternative scheme work effectively, we propose a novel adaptive multifeature collaborative representation classifier (AMF-CRC) that benefits from adaptively combining multiple features of CNNs to correct the labels of uncertain samples. To quantitatively evaluate the performance of error-tolerant methods in the remote sensing domain, we construct remote sensing image scene datasets with: 1) simulated noisy labels by corrupting the open datasets with varying error rates and 2) real noisy labels by deploying the greedy annotation strategies that are practically used to accelerate the process of annotating remote sensing image scene datasets. Extensive experiments on these datasets demonstrate that our proposed RSSC-ETDL approach outperforms the state-of-the-art approaches. [full text] [link]
-
, Dong Wei, Yansheng Li. (2021) AG3line: Active Grouping and Geometry-Gradient Combined Validation for Fast Line Segment Extraction. In: Pattern Recognition, 2021, 113, 107834.
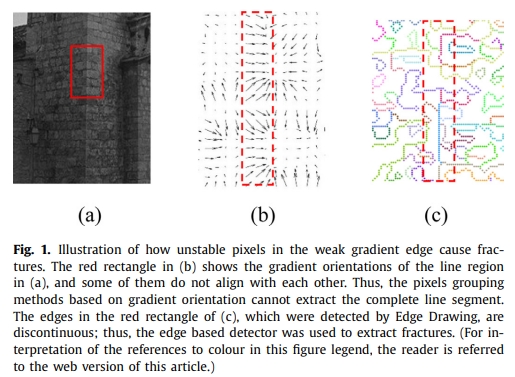
Abstract: Line segment detectors based on local image domain passively fit a line segment from a set of pixels, but no constraint on line geometry is set in the grouping process. Therefore, unstable pixels, such as the pixels in grass, clouds, or weak gradient edges, may cause false positives and fractures. This paper proposes the detector named AG3line, which employs an efficient active grouping strategy. In AG3line, the pixel for the next grouping is calculated actively with the line geometry and it can even be accurate to one pixel. To reduce the fracture caused by unstable pixels, when the adjacent pixel cannot satisfy the grouping rules, the candidate pixels for the next grouping are expanded with the line geometry constraint. To furtherly control false positives, AG3line then validates and refines the line segments by exploiting both the line geometry and the alignment of gradient magnitude. When AG3line was evaluated utilizing the image dataset with the ground truth, it outperformed both the classical and the latest detectors.The implementation of AG3line is available at https://github.com/weidong-whu/AG3line. [full text] [link]
-
Yansheng Li, Te Shi, , Wei Chen, Zhibin Wang, Hao Li. (2021) Learning Deep Semantic Segmentation Network Under Multiple Weakly-supervised Constraints for Cross-Domain Remote Sensing Image Semantic Segmentation. In: ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 175, 20-33.
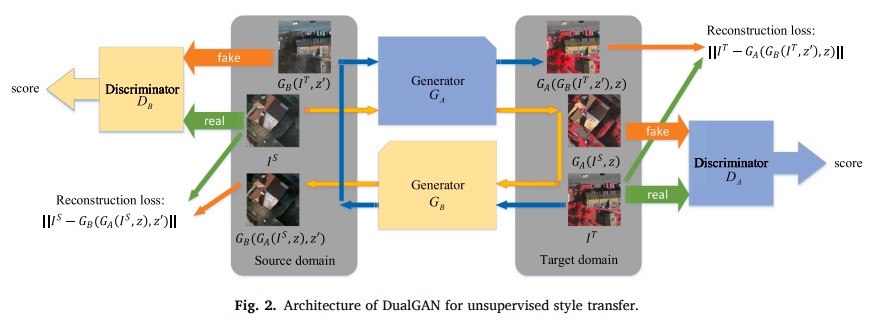
Abstract: Due to its wide applications, remote sensing (RS) image semantic segmentation has attracted increasing research interest in recent years. Benefiting from its hierarchical abstract ability, the deep semantic segmentation network (DSSN) has achieved tremendous success on RS image semantic segmentation and has gradually become the mainstream technology. However, the superior performance of DSSN highly depends on two conditions: (I) massive quantities of labeled training data exist; (II) the testing data seriously resemble the training data. In actual RS applications, it is difficult to fully meet these conditions due to the RS sensor variation and the distinct landscape variation in different geographic locations. To make DSSN fit the actual RS scenario, this paper exploits the cross-domain RS image semantic segmentation task, which means that DSSN is trained on one labeled dataset (i.e., the source domain) but is tested on another varied dataset (i.e., the target domain). In this setting, the performance of DSSN is inevitably very limited due to the data shift between the source and target domains. To reduce the disadvantageous influence of data shift, this paper proposes a novel objective function with multiple weakly-supervised constraints to learn DSSN for cross-domain RS image semantic segmentation. Through carefully examining the characteristics of cross-domain RS image semantic segmentation, multiple weakly-supervised constraints include the weakly-supervised transfer invariant constraint (WTIC), weakly-supervised pseudo-label constraint (WPLC) and weakly-supervised rotation consistency constraint (WRCC). Specifically, DualGAN is recommended to conduct unsupervised style transfer between the source and target domains to carry out WTIC. To make full use of the merits of multiple constraints, this paper presents a dynamic optimization strategy that dynamically adjusts the constraint weights of the objective function during the training process. With full consideration of the characteristics of the cross-domain RS image semantic segmentation task, this paper gives two cross-domain RS image semantic segmentation settings: (I) variation in geographic location and (II) variation in both geographic location and imaging mode. Extensive experiments demonstrate that our proposed method remarkably outperforms the state-of-the-art methods under both of these settings. The collected datasets and evaluation benchmarks have been made publicly available online (https://github.com/te-shi/MUCSS). [full text] [link]
-
Zhi Zheng, Yi Wan, , Sizhi Xiang, Daifeng Peng, Bin Zhang. (2021) CLNet: Cross-Layer Convolutional Neural Network for Change Detection in Optical Remote Sensing Imagery. In: ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 175, 247-267.
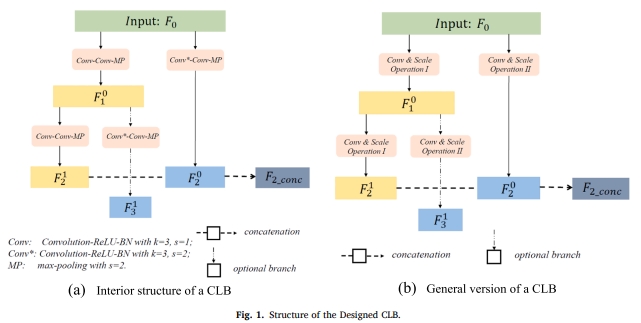
Abstract: Change detection plays a crucial role in observing earth surface transition and has been widely investigated using deep learning methods. However, the current deep learning methods for pixel-wise change detection still suffer from limited accuracy, mainly due to their insufficient feature extraction and context aggregation. To address this limitation, we propose a novel Cross Layer convolutional neural Network (CLNet) in this paper, where the UNet structure is used as the backbone and newly designed Cross Layer Blocks (CLBs) are embedded to incorporate the multi-scale features and multi-level context information. The designed CLB starts with one input and then split into two parallel but asymmetric branches, which are leveraged to extract the multi-scale features by using different strides; and the feature maps, which come from the opposite branches but have the same size, are concatenated to incorporate multi-level context information. The designed CLBs aggregate the multi-scale features and multi-level context information so that the proposed CLNet can reuse extracted feature information and capture accurate pixel-wise change in complex scenes. Quantitative and qualitative experiments were conducted on a public very-high-resolution satellite image dataset (VHR-Dataset), a newly released building change detection dataset (LEVIR-CD Dataset) and an aerial building change detection dataset (WHU Building Dataset). The CLNet reached an F1-score of 0.921 and an overall accuracy of 98.1% with the VHR-Dataset, an F1-score of 0.900 and an overall accuracy of 98.9% with the LEVIR-CD Dataset, and an F1-score of 0.963 and an overall accuracy of 99.7% with the WHU Building Dataset. The experimental results with all the selected datasets showed that the proposed CLNet outperformed several state-of-the-art (SOTA) methods and achieved competitive accuracy and efficiency trade-offs. The code of CLNet will be released soon at: https://skyearth.org/publication/project/CLNet. [full text] [link]
-
Jiayuan Li, , Hu Q. (2021) Robust Estimation in Robot Vision and Photogrammetry: a New Model and its Applications. In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2021, 5(1), 137-144.
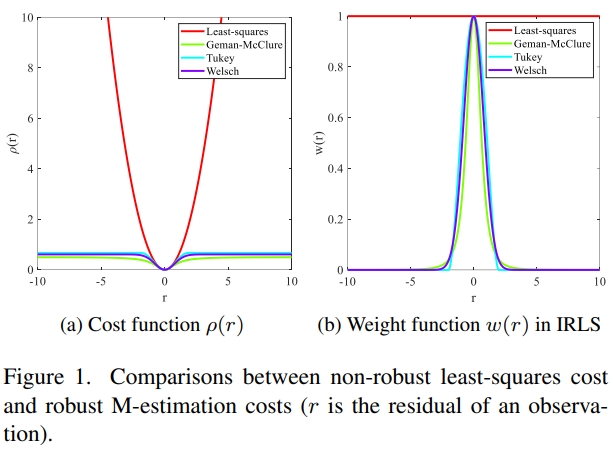
Abstract: Robust estimation (RE) is a fundamental issue in robot vision and photogrammetry, which is the theoretical basis of geometric model estimation with outliers. However, M-estimations solved by iteratively reweighted least squares (IRLS) are only suitable for cases with low outlier rates. [full text] [link]
-
Daifeng Peng, Lorenzo Bruzzone, , Haiyan Guan, Haiyong Ding, Xu Huang. (2021) SemiCDNet: A Semisupervised Convolutional Neural Network for Change Detection in High Resolution Remote-Sensing Images. In: IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(7), 5891-5906, 9161009.
Abstract: Change detection (CD) is one of the main applications of remote sensing. With the increasing popularity of deep learning, most recent developments of CD methods have introduced the use of deep learning techniques to increase the accuracy and automation level over traditional methods. However, when using supervised CD methods, a large amount of labeled data is needed to train deep convolutional networks with millions of parameters. These labeled data are difficult to acquire for CD tasks. To address this limitation, a novel semisupervised convolutional network for CD (SemiCDNet) is proposed based on a generative adversarial network (GAN). First, both the labeled data and unlabeled data are input into the segmentation network to produce initial predictions and entropy maps. Then, to exploit the potential of unlabeled data, two discriminators are adopted to enforce the feature distribution consistency of segmentation maps and entropy maps between the labeled and unlabeled data. During the competitive training, the generator is continuously regularized by utilizing the unlabeled information, thus improving its generalization capability. The effectiveness and reliability of our proposed method are verified on two high-resolution remote sensing data sets. Extensive experimental results demonstrate the superiority of the proposed method against other state-of-the-art approaches. [full text] [link]
-
Yansheng Li, Deyu Kong, , Yihua Tan, Ling Chen. (2021) Robust Deep Alignment Network with Remote Sensing Knowledge Graph for Zero-Shot and Generalized Zero-Shot Remote Sensing Image Scene Classification. In: ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 179, 145-158.
Abstract: Although deep learning has revolutionized remote sensing (RS) image scene classification, current deep learning-based approaches highly depend on the massive supervision of predetermined scene categories and have disappointingly poor performance on new categories that go beyond predetermined scene categories. In reality, the classification task often has to be extended along with the emergence of new applications that inevitably involve new categories of RS image scenes, so how to make the deep learning model own the inference ability to recognize the RS image scenes from unseen categories, which do not overlap the predetermined scene categories in the training stage, becomes incredibly important. By fully exploiting the RS domain characteristics, this paper constructs a new remote sensing knowledge graph (RSKG) from scratch to support the inference recognition of unseen RS image scenes. To improve the semantic representation ability of RS-oriented scene categories, this paper proposes to generate a Semantic Representation of scene categories by representation learning of RSKG (SR-RSKG). To pursue robust cross-modal matching between visual features and semantic representations, this paper proposes a novel deep alignment network (DAN) with a series of well-designed optimization constraints, which can simultaneously address zero-shot and generalized zero-shot RS image scene classification. Extensive experiments on one merged RS image scene dataset, which is the integration of multiple publicly open datasets, show that the recommended SR-RSKG obviously outperforms the traditional knowledge types (e.g., natural language processing models and manually annotated attribute vectors), and our proposed DAN shows better performance compared with the state-of-the-art methods under both the zero-shot and generalized zero-shot RS image scene classification settings. The constructed RSKG will be made publicly available along with this paper (https://github.com/kdy2021/SR-RSKG). [full text] [link]
-
Yongxiang Yao, , Yi Wan, Xinyi Liu, Haoyu Guo. (2021) Heterologous Images Matching Considering Anisotropic Weighted Moment and Absolute Phase Orientation | 顾及各向异性加权力矩与绝对相位方向的异源影像匹配. In: Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomatics and Information Science of Wuhan University, 2021, 46(11), 1727-1736.

Abstract: Objectives: With the enrichment of heterologous image acquisition methods, heterologous image is widely used in many fields, such as change detection, target recognition and disaster assessment. However, matching is the premise of heterologous image fusion application. Simultaneously, due to the differences in imaging mechanisms of different sensors, heterologous images are more sensitive to differences in illumination, contrast, and nonlinear radiation distortion. Therefore, heterologous image matching still faces some problems. There are two main problems, heterologous image feature detection is difficult due to the difference of imaging mechanism, which indirectly increases the difficulty of matching, heterologous image has significant differences in illumination, contrast and nonlinear radiation distortion, which reduces the robustness of feature description and easily leads to matching failure directly. Methods: This paper proposes a new matching method considering anisotropic weighted moment and the histogram of the absolute phase orientation. Firstly, anisotropic filtering is used for image nonlinear diffusion. Based on this, the maximum moment and minimum moment of image phase consistency are calculated, and the anisotropic weighted moment equation is constructed to obtain the anisotropic weighted moment map. Then, the phase consistency model is extended to establish the absolute phase consistency orientation gradient. Combined with the log polar description template, a histogram of absolute phase consistency gradients (HAPCG) is established. Finally, the Euclidean distance is used as the matching measure for corresponding point recognition. Results: Several groups of heterologous remote sensing images with illumination, contrast, and nonlinear radiation distortion are used as data sources of experiments with scale invariant feature transform(SIFT), position scale orientation⁃SIFT(PSO⁃SIFT), Log⁃Gabor histogram descriptor(LGHD) and radiation⁃variation insensitive feature transform(RIFT) methods, respectively. The results show that HAPCG method is superior to SIFT, PSO⁃SIFT and LGHD in the comprehensive matching performance of heterologous remote sensing images, and the average matching number of corresponding points is increased by over 2 times, and the root mean square error is 1.83 pixels. When compared with RIFT method, HAPCG method can achieve higher matching accuracy in the case of similar corresponding points and can realize the robust matching of heterologous remote sensing images. Conclusions: The proposed HAPCG method can achieve robust matching performance in heterologous remote sensing images and provide stable data support for multi⁃source image data fusion and other tasks. [full text] [link]
-
Yansheng Li, Zhihui Zhu, Yu, Jin-gang Yu, . (2021) Learning Deep Cross-Modal Embedding Networks for Zero-Shot Remote Sensing Image Scene Classification. In: IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(12), 10590-10603.
Abstract: Due to its wide applications, remote sensing (RS) image scene classification has attracted increasing research interest. When each category has a sufficient number of labeled samples, RS image scene classification can be well addressed by deep learning. However, in the RS big data era, it is extremely difficult or even impossible to annotate RS scene samples for all the categories in one time as the RS scene classification often needs to be extended along with the emergence of new applications that inevitably involve a new class of RS images. Hence, the RS big data era fairly requires a zero-shot RS scene classification (ZSRSSC) paradigm in which the classification model learned from training RS scene categories obeys the inference ability to recognize the RS image scenes from unseen categories, in common with the humans' evolutionary perception ability. Unfortunately, zero-shot classification is largely unexploited in the RS field. This article proposes a novel ZSRSSC method based on locality-preservation deep cross-modal embedding networks (LPDCMENs). The proposed LPDCMENs, which can fully assimilate the pairwise intramodal and intermodal supervision in an end-to-end manner, aim to alleviate the problem of class structure inconsistency between two hybrid spaces (i.e., the visual image space and the semantic space). To pursue a stable and generalization ability, which is highly desired for ZSRSSC, a set of explainable constraints is specially designed to optimize LPDCMENs. To fully verify the effectiveness of the proposed LPDCMENs, we collect a new large-scale RS scene data set, including the instance-level visual images and class-level semantic representations (RSSDIVCS), where the general and domain knowledge is exploited to construct the class-level semantic representations. Extensive experiments show that the proposed ZSRSSC method based on LPDCMENs can obviously outperform the state-of-the-art methods, and the domain knowledge further improves the performance of ZSRSSC compared with the general knowledge. The collected RSSDIVCS will be made publicly available along with this article. [full text] [link]
-
Daifeng Peng, Lorenzo Bruzzone, , Haiyan Guan, Pengfei He. (2021) SCDNET: A Novel Convolutional Network for Semantic Change Detection in High Resolution Optical Remote Sensing Imagery. In: International Journal of Applied Earth Observation and Geoinformation, 2021, 103, 102465.
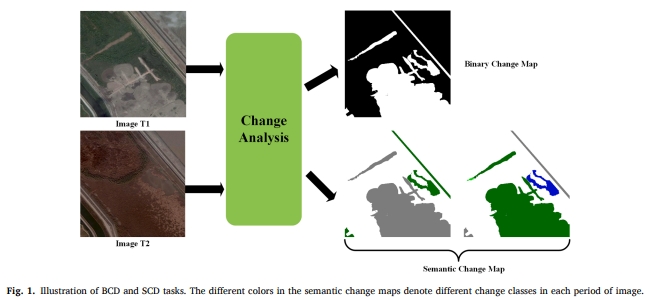
Abstract: With the continuing improvement of remote-sensing (RS) sensors, it is crucial to monitor Earth surface changes at fine scale and in great detail. Thus, semantic change detection (SCD), which is capable of locating and identifying “from-to” change information simultaneously, is gaining growing attention in RS community. However, due to the limitation of large-scale SCD datasets, most existing SCD methods are focused on scene-level changes, where semantic change maps are generated with only coarse boundary or scarce category information. To address this issue, we propose a novel convolutional network for large-scale SCD (SCDNet). It is based on a Siamese UNet architecture, which consists of two encoders and two decoders with shared weights. First, multi-temporal images are given as input to the encoders to extract multi-scale deep representations. A multi-scale atrous convolution (MAC) unit is inserted at the end of the encoders to enlarge the receptive field as well as capturing multi-scale information. Then, difference feature maps are generated for each scale, which are combined with feature maps from the encoders to serve as inputs for the decoders. Attention mechanism and deep supervision strategy are further introduced to improve network performance. Finally, we utilize softmax layer to produce a semantic change map for each time image. Extensive experiments are carried out on two large-scale high-resolution SCD datasets, which demonstrates the effectiveness and superiority of the proposed method. [full text] [link]
-
Xinwei Li, Yansheng Li, . (2021) Weakly Supervised Deep Semantic Segmentation Network for Water Body Extraction Based on Multi-Source Remote Sensing Imagery | 弱监督深度语义分割网络的多源遥感影像水体检测. In: Journal of Image and Graphics, 2021, 26(12), 3015-3026.
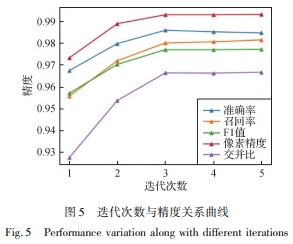
Abstract: Objective: Water body detection has shown important applications in flood disaster assessment, water resource value estimation and ecological environment protection based on remote sensing imagery. Deep semantic segmentation network has achieved great success in the pixel-level remote sensing image classification. Water body detection performance can be reasonably expected based on the deep semantic segmentation network. However, the excellent performance of deep semantic segmentation network is highly dependent on the large-scale and high-quality pixel-level labels. This research paper has intended to leverage the existing open water cover products to create water labels corresponding to remote sensing images in order to reduce the workload of labeling and meantime maintain the fair detection accuracy. The existing open water cover products have a low spatial resolution and contain a certain degree of errors. The noisy low-resolution water labels have inevitably affected the training of deep semantic segmentation network for water body detection. A weakly supervised deep learning method to train deep semantic segmentation network have been taken into consideration to resolve the difficulties. The optimization method to train deep semantic segmentation network using the noisy low-resolution labels for the high accuracy of water detection has been presented based on minimizing the manual annotation cost. Method In the training stage, the original dataset has been divided into several non-overlapped sub-datasets. The deep semantic segmentation network has been trained on each sub-dataset. The trained deep semantic segmentation networks with different sub-datasets have updated the labels simultaneously. As the non-overlapped sub-datasets generally have different data distributions, the detection performance of different networks with different sub-datasets is also complementary. The prediction of the same region by different networks is different, so the multi-perspective deep semantic segmentation network can realize the collaborative update of labels. The updated labels have been used to repeat the above process to re-train new deep semantic segmentation networks. Following each step of iteration, the output of the network has been used as the new labels. The noisy labels have been removed with the iteration process. The range of truth value of the water has also be expanded continuously along with the iteration process. Several good deep semantic segmentation networks can be obtained after a few iterations. In the test stage, the multi-source remote sensing images have been predicted by several deep semantic segmentation networks representing different perspectives and producing the final water detection voting results. Result The multi-source remote sensing image training dataset, validation dataset and testing dataset have been built up for verification. The multi-source remote sensing imagery has composed of Sentinel-1 SAR (synthetic aperture radar) images and Sentinel-2 optical images. The training dataset has contained 150 000 multi-source remote sensing samples with the size of 256x256 pixels. The labels of the training dataset have been intercepted with the public MODIS (moderate-resolution imaging spectroradiometer) water coverage products in geographic scale. The spatial resolution of the training dataset is low and contains massive noise. The validation dataset has contained 100 samples with the size of 256x256 pixels and the testing dataset have contained 400 samples with the size of 256x256 pixels, and the labels from the validation and testing datasets have accurately annotated with the aid of domain experts. The training, validation and testing datasets have not been overlapped each and the dataset can geographically cover in global scale. Experimental results have shown that the proposed method is convergent, and the accuracy tends to be stable based on four iterations. The fusion of optical and SAR images can improve the accuracy of water body detection. The IoU (intersection over union) has increased by 5.5% compared with the traditional water index segmentation method. The IoU has increases by 7.2% compared with the deep semantic segmentation network directly using the noisy low-resolution water labels. Conclusion: The experimental results have shown that the current method can converge fast, and the fusion of optical and SAR images can improve the detection results. On the premise of the usage of the noisy low-resolution water labels, the water body detection accuracy of the trained multi-perspective model is obviously better than the traditional water index segmentation method and the deep semantic segmentation network based on the direct learning of the noisy low-resolution water labels. The accuracy of the traditional deep semantic segmentation method is slightly lower than that of the traditional water index method, which indicates that the effectiveness of deep learning highly depends on the quality of the training data labels. The noisy low-resolution water labels have reduced the effect of deep learning. The effect of the proposed method on small rivers and lakes has been analyzed. The accuracy on small rivers and lakes has decreased slightly. The result has still higher than the traditional water index method and the deep learning method with the direct training of the noisy low-resolution water labels. [full text] [link]
-
Xiao Ling, Xu Huang, , Gang Zhou. (2020) Matching Confidence Constrained Bundle Adjustment for Multi-View High-Resolution Satellite Images. In: Remote Sensing, 2020, 12(1), 20.
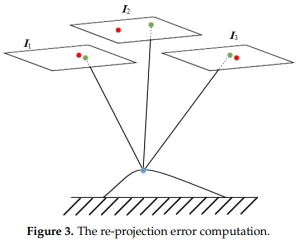
Abstract: Bundle adjustment of multi-view satellite images is a powerful tool to align the orientations of all the images in a unified framework. However, the traditional bundle adjustment process faces a problem in detecting mismatches and evaluating low/medium/high-accuracy matches, which limits the final bundle adjustment accuracy, especially when the mismatches are several times more than the correct matches. To achieve more accurate bundle adjustment results, this paper formulates the prior knowledge of matching accuracy as matching confidences and proposes a matching confidence based bundle adjustment method. The core algorithm firstly selects several highest-confidence matches to initially correct orientations of all images, then detects and eliminates the mismatches under the initial orientation guesses and finally formulates both the matching confidences and the forward-backward projection errors as weights in an iterative bundle adjustment process for more accurate orientation results. We compared our proposed method with the famous RANSAC strategy as well as a state-of-the-art bundle adjustment method on the high-resolution multi-view satellite images. The experimental comparisons are evaluated by image checking points and ground control points, which shows that our proposed method is able to obtain more robust and more accurate mismatch detection results than the RANSAC strategy, even though the mismatches are four times more than the correct matches and it can also achieve more accurate orientation results than the state-of-the-art bundle adjustment method. [full text] [link]
-
Yameng Wang, Shunping Ji, Meng Lu, . (2020) Attention Boosted Bilinear Pooling for Remote Sensing Image Retrieval. In: International Journal of Remote Sensing, 2020, 41(7), 2704-2724.

Abstract: Remote sensing image retrieval is to find the most identical or similar images to a query image in the vast archive of remote sensing images. A key process is to extract the most distinctive features. In this study, we introduce a second-order pooling named compact bilinear pooling (CBP) into convolutional neural networks (CNNs) for remote sensing image retrieval. The retrieval algorithm has three stages, pretraining, fine-tuning and retrieval. In the pretraining stage, two classic CNN structures, VGG16 and ResNet34, are pretrained respectively with the ImageNet consisting of close-range images. A CBP layer is introduced before the fully connected layers in the two networks. To extract globally consistent representations, a channel and spatial integrated attention mechanism is proposed to refine features from the last convolution layer and the features are used as the input of the CBP. In the fine-tuning stage, the new network is fine-tuned on a remote sensing dataset to train discriminable features. In the retrieval stage, the network, with fully connected layers being replaced by a PCA (principal component analysis) module, is applied to new remote sensing datasets. Our retrieval algorithm with the combination of CBP and PCA obtained the best performance and outperformed several mainstream pooling or encoding methods such as full-connected layer, IFK (Improved Fisher Kernel), BoW (Bag-of-Words) and maxpooling, etc. The channel and spatial attention mechanism contributes to the CBP based retrieval method and obtained the best performance on all the datasets, as well as outperformed several recent attention methods. Source code is available at http://study.rsgis/whu.edu.cn/pages/download. [full text] [link]
-
Linyu Liu, , Yansheng Li, Xinyi Liu, Yi Wan. (2020) PM2.5 Inversion Using Remote Sensing Data in Eastern China Based on Deep Learning | 基于深度学习的华东地区PM2.5浓度遥感反演. In: Huanjing Kexue/Environmental Science, 2020, 41(4), 1513-1519.
Abstract: PM2.5, which is a major source of air pollution, has a considerable impact on human health. In this study, a multi-element joint PM2.5 inversion method based on a deep learning model is proposed. With PM2.5concentration as the ground truth, 10 elements including the Himawari-AOD daily data products, temperature, relative humidity, and pressure, were introduced as inversion elements. To verify the effectiveness of the method, the experiment was carried out by season using remote sensing data in Eastern China during 2016-2018. The results demonstrate that PM2.5 concentrations were positively correlated with AOD, precipitation, wind speed, and high vegetation cover index and negatively correlated with dwarf vegetation cover index. The correlation with temperature, humidity, pressure, and DEM changed with seasons. Comparative experiments indicated that the accuracy of PM2.5 inversion based on the deep neural network is higher than that of traditional linear and nonlinear models. R2 was above 0.5, and the error was small in each season. The R2 value for autumn, which showed the best inversion, was 0.86, that for summer was 0.75, that for winter was 0.613, and that for spring was 0.566. The visualization of the model illustrates that the inversion result of the DNN model is closer to the PM2.5 concentration distribution interpolated by the ground monitoring station, and the resolution is higher and more accurate. [full text] [link]
-
Lin Xiang, Xiaoling Jiang, Yueqin Xu, , Tongqing Zhu. (2020) Patch-Based Partial Motion Blurred Segmentation. In: International Journal of Cognitive Computing in Engineering, 2020, 1, 45-54.

Abstract: Motion blur has a significant impact on image recognition. Segmentation of motion-blurred regions contributes to further identification or classification. Most existed segmentation algorithms are always universal for partially blur images, but not especially for motion-blurred ones. This paper proposes a particular algorithm aiming at motion-blurred region segmentation. Firstly, motion regions are segmented by a patch-based preprocessing. Then, the blurriness of motion regions is measured by a defined function to detect local blurred areas. Empirical thresholds are recommended according to the experimental results. The experimental results show that the motion-blurred regions can be segmented more accurately, and the speed almost doubles other algorithms. Thus we propose a more accurate and efficient segmentation method, especially for partial motion-blurred images. [full text] [link]
-
Xiaohu Yan, , Dejun Zhang, Neng Hou. (2020) Multimodal Image Registration using Histogram of Oriented Gradient Distance and Data-Driven Grey Wolf Optimizer. In: Neurocomputing, 2020, 392, 108-120.
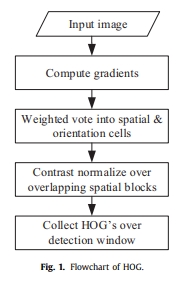
Abstract: Multimodal image registration is becoming increasingly important in remote sensing. However, due to the significant nonlinear intensity differences between multimodal images, conventional registration methods tend to get trapped into local optima. To address this issue, we present a new approach for multimodal image registration using histogram of oriented gradient distance (HOGD) and data-driven grey wolf optimizer (DDGWO). First, we propose a novel similarity measure for area-based registration methods that is HOGD. We investigate the performance of HOGD by analyzing its similarity curve. HOGD has a large range of values, which is helpful to find the global optimum. Second, we use GWO to optimize the transformation parameters. Since it is time-consuming to calculate HOGD, we propose DDGWO to minimize HOGD. In DDGWO, the iterations are divided into two parts: the training and prediction iterations. A support vector machine (SVM) regression model is trained by the historical HOGD computed in the training iterations. The trained SVM model predicts HOGD instead of calculating in the prediction iterations, which can reduce the computational time. Finally, we test the proposed approach that uses HOGD as the similarity measure and DDGWO as the search algorithm on 12 real and four simulated image pairs. Extensive experiments demonstrate that our approach saves up to 83.35-84.15% of computational time and outperforms the state-of-the-art algorithms in terms of registration accuracy. [full text] [link]
-
Chi Liu, , Shugen Wang, Mingwei Sun, Yangjun Ou, Yi Wan, Xiu Liu. (2020) Band-Independent Encoder-Decoder Network for Pan-Sharpening of Remote Sensing Images. In: IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(7), 5208-5223, 9013047.
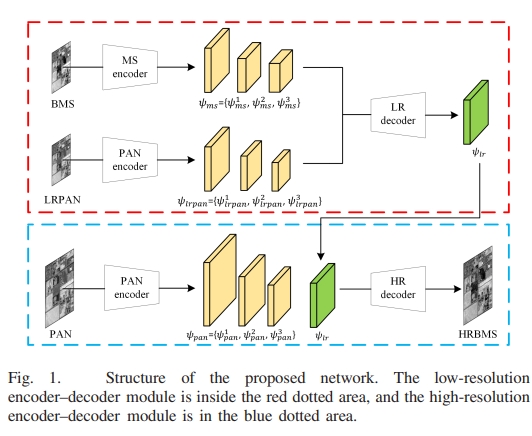
Abstract: Pan-sharpening is a fundamental task for remote sensing image processing. It aims at creating a high-resolution multispectral (HRMS) image from a multispectral (MS) image and a panchromatic (PAN) image. In this article, a new band-independent encoder-decoder network is proposed for pan-sharpening. The network takes a single band of the MS (BMS) image, the PAN image, and the low-resolution PAN (LRPAN) image as inputs. The output of the network is the corresponding band of high-resolution MS (HRBMS) image. In this way, the network can process MS images with any number of bands. The overall structure of the network consists of two encoder-decoder modules at low-resolution and high-resolution, respectively. An auxiliary LRPAN image is used to speed up the training and improve the performance. The partly shared network and hierarchical structure for low-resolution and high-resolution enable a better fusion of features extracted from different scales. With a fast fine-tuning strategy, the trained model can be applied to images from different sensors. Experiments performed on different data sets demonstrate that the proposed method outperforms several state-of-the-art pan-sharpening methods in both visual appearance and objective indexes, and the single-band evaluation results further verify the superiority of the proposed method. [full text] [link]
-
Guangshuai Wang, Yi Wan, . (2020) Registration of Airborne LiDAR Data and Multi-View Aerial Images Constrained by Junction Structure Features | 交叉点结构特征约束的机载LiDAR点云与多视角航空影像配准. In: Journal of Geo-Information Science, 2020, 22(9), 1868-1877.
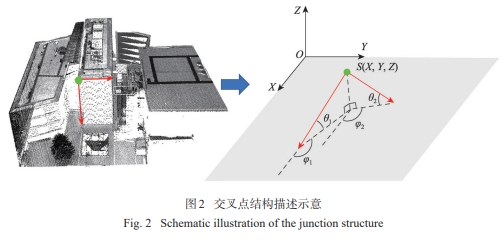
Abstract: The integration of Airborne LiDAR data and aerial imagery is useful in data interpretation, land monitoring, and 3D reconstruction. As the first step of these tasks, the geometric registration of the two types of data should be conducted to ensure their alignment. The alignment is sometimes difficult because of differences in their data acquisition mechanisms. The LiDAR data is more reliable and more accurate on smooth surfaces like grounds, walls, and roofs which are difficult to extract from aerial imagery. LiDAR points are mostly sparser than the pixels on aerial images. Considering that the a priori ranging error (1~5 cm) of airborne LiDAR data is usually much smaller than the average point distance (10~50 cm), this paper introduced a plane-constrained block adjustment model to align the two types of data, where the planes were obtained by the intersection of corresponding junction structures. The planar constraints were implemented by forcing surrounding LiDAR points to be on the planes. The proposed block adjustment model is a mixture of the conventional POS-aided and self-calibrated bundle adjustment model and two more types of observing equations. One is the distance between image junction structure observations, and reprojection of the spatial junction structure should be zeros. The other is the normal distance between LiDAR points, and the spatial planes obtained by junction structure should be zeros. In this paper, firstly junction structures in object space were solved based on least squares theory. Then, conjugate planes of junction structures in LiDAR points were detected automatically. Finally, the aerial images block adjustment under constraints of junction structure was performed to obtain the precise interior and exterior orientation parameters. The experimental results showed that both the horizontal and the vertical accuracy of the proposed method could reach 1~2 pixels of the aerial images, which was obviously better than the building-corner-based method. In order to probe into the influence of point cloud density, the LiDAR points were thinned randomly before the geometric registration. The results showed that the accuracy of the proposed method was not influenced but the accuracy of building-corner-based method decreased when the point cloud density decreased, especially the horizontal accuracy. In conclusion, the proposed method takes the advantage of the high-ranging accuracy of LiDAR data to reach high registration accuracy and avoids the influence of the point cloud density. When the density of the LiDAR point cloud is low, a high registration accuracy can be reached using the proposed method. [full text] [link]
-
Yansheng Li, Ruixian Chen, , Hang Li. (2020) A CNN-GCN Framework for Multi-Label Aerial Image Scene Classification. In: International Geoscience and Remote Sensing Symposium (IGARSS), 2020, 1353-1356, 9323487.
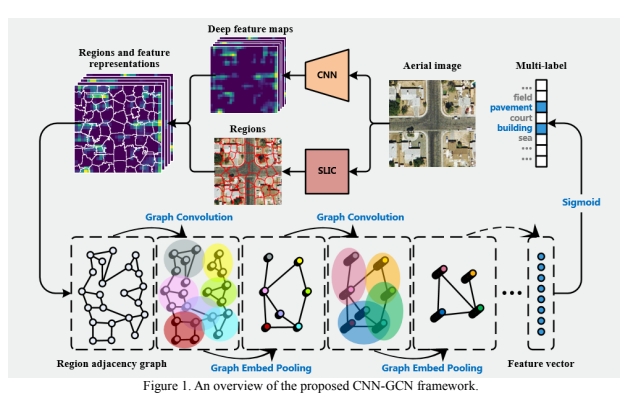
Abstract: As one of the fundamental tasks in aerial image understanding, multi-label aerial image scene classification attracts increasing research interest. In general, the semantic category of a scene is reflected by the object information and the topological relations among objects. Most of existing deep learning-based aerial image scene classification methods (e.g., convolutional neural network (CNN)) classify the image scene by perceiving object information, while how to learn spatial relationships from image scene is still a challenging problem. In literature, graph convolutional network (GCN) has been successfully used for learning spatial characteristics of topological data, but it is rarely adopted in aerial image scene classification. To simultaneously mine both the object visual information and spatial relationships among multiple objects, this paper proposes a novel framework combining CNN and GCN to address multi-label aerial image scene classification. Extensive experimental results on two public datasets show that our proposed method can achieve better performance than the state-of-the-art methods. [full text] [link]
-
Yansheng Li, Te Shi, Wei Chen, , Zhibin Wang, Hao Li. (2020) Unsupervised Style Transfer via Dualgan for Cross-Domain Aerial Image Classification. In: International Geoscience and Remote Sensing Symposium (IGARSS), 2020, 1385-1388, 9323671.
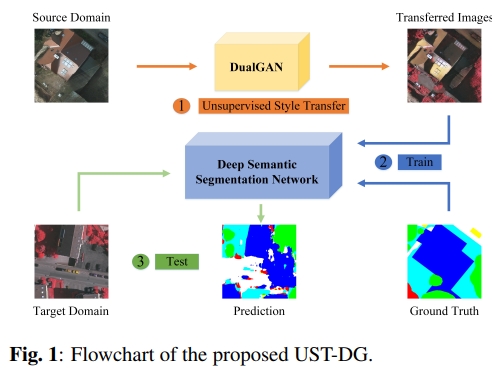
Abstract: Due to its wide applications, aerial image classification, which is also called semantic segmentation of aerial imagery, attracts increasing research interest in recent years. Until now, deep semantic segmentation network (DSSN) has been widely adopted to address aerial image classification and achieves tremendous success. However, the superior performance of DSSN highly depends on massive targeted data with labels. When DSSN is trained on data from the source domain but tested on data from the target domain, the performance of DSSN is often very limited due to the data shift between source and target domains. To alleviate the disadvantage influence of data shift, this paper proposes a domain adaptation approach via unsupervised style transfer to cope with cross-domain aerial image classification. More specifically, this paper innovatively recommends DualGAN to conduct unsupervised style transfer for mapping aerial images in the source domain to the target domain. The mapped aerial imagery with labels is adopted to train DSSN, which is further used to classify aerial imagery in the target domain. To verify the validity of the presented approach, we give two cross-domain experimental settings including: (I) variation of geographic location; (II) variation of both geographic location and imaging mode. Extensive experiments under two typical cross-domain settings show that our proposed method can obviously outperform the state-of-the-art methods. [full text] [link]
-
Wei Chen, Yansheng Li, , Xiaolong Hao. (2020) Deep Networks under Block-Level Supervision for Pixel-Level Cloud Detection in Multi-Spectral Satellite Imagery. In: International Geoscience and Remote Sensing Symposium (IGARSS), 2020, 1612-1615, 9324486.
Abstract: Cloud cover hinders the usability of optical remote sensing imagery. Existing cloud detection methods either require hand-crafted features or utilize deep networks. Generally, deep networks perform better than hand-crafted features. However, deep networks for cloud detection need massive and expensive pixel-level annotation labels. To alleviate that, this paper proposes a weakly supervised deep learning-based cloud detection method using only block-level labels, with a new global convolutional pooling operation and a local pooling pruning strategy to improve the performance. For evaluating, we collect a training dataset containing over 160,000 image blocks with block-level labels and a testing dataset including ten large image scenes with pixel-level labels. Even under extremely weak supervision, our method performed well with the average overall accuracy reached 97.2 %. Experiments demonstrate that our proposed method obviously outperforms the state-of-the-art methods. [full text] [link]
-
Peiyu Dai, Shunping Ji, . (2020) Gated Convolutional Networks for Cloud Removal from Bi-temporal Remote Sensing Images. In: Remote Sensing, 2020, 12(20),1-18, 3427.
Abstract: Pixels of clouds and cloud shadows in a remote sensing image impact image quality, image interpretation, and subsequent applications. In this paper, we propose a novel cloud removal method based on deep learning that automatically reconstructs the invalid pixels with the auxiliary information from multi-temporal images. Our method's innovation lies in its feature extraction and loss functions, which reside in a novel gated convolutional network (GCN) instead of a series of common convolutions. It takes the current cloudy image, a recent cloudless image, and the mask of clouds as input, without any requirements of external training samples, to realize a self-training process with clean pixels in the bi-temporal images as natural training samples. In our feature extraction, gated convolutional layers, for the first time, are introduced to discriminate cloudy pixels from clean pixels, which make up for a common convolution layer’s lack of the ability to discriminate. Our multi-level constrained joint loss function, which consists of an image-level loss, a feature-level loss, and a total variation loss, can achieve local and global consistency both in shallow and deep levels of features. The total variation loss is introduced into the deep-learning-based cloud removal task for the first time to eliminate the color and texture discontinuity around cloud outlines needing repair. On the WHU cloud dataset with diverse land cover scenes and different imaging conditions, our experimental results demonstrated that our method consistently reconstructed the cloud and cloud shadow pixels in various remote sensing images and outperformed several mainstream deep-learning-based methods and a conventional method for every indicator by a large margin. [full text] [link]
-
Yansheng Li, Wei Chen, , Chao Tao, Rui Xiao, Yihua Tan. (2020) Accurate Cloud Detection in High-Resolution Remote Sensing Imagery by Weakly Supervised Deep Learning. In: Remote Sensing of Environment, 2020, 250, 112045.

Abstract: Cloud cover is a common and inevitable phenomenon that often hinders the usability of optical remote sensing (RS) image data and further interferes with continuous cartography based on RS image interpretation. In the literature, the off-the-shelf cloud detection methods either require various hand-crafted features or utilize data-driven features using deep networks. Overall, deep networks achieve much better performance than traditional methods using hand-crafted features. However, the current deep networks used for cloud detection depend on massive pixel-level annotation labels, which require a great deal of manual annotation labor. To reduce the labor needed for annotating the pixel-level labels, this paper proposes a weakly supervised deep learning-based cloud detection (WDCD) method using block-level labels indicating only the presence or the absence of cloud in one RS image block. In the training phase, a new global convolutional pooling (GCP) operation is proposed to enhance the ability of the feature map to represent useful information (e.g., spatial variance). In the testing phase, the trained deep networks are modified to generate the cloud activation map (CAM) via the local pooling pruning (LPP) strategy, which prunes the local pooling layers of the deep networks that are trained in the training phase to improve the quality (e.g., spatial resolution) of CAM. One large RS image is cropped into multiple overlapping blocks by a sliding window, and then the CAM of each block is generated by the modified deep networks. Based on the correspondence between the image blocks and CAMs, multiple corresponding CAMs are collected to mosaic the CAM of the large image. By segmenting the CAM using a statistical threshold against a clear-sky surface, the pixel-level cloud mask of the testing image can be obtained. To verify the effectiveness of our proposed WDCD method, we collected a new global dataset, for which the training dataset contains over 200,000 RS image blocks with block-level labels from 622 large GaoFen-1 images from all over the world; the validation dataset contains 5 large GaoFen-1 images with pixel-level annotation labels, and the testing dataset contains 25 large GaoFen-1 and ZiYuan-3 images with pixel-level annotation labels. Even under the extremely weak supervision, our proposed WDCD method could achieve excellent cloud detection performance with an overall accuracy (OA) as high as 96.66%. Extensive experiments demonstrated that our proposed WDCD method obviously outperforms the state-of-the-art methods. The collected datasets have been made publicly available online (https://github.com/weichenrs/WDCD). [full text] [link]
-
Xiaohu Yan, , Dejun Zhang, Neng Hou, Bin Zhang. (2020) Registration of Multimodal Remote Sensing Images Using Transfer Optimization. In: IEEE Geoscience and Remote Sensing Letters, 2020, 17(12),2060-2064, 8959355.
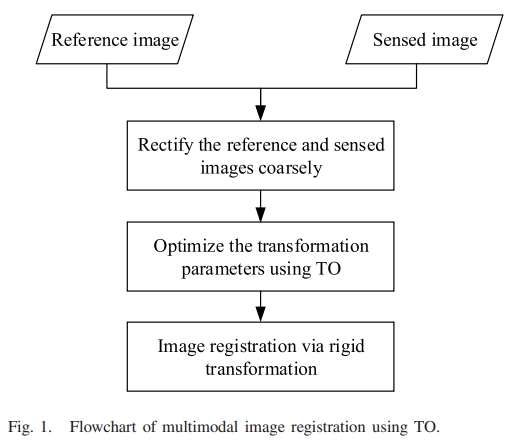
Abstract: Multimodal image registration is critical yet challenging for remote sensing image processing. Due to the large nonlinear intensity differences between the multimodal images, conventional search algorithms tend to get trapped into local optima when optimizing the transformation parameters by maximizing mutual information (MI). To address this problem, inspired by transfer learning, we propose a novel search algorithm named transfer optimization (TO), which can be applied to any optimizer. In TO, an optimizer transfers its better individuals to the other optimizer in each iteration. Thus, TO can share information between two optimizers and take advantage of their search mechanisms, which is helpful to avoid the local optima. Then, the registration of the multimodal remote sensing images using TO is presented. We compare the proposed algorithm with several state-of-the-art algorithms on real and simulated image pairs. Experimental results demonstrate the superiority of our algorithm in terms of registration accuracy. [full text] [link]
-
Yansheng Li, Ruixian Chen, , Mi Zhang, Ling Chen. (2020) Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and A Graph Neural Network. In: Remote Sensing, 2020, 12(23),1-17, 4003.
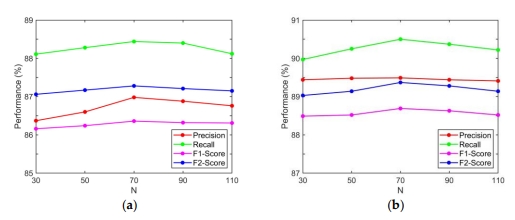
Abstract: As one of the fundamental tasks in remote sensing (RS) image understanding, multi-label remote sensing image scene classification (MLRSSC) is attracting increasing research interest. Human beings can easily perform MLRSSC by examining the visual elements contained in the scene and the spatio-topological relationships of these visual elements. However, most of existing methods are limited by only perceiving visual elements but disregarding the spatio-topological relationships of visual elements. With this consideration, this paper proposes a novel deep learning-based MLRSSC framework by combining convolutional neural network (CNN) and graph neural network (GNN), which is termed the MLRSSC-CNN-GNN. Specifically, the CNN is employed to learn the perception ability of visual elements in the scene and generate the high-level appearance features. Based on the trained CNN, one scene graph for each scene is further constructed, where nodes of the graph are represented by superpixel regions of the scene. To fully mine the spatio-topological relationships of the scene graph, the multi-layer-integration graph attention network (GAT) model is proposed to address MLRSSC, where the GAT is one of the latest developments in GNN. Extensive experiments on two public MLRSSC datasets show that the proposed MLRSSC-CNN-GNN can obtain superior performance compared with the state-of-the-art methods. [full text] [link]
-
Yansheng Li, Deyu Kong, , Zheng Ji, Rui Xiao. (2020) Zero-shot remote sensing image scene classification based on robust cross-domain mapping and gradual refinement of semantic space | 联合稳健跨域映射和渐进语义基准修正的零样本遥感影像场景分类. In: Cehui Xuebao/Acta Geodaetica et Cartographica Sinica, 2020, 49(12), 1564-1574.
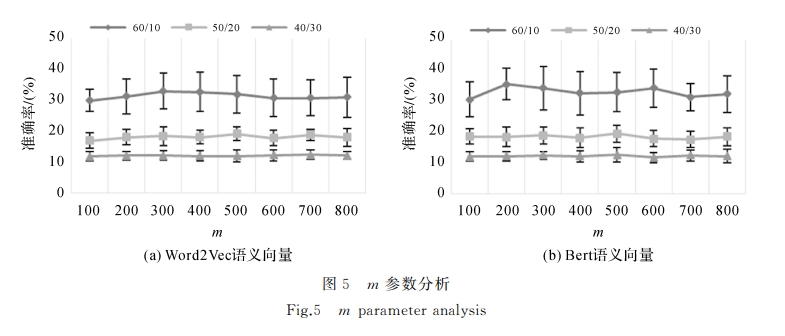
Abstract: Zero-shot classification technology aims to acquire the ability to identify categories that do not appear in the training stage (unseen classes) by learning some categories of the data set (seen classes), which has important practical significance in the era of remote sensing big data. Until now, the zero-shot classification methods in remote sensing field pay little attention to the semantic space optimization after mapping, which results in poor classification performance. Based on this consideration, this paper proposed a zero shot remote sensing image scene classification method based on cross-domain mapping with auto-encoder and collaborative representation learning. In the supervised learning module, based on the class semantic vector of seen class and the scene image sample, the depth feature extractor learning and robust mapping from visual space to semantic space are realized. In the unsupervised learning stage, based on the class semantic vectors of all classes and the unseen remote sensing image samples, collaborative representation learning and k-nearest neighbor algorithm are used to modify the semantic vectors of unseen classes, so as to alleviate the problem of the shift of seen class semantic space and unseen class semantic space one after another and unseen after self coding cross domain mapping model mapping the shift of class semantic space and unseen class semantic space after collaborative representation. In the testing phase, based on the depth feature extractor, self coding cross domain mapping model and modified unseen class semantic vector, the classification of unseen class remote sensing image scene can be realized. We integrate a number of open remote sensing image scene data sets and build a new remote sensing image scene data set, experiments were conducted using this dataset The experimental results show that the algorithm proposed in this paper were significantly better than the existing zero shot classification method in the case of a variety of seen and unseen classes. [full text] [link]
-
Bin Zhang, , Shugen Wang. (2019) A Lightweight and Discriminative Model for Remote Sensing Scene Classification with Multidilation Pooling Module. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019, 12(8), 2636-2653, 8746195.
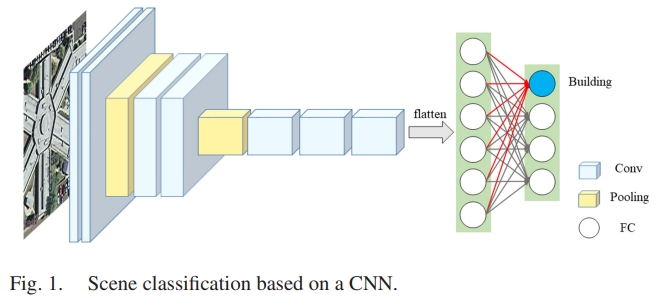
Abstract: With the growing spatial resolution of satellite images, high spatial resolution (HSR) remote sensing imagery scene classification has become a challenging task due to the highly complex geometrical structures and spatial patterns in HSR imagery. The key issue in scene classification is how to understand the semantic content of the images effectively, and researchers have been looking for ways to improve the process. Convolutional neural networks (CNNs), which have achieved amazing results in natural image classification, were introduced for remote sensing image scene classification. Most of the researches to date have improved the final classification accuracy by merging the features of CNNs. However, the entire models become relatively complex and cannot extract more effective features. To solve this problem, in this paper, we propose a lightweight and effective CNN which is capable of maintaining high accuracy. We use MobileNet V2 as a base network and introduce the dilated convolution and channel attention to extract discriminative features. To improve the performance of the CNN further, we also propose a multidilation pooling module to extract multiscale features. Experiments are performed on six datasets, and the results verify that our method can achieve higher accuracy compared to the current state-of-the-art methods. [full text] [link]
-
, Fei Wen, Zhi Gao, Xiao Ling. (2019) A Coarse-to-Fine Framework for Cloud Removal in Remote Sensing Image Sequence. In: IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(8), 5963-5974, 8675771.

Abstract: Clouds and accompanying shadows, which exist in optical remote sensing images with high possibility, can degrade or even completely occlude certain ground-cover information in images, limiting their applicabilities for Earth observation, change detection, or land-cover classification. In this paper, we aim to deal with cloud contamination problems with the objective of generating cloud-removed remote sensing images. Inspired by low-rank representation together with sparsity constraints, we propose a coarse-to-fine framework for cloud removal in the remote sensing image sequence. Leveraging on group-sparsity constraint, we first decompose the observed cloud image sequence of the same area into the low-rank component, group-sparse outliers, and sparse noise, corresponding to cloud-free land-covers, clouds (and accompanying shadows), and noise respectively. Subsequently, a discriminative robust principal component analysis (RPCA) algorithm is utilized to assign aggressive penalizing weights to the initially detected cloud pixels to facilitate cloud removal and scene restoration. Moreover, we incorporate geometrical transformation into a low-rank model to address the misalignment of the image sequence. Significantly superior to conventional cloud-removal methods, neither cloud-free reference image(s) nor additional operations of cloud and shadow detection are required in our method. Extensive experiments on both simulated data and real data demonstrate that our method works effectively, outperforming many state-of-the-art approaches. [full text] [link]
-
, Zhi Zheng, Yimin Luo, Yanfeng Zhang, Yi Wan, Jun Wu, Zhiyong Peng, Xiu Liu. (2019) A CNN-Based Subpixel Level DSM Generation Approach via Single Image Super-Resolution. In: Photogrammetric Engineering and Remote Sensing, Vol.85(10): 51-491.

Abstract: Previous work for subpixel level Digital Surface Model (DSM) generation mainly focused on data fusion techniques, which are extremely limied by the difficulty of multisource data acquisition. Although several DSMsuper resolution (SR) methods have been developed to ease the problem, a new issue that plenty of DSM samples are needed to train the model is raised. Therefore, considering the original images have vital influence on its DSM's accuracy, we address the problem by directly improving images resolution. Several SR models are refined and brought into the traditional DSMgeneration process as an image quality improvement stage to construct an easy but effective workflow for subpixel level DSM generation. Experiments verified the validity and significance of bringing SR technology into this kind of application. Statistical analysis also confirmed that a subpixel level DSM with higher fidelity can be obtained more easily compared to directly DSM interpolation. [full text] [link]
-
Xiaohu Yan, Fazhi He, , Xunwei Xie. (2019) An optimizer ensemble algorithm and its application to image registration. In: Integrated Computer Aided Engineering, Vol.26(1): 1-17.

Abstract: The design of effective optimization algorithms is always a hot research topic. An optimizer ensemble where any population-based optimization algorithm can be integrated is proposed in this study. First, the optimizer ensemble framework based on ensemble learning is presented. The learning table consisting of the population members of all optimizers is constructed to share information. The maximum number of iterations is divided into several exchange iterations. Each optimizer exchanges individuals with the learning table in exchange iterations and runs independently in the other iterations. Exchange individuals are generated by a bootstrap sample from the learning table. To maintain a balance between exchange individuals and preserved individuals, the exchange number of each optimizer is adaptively assigned according to its fitness. The output is obtained by the voting approach that selects the highest ranked solution. Second, an optimizer ensemble algorithm (OEA) which combines multiple population-based optimization algorithms is proposed. The computational complexity, convergence, and diversity of OEA are analyzed. Finally, extensive experiments on benchmark functions demonstrate that OEA outperforms several state-of-the-art algorithms. OEA is used to search the maximum mutual information in image registration. The high performance of OEA is further verified by a large number of registration results on real remote sensing images. [full text] [link]
-
Bin Zhang, , Shugen Wang. (2019) A Lightweight and Discriminative Model for Remote Sensing Scene Classification With Multidilation Pooling Module. In: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, Vol.12(8): 2636-2653.
Abstract: With the growing spatial resolution of satellite images, high spatial resolution (HSR) remote sensing imagery scene classification has become a challenging task due to the highly complex geometrical structures and spatial patterns in HSR imagery. The key issue in scene classification is how to understand the semantic content of the images effectively, and researchers have been looking for ways to improve the process. Convolutional neural networks (CNNs), which have achieved amazing results in natural image classification, were introduced for remote sensing image scene classification. Most of the researches to date have improved the final classification accuracy by merging the features of CNNs. However, the entire models become relatively complex and cannot extract more effective features. To solve this problem, in this paper, we propose a lightweight and effective CNN which is capable of maintaining high accuracy. We use MobileNet V2 as a base network and introduce the dilated convolution and channel attention to extract discriminative features. To improve the performance of the CNN further, we also propose a multidilation pooling module to extract multiscale features. Experiments are performed on six datasets, and the results verify that our method can achieve higher accuracy compared to the current state-of-the-art methods. [full text] [link]
-
Xinyi Liu, , Xiao Ling, Yi Wan, Linyu Liu, Qian Li. (2019) TopoLAP: Topology Recovery for Building Reconstruction by Deducing the Relationships between Linear and Planar Primitives. In: Remote Sensing, Vol.11:1372.
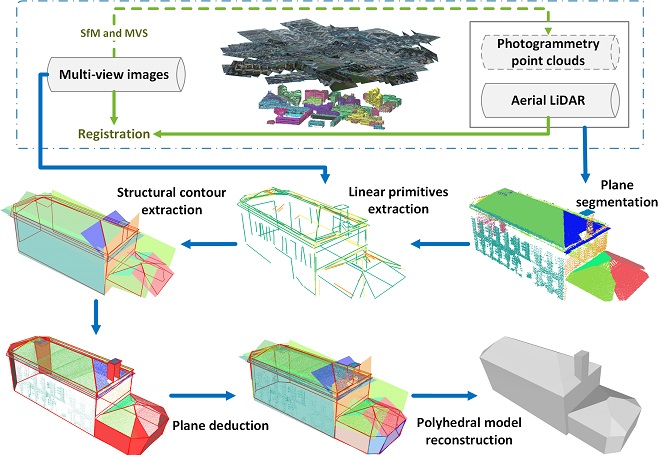
Abstract: Limited by the noise, missing data and varying sampling density of the point clouds, planar primitives are prone to be lost during plane segmentation, leading to topology errors when reconstructing complex building models. In this paper, a pipeline to recover the broken topology of planar primitives (TopoLAP) is proposed to reconstruct level of details 3 (LoD3) models. Firstly, planar primitives are segmented from the incomplete point clouds and feature lines are detected both from point clouds and images. Secondly, the structural contours of each plane segment are reconstructed by subset selection from intersections of these feature lines. Subsequently, missing planes are recovered by plane deduction according to the relationships between linear and planar primitives. Finally, the manifold and watertight polyhedral building models are reconstructed based on the optimized PolyFit framework. Experimental results demonstrate that the proposed pipeline can handle partial incomplete point clouds and reconstruct the LoD3 models of complex buildings automatically. A comparative analysis indicates that the proposed method performs better to preserve sharp edges and achieves a higher fitness and correction rate than rooftop-based modeling and the original PolyFit algorithm. [full text] [link]
-
Yi Wan, , Xinyi Liu. (2019) An a-contrario method of mismatch detection for two-view pushbroom satellite images. In: ISPRS Journal of Photogrammetry and Remote Sensing, Vol.99: 1-15.
Abstract: Mismatch detection is a key step in the geometric correction of satellite images. However, most RANSAC-based mismatch detection methods face two problems in practical application, i.e., how to preset the threshold when the apriori matching accuracy is not known and how to validate the correctness of the results when the proportions of true matches are very low. In this paper, we propose an a-contrario method named ORSA-SAT to remove the mismatches for two-view satellite images by finding the most meaningful set of matches. The formula first is defined to compute the geometric rigidity of a set of point matches according to the image match search area with the matching accuracy measured by the maximum point-to-epipolar-line distance. Then, the meaningfulness of a set is rated by a probabilistic criterion that estimates the number of false alarms (NFA), which indicates the expected times that a set can be found by chance from non-rigid and randomly distributed matched points. The criterion is a function of the quantity of point-matches and the geometric rigidity and is used in ORSA-SAT for comparing two sets. The true matches are collected by finding the most meaningful set; thus, no preset thresholds are needed to separate the true matches and the mismatches. Furthermore, the criterion also justifies the correctness of the sets obtained by ORSA-SAT since rigid sets rarely occur from mismatches. In this paper, we use both simulated data and real matched points on images captured by IKONOS-2, ZY-3, and Landsat-8 to demonstrate ORSA-SAT. The results of the simulated experiments show that both the precisions and the recalls were ensured above 80% in the correct results of ORSA-SAT even though there were over 90% mismatches originally. [full text] [link]
-
, Xinyi Liu, Yi Zhang, Xiao Ling, Xu Huang. (2019) Automatic and Unsupervised Water Body Extraction Based on Spectral-Spatial Features Using GF-1 Satellite Imagery. In: IEEE Geoscience and Remote Sensing Letters, Vol.16, No.6: 927-931.

Abstract: Water body extraction from remote sensing imagery is an essential and nontrivial issue due to the complexity of the spectral characteristics of various kinds of water bodies and the redundant background information. An automatic multifeature water body extraction (MFWE) method integrating spectral and spatial features is proposed in this letter for water body extraction from GF-1 multispectral imagery in an unsupervised way. This letter first discusses a spatial feature index, called the pixel region index (PRI), to describe the smoothness in a local area surrounding a pixel. PRI is advantageous for assisting the normalized difference water index (NDWI) in detecting major water bodies, especially in urban areas. On the other hand, part of the water pixels near the borders may not be included in major water bodies, k-means clustering is subsequently conducted to cluster all the water pixels into the same group as a guide map. Finally, the major water bodies and the guide map are merged to obtain the final water mask. Our experimental results demonstrate that accurate water masks were achieved for all seven GF-1 imagery scenes examined. Three images with a complex background and water conditions were used to quantitatively compare the proposed method to NDWI thresholding and support vector machine classification, which verified the higher accuracy and effectiveness of the proposed method. [full text] [link]
-
Shunping Ji, Yanyun Shen, Meng Lu, . (2019) Building Instance Change Detection from Large-Scale Aerial Images using Convolutional Neural Networks and Simulated Samples. In: Remote Sensing, Vol.11(11): 1343.

Abstract: We present a novel convolutional neural network (CNN)-based change detection framework for locating changed building instances as well as changed building pixels from very high resolution (VHR) aerial images. The distinctive advantage of the framework is the self-training ability, which is highly important in deep-learning-based change detection in practice, as high-quality samples of changes are always lacking for training a successful deep learning model. The framework consists two parts: a building extraction network to produce a binary building map and a building change detection network to produce a building change map. The building extraction network is implemented with two widely used structures: a Mask R-CNN for object-based instance segmentation, and a multi-scale full convolutional network for pixel-based semantic segmentation. The building change detection network takes bi-temporal building maps produced from the building extraction network as input and outputs a building change map at the object and pixel levels. By simulating arbitrary building changes and various building parallaxes in the binary building map, the building change detection network is well trained without real-life samples. This greatly lowers the requirements of labeled changed buildings, and guarantees the algorithm's robustness to registration errors caused by parallaxes. To evaluate the proposed method, we chose a wide range of urban areas from an open-source dataset as training and testing areas, and both pixel-based and object-based model evaluation measures were used. Experiments demonstrated our approach was vastly superior: without using any real change samples, it reached 63% average precision (AP) at the object (building instance) level. In contrast, with adequate training samples, other methods—including the most recent CNN-based and generative adversarial network (GAN)-based ones—have only reached 25% AP in their best cases. [full text] [link]
-
, Chi Liu, Mingwei Sun, Yangjun Ou. (2019) Pan-Sharpening Using an Efficient Bidirectional Pyramid Network. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.99: 1-15.

Abstract: Pan-sharpening is an important preprocessing step for remote sensing image processing tasks; it fuses a low-resolution multispectral image and a high-resolution (HR) panchromatic (PAN) image to reconstruct a HR multispectral (MS) image. This paper introduces a new end-to-end bidirectional pyramid network for pan-sharpening. The overall structure of the proposed network is a bidirectional pyramid, which permits the network to process MS and PAN images in two separate branches level by level. At each level of the network, spatial details extracted from the PAN image are injected into the upsampled MS image to reconstruct the pan-sharpened image from coarse resolution to fine resolution. Subpixel convolutional layers and the enhanced residual blocks are used to make the network efficient. Comparison of the results obtained with our proposed method and the results using other widely used state-of-the-art approaches confirms that our proposed method outperforms the others in visual appearance and objective indexes. [full text] [link]
-
, Fei Wen, Zhi Gao, Xiao Ling. (2019) A Coarse-to-Fine Framework for Cloud Removal in Remote Sensing Image Sequence. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.99: 1-12.

Abstract: Clouds and accompanying shadows, which exist in optical remote sensing images with high possibility, can degrade or even completely occlude certain ground-cover information in images, limiting their applicabilities for Earth observation, change detection, or land-cover classification. In this paper, we aim to deal with cloud contamination problems with the objective of generating cloud-removed remote sensing images. Inspired by low-rank representation together with sparsity constraints, we propose a coarse-to-fine framework for cloud removal in the remote sensing image sequence. Leveraging on group-sparsity constraint, we first decompose the observed cloud image sequence of the same area into the low-rank component, group-sparse outliers, and sparse noise, corresponding to cloud-free land-covers, clouds (and accompanying shadows), and noise respectively. Subsequently, a discriminative robust principal component analysis (RPCA) algorithm is utilized to assign aggressive penalizing weights to the initially detected cloud pixels to facilitate cloud removal and scene restoration. Moreover, we incorporate geometrical transformation into a low-rank model to address the misalignment of the image sequence. Significantly superior to conventional cloud-removal methods, neither cloud-free reference image(s) nor additional operations of cloud and shadow detection are required in our method. Extensive experiments on both simulated data and real data demonstrate that our method works effectively, outperforming many state-of-the-art approaches. [full text] [link]
-
Xunwei Xie, , Xiao Ling, Xiang Wang. (2019) A novel extended phase correlation algorithm based on Log-Gabor filtering for multimodal remote sensing image registration. In: International Journal of Remote Sensing, Vol.16: 1-25.

Abstract: Automatic registration of multimodal remote sensing images, which is a critical prerequisite in a range of applications (e.g. image fusion, image mosaic, and image analysis), continues to be a fundamental and challenging problem. In this paper, we propose a novel extended phase correlation algorithm based on Log-Gabor filtering (LGEPC) for the registration of images with nonlinear radiometric differences and geometric differences (e.g. rotation, scale, and translation). Our algorithm focuses on two problems that the traditional extended phase correlation algorithms cannot well handle: 1) significant nonlinear radiometric differences and 2) large-scale differences between image pairs. After an over-complete multi-scale atlas space of the original image is built based on the filtered magnitudes obtained by using Log-Gabor filters with different central frequencies, the phase correlation of the single scale images is extended by LGEPC to atlases phase correlation, which is conducive to solving the problem of large scale and rotation differences between the image pairs. Subsequently, LGEPC eliminates the interface of the significant nonlinear radiometric differences by superimposing multi-scale geometric structural spectra and carrying out the phase correlation module, so that the translation can be well determined. Our experiments on synthetic images demonstrated the rationality and effectiveness of LGEPC, and the experiments on a variety of multimodal images confirmed that LGEPC can ideally achieve pixel-wise registration accuracy for multimodal image pairs that conform to the similarity transformation model. [full text] [link]
-
Xunwei Xie, , Xiang Wang, Daifeng Peng. (2019) A Mixture Likelihood Model of the Anisotropic Gaussian and Uniform Distributions for Accurate Oblique Image Point Matching. In: IEEE Geoscience and Remote Sensing Letters.

Abstract: In this letter, we propose a mixture likelihood model for accurate oblique image point matching. The basic prior assumption is that the noises are anisotropic with zero mean and different covariances in x- and y-directions for inliers, while the outliers have uniform distribution, which is more suitable for tilted scenes or viewpoint changes. Furthermore, the oblique image point matching problem is formulated as an improved maximum a posteriori (IMAP) estimation of a Bayesian model. In this model, based on the vector field interpolation framework, we combined the mixture likelihood model and our previous adaptive image mismatch removal method, where a two-order term of the regularization coefficient is introduced into the regularized risk function, and a parameter self-adaptive Gaussian kernel function is imposed to construct the regularization term. Subsequently, the expectation-maximization algorithm is utilized to solve the IMAP estimation, in which all the latent variances are able to obtain excellent estimation. Experimental results on real data sets verified that our method was superior to some similar methods in terms of precision and also had better self-adaptability characteristic than some hypothesis-and-verify methods. More experiments on viewpoint changes demonstrated our method's effectiveness without loss of precision-recall tradeoffs, besides significant efficiency improvement. [full text] [link]
-
Daifeng Peng, , Haiyan Guan. (2019) End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. In: Remote Sensing, 11:1382.
Abstract: Change detection (CD) is essential to the accurate understanding of land surface changes using available Earth observation data. Due to the great advantages in deep feature representation and nonlinear problem modeling, deep learning is becoming increasingly popular to solve CD tasks in remote-sensing community. However, most existing deep learning-based CD methods are implemented by either generating difference images using deep features or learning change relations between pixel patches, which leads to error accumulation problems since many intermediate processing steps are needed to obtain final change maps. To address the abovementioned issues, a novel end-to-end CD method is proposed based on an effective encoderdecoder architecture for semantic segmentation named UNet++, where change maps could be learned from scratch using available annotated datasets. Firstly, co-registered image pairs are concatenated as an input for the improved UNet++ network, where both global and fine-grained information can be utilized to generate feature maps with high spatial accuracy. Then, the fusion strategy of multiple side outputs is adopted to combine change maps from different semantic levels, thereby generating a final change map with high accuracy. The effectiveness and reliability of our proposed CD method are verified on very-high-resolution (VHR) satellite image datasets. Extensive experimental results have shown that our proposed approach outperforms the other state-of-the-art CD methods. [full text] [link]
-
Mi Wang, , Yanfei Zhong, Xin Huang, Xiangyun Hu, Nengcheng Chen, Bisheng Yang, Jingbin Liu, Huanfeng Shen, Zeming Wang, Liqiong Chen, Jinglin He, Steve McClure. (2018) The State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing. Part of Celebrating 125 Years of Academic Excellence: Wuhan University (1893-2018). In: Science, pp.32-36, Online Publication, 2018.11.28.
Zhang Zuxun and his team first proposed and investigated the concept of a “full digital automation mapping system,” creating VirtuoZo, an intellectual property of China. The team also advanced a novel digital photogrammetrc grid processing system (DPGrid), which was China's first set of technologies for fully automatic processing of remotely sensed aerospace images with completely independent intellectual property rights (Figure 4). DPGrid made a crucial breakthrough by transitioning from human-machine interaction to automatic processing, which improves production efficiency by at least 10-fold. Major national engineering projects, such as geographical conditions monitoring and emergency response systems, have applied these innovations widely (Figure 5). The Environmental Systems Research Institute's ArcGIS system has integrated the core technology of DPGrid, boosting its popularity and use around the world. [full text] [link]
-
Yansheng Li, , Xin Huang, Alan L.Yuille. (2018) Deep Networks under Scene-level Supervision for Multi-class Geospatial Object Detection from Remote Sensing Images. In: ISPRS Journal of Photogrammetry and Remote Sensing Vol.146: 182-196.
Abstract: Due to its many applications, multi-class geospatial object detection has attracted increasing research interest in recent years. In the literature, existing methods highly depend on costly bounding box annotations. Based on the observation that scene-level tags provide important cues for the presence of objects, this paper proposes a weakly supervised deep learning (WSDL) method for multi-class geospatial object detection using scene-level tags only. Compared to existing WSDL methods which take scenes as isolated ones and ignore the mutual cues between scene pairs when optimizing deep networks, this paper exploits both the separate scene category information and mutual cues between scene pairs to sufficiently train deep networks for pursuing the superior object detection performance. In the first stage of our training method, we leverage pair-wise scene-level similarity to learn discriminative convolutional weights by exploiting the mutual information between scene pairs. The second stage utilizes point-wise scene-level tags to learn class-specific activation weights. While considering that the testing remote sensing image generally covers a large region and may contain a large number of objects from multiple categories with large size variations, a multi-scale scene-sliding-voting strategy is developed to calculate the class-specific activation maps (CAM) based on the aforementioned weights. Finally, objects can be detected by segmenting the CAM. The deep networks are trained on a seemingly unrelated remote sensing image scene classification dataset. Additionally, the testing phase is conducted on a publicly open multi-class geospatial object detection dataset. The experimental results demonstrate that the proposed deep networks dramatically outperform the state-of-the-art methods. [full text] [link]
-
, Xunwei Xie, Xiang Wang, Yansheng Li, Xiao Ling. (2018) Adaptive Image Mismatch Removal With Vector Field Interpolation Based on Improved Regularization and Gaussian Kernel Function. In: IEEE Access Vol.6: 55599-55613.

Abstract: When the regularized kernel methods are utilized in the mismatch removal problem, the regularization coefficient and the choice of kernel function will seriously affect the performance of the methods. In this paper, we propose a method that combines an improved regularization and an adaptive Gaussian kernel function to interpolate the vector fields so as to overcome the issue. We formulated the problem as a modified maximum a posterior estimation of a Bayesian model. In this model, a two-order term of the regularization coefficient is introduced into the regularized risk function in order that the coefficient can be adaptively estimated in the expectation-aximization algorithm. In addition, an adaptive Gaussian kernel function also is imposed to construct the regularization, in which the width of the kernel function is adaptively determined by the diagonal length of the maximum enveloping rectangle of the sample set. Our experimental results verified that our method was robust to large outlier percentages and was slightly superior to some state-of-the-art methods in precision-recall tradeoff and efficiency. The evidence that the performance of our method was insensitive to the remaining inner parameters verified its good self-adaptability. Finally, airborne image pairs were used to demonstrate that our method can establish the feature correspondences even under a discontinuous vector field scene. In addition, we found that our method can obtain higher precision given a residual threshold for special applications such as robust epipolar geometry estimation in computer vision and photogrammetry. [full text] [link]
-
Xianzhang Zhu, Hui Cao, , Kai Tan, Xiao Ling. (2018) Fine Registration for VHR Images Based on Superpixel Registration-Noise Estimation In: IEEE Geoscience and Remote Sensing Letters 15(10): 1615-1620.

Abstract: Local nonlinear geometric distortion is problematic in the registration of very high-resolution (VHR) images. In the standard registration approach, the precision of control points generated from salient feature matching cannot be guaranteed. This letter introduces a novel superpixel registration-noise (RN) estimation method based on a two-step fine registration technique that can be estimate and mitigate the local residual misalignments in VHR images. The first step employs superpixel sparse representation and multiple displacement analysis to estimate RN information of the preregistered image. The second step optimizes the control points obtained in preregistration by combining the RN information and gross error information, and finally fine registers the input image by employing local rectification. The experiments using two data sets generated from Chinese GF2, GF1, and ZY3 satellites are discussed in this letter, and the promising results verify the effectiveness of the proposed new method. [full text] [link]
-
Yansheng Li, , Xin Huang, Jiayi Ma. (2018) Learning Source-Invariant Deep Hashing Convolutional Neural Networks for Cross-Source Remote Sensing Image Retrieval. In: IEEE Transactions on Geoscience and Remote Sensing PP(99): 1-16.
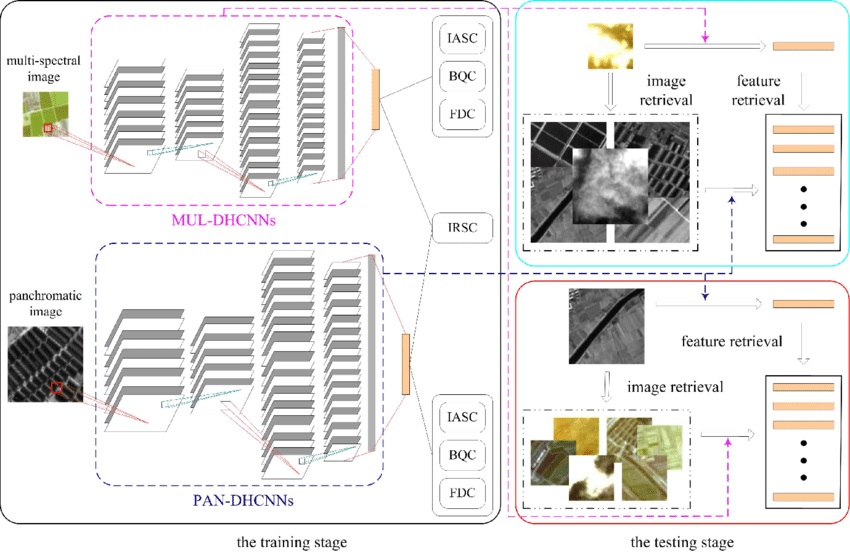
Abstract: Due to the urgent demand for remote sensing big data analysis, large-scale remote sensing image retrieval (LSRSIR) attracts increasing attention from researchers. Generally, LSRSIR can be divided into two categories as follows: uni-source LSRSIR (US-LSRSIR) and cross-source LSRSIR (CS-LSRSIR). More specifically, US-LSRSIR means the inquiry remote sensing image and images in the searching data set come from the same remote sensing data source, whereas CS-LSRSIR is designed to retrieve remote sensing images with a similar content to the inquiry remote sensing image that are from a different remote sensing data source. In the literature, US-LSRSIR has been widely exploited, but CS-LSRSIR is rarely discussed. In practical situations, remote sensing images from different kinds of remote sensing data sources are continually increasing, so there is a great motivation to exploit CS-LSRSIR. Therefore, this paper focuses on CS-LSRSIR. To cope with CS-LSRSIR, this paper proposes source-invariant deep hashing convolutional neural networks (SIDHCNNs), which can be optimized in an end-to-end manner using a series of well-designed optimization constraints. To quantitatively evaluate the proposed SIDHCNNs, we construct a dual-source remote sensing image data set that contains eight typical land-cover categories and $10,000$ dual samples in each category. Extensive experiments show that the proposed SIDHCNNs can yield substantial improvements over several baselines involving the most recent techniques. [full text] [link]
-
Fei Wen, , Zhi Gao, Xiao Ling. (2018) Two-Pass Robust Component Analysis for Cloud Removal in Satellite Image Sequence. In: IEEE Geoscience and Remote Sensing Letters PP(99): 1-5.
Abstract: Due to the inevitable existence of clouds and their shadows in optical remote sensing images, certain ground-cover information is degraded or even appears to be missing, which limits analysis and utilization. Thus, cloud removal is of great importance to facilitate downstream applications. Motivated by the sparse representation techniques which have obtained a stunning performance in a variety of applications, including target detection, anomaly detection, and so on; we propose a two-pass robust principal component analysis (RPCA) framework for cloud removal in the satellite image sequence. First, a plain RPCA is applied for initial cloud region detection, followed by a straightforward morphological operation to ensure that the cloud region is completely detected. Subsequently, a discriminative RPCA algorithm is proposed to assign aggressive penalizing weights to the detected cloud pixels to facilitate cloud removal and scene restoration. Significantly superior to currently available methods, neither a cloud-free reference image nor a specific algorithm of cloud detection is required in our method. Experiments on both simulated and real images yield visually plausible and numerically verified results, demonstrating the effectiveness of our method. [full text] [link]
-
, Xiang Wang, Xunwei Xie, Yansheng Li. (2018) Salient Object Detection via Recursive Sparse Representation. In: Remote Sensing 10(4): 652.
Abstract: Object-level saliency detection is an attractive research field which is useful for many content-based computer vision and remote-sensing tasks. This paper introduces an efficient unsupervised approach to salient object detection from the perspective of recursive sparse representation. The reconstruction error determined by foreground and background dictionaries other than common local and global contrasts is used as the saliency indication, by which the shortcomings of the object integrity can be effectively improved. The proposed method consists of the following four steps: (1) regional feature extraction; (2) background and foreground dictionaries extraction according to the initial saliency map and image boundary constraints; (3) sparse representation and saliency measurement; and (4) recursive processing with a current saliency map updating the initial saliency map in step 2 and repeating step 3. This paper also presents the experimental results of the proposed method compared with seven state-of-the-art saliency detection methods using three benchmark datasets, as well as some satellite and unmanned aerial vehicle remote-sensing images, which confirmed that the proposed method was more effective than current methods and could achieve more favorable performance in the detection of multiple objects as well as maintaining the integrity of the object area. [full text] [link]
-
Lei Yu, , Mingwei Sun, Xiuguang Zhou, Chi Liu. (2017) An Auto-adapting Global-to-Local Color Balancing Method for Optical Imagery Mosaic. In: ISPRS Journal of Photogrammetry and Remote Sensing, 132: 1-19.
Abstract: This paper presents a novel auto-adapting global-to-local color balancing method which aims to eliminate the effects of color differences between adjacent optical images to achieve seamless image mosaicking. The proposed method combines global and local optimization strategies to eliminate color differences between different target images adaptively without assigning the reference image. The global optimization strategy takes the constraint that the color information of the image before and after the color balancing process should be minimal, by which the assigning of reference images can be avoided. The strategy takes all target images as a whole and solves the normalization regression models simultaneously, which transfers the color difference elimination problem into the least square optimization one and eliminates the total color differences effectively. The local optimization strategy is a supplement for the global one, which focuses on the local information to eliminate the color differences in the overlap areas of the target images with the Gamma transform algorithm. It is worth noting that the proposed method can select a suitable processing flow from both the global and local optimization aspects based on the characteristics of the target images. When the total overlap rate of the target images is small, both the global and local strategies are employed; and when the total overlap rate of the target images is large, only the local optimization strategy is employed, by which a seamless color balancing result can be generated. The experimental results in this paper demonstrate that the proposed method performs well in color balancing for multi-type optical datasets. [full text][link]
-
Yansheng Li, . (2017) Robust Infrared Small Target Detection Using Local Steering Kernel Reconstruction. In: Pattern Recognition 77.

Abstract: Because infrared small target detection plays a crucial role in infrared monitoring and early warning systems, it has been the subject of considerable research. Although many infrared small target detection approaches have been proposed, how to robustly detect small targets in poor quality infrared images remains a challenge. Since existing feature descriptors are often sensitive to the quality of infrared images, this paper advocates the use of a local steering kernel (LSK) to encode the infrared image patch because the LSK method can provide robust estimation of local intrinsic structure, even for poor quality images. Furthermore, this paper proposes a novel local adaptive contrast measure based on LSK reconstruction (LACM-LSK) for infrared small target detection. To demonstrate the effectiveness of the proposed approach, a diverse test dataset, including six infrared image sequences with different backgrounds, was collected. Extensive experiments on the test dataset confirm that the proposed infrared small target detection approach can achieve better detection performance than state-of-the-art approaches. [full text] [link]
-
, Daifeng Peng, Xu Huang. (2017) Object-Based Change Detection for VHR Images Based on Multiscale Uncertainty Analysis. In: IEEE Geoscience and Remote Sensing Letters PP(99): 1-5.

Abstract: Scale is of great significance in image analysis and interpretation. In order to utilize scale information, multiscale fusion is usually employed to combine change detection (CD) results from different scales. However, CD results from different scales are usually treated independently, which ignores the scale contextual information. To overcome this drawback, this letter introduces a novel object-based change detection (OBCD) technique for unsupervised CD in very high-resolution (VHR) images by incorporating multiscale uncertainty analysis. First, two temporal images are stacked and segmented using a series of optimal segmentation scales ranging from coarse to fine. Second, an initial CD result is obtained by fusing the pixel-based CD result and OBCD result based on Dempter-Shafer (DS) evidence theory. Third, multiscale uncertainty analysis is implemented from coarse scale to fine scale by support vector machine classification. Finally, a CD map is generated by combining all the available information in all the scales. The experimental results employing SPOT5 and GF-1 images demonstrate the effectiveness and superiority of the proposed approach. [full text] [link]
-
Yansheng Li, , Xin Huang, Hu Zhu, Jiayi Ma. (2017) Large-Scale Remote Sensing Image Retrieval by Deep Hashing Neural Networks. In: IEEE Transactions on Geoscience and Remote Sensing PP(99).

Abstract: As one of the most challenging tasks of remote sensing big data mining, large-scale remote sensing image retrieval has attracted increasing attention from researchers. Existing large-scale remote sensing image retrieval approaches are generally implemented by using hashing learning methods, which take handcrafted features as inputs and map the high-dimensional feature vector to the low-dimensional binary feature vector to reduce feature-searching complexity levels. As a means of applying the merits of deep learning, this paper proposes a novel large-scale remote sensing image retrieval approach based on deep hashing neural networks (DHNNs). More specifically, DHNNs are composed of deep feature learning neural networks and hashing learning neural networks and can be optimized in an end-to-end manner. Rather than requiring to dedicate expertise and effort to the design of feature descriptors, we can automatically learn good feature extraction operations and feature hashing mapping under the supervision of labeled samples. To broaden the application field, DHNNs are evaluated under two representative remote sensing cases: scarce and sufficient labeled samples. To make up for a lack of labeled samples, DHNNs can be trained via transfer learning for the former case. For the latter case, DHNNs can be trained via supervised learning from scratch with the aid of a vast number of labeled samples. Extensive experiments on one public remote sensing image data set with a limited number of labeled samples and on another public data set with plenty of labeled samples show that the proposed remote sensing image retrieval approach based on DHNNs can remarkably outperform state-of-the-art methods under both of the examined conditions. [full text] [link]
-
Yansong Duan, Xiao Ling, , Zuxun Zhang, Xinyi Liu, Kun Hu. (2017) A Simple and Efficient Method for Radial Distortion Estimation by Relative Orientation. In: IEEE Transactions on Geoscience and Remote Sensing PP(99): 1-9.
Abstract: In order to solve the accuracy problem caused by lens distortions of nonmetric digital cameras mounted on an unmanned aerial vehicle, the estimation for initial values of lens distortion must be studied. Based on the fact that radial lens distortions are the most significant of lens distortions, a simple and efficient method for radial lens distortion estimation is proposed in this paper. Starting from the coplanar equation, the geometric characteristics of the relative orientation equations are explored. This paper further proves that the radial lens distortion can be linearly estimated in a continuous relative orientation model. The proposed procedure only requires a sufficient number of point correspondences between two or more images obtained by the same camera; thus it is suitable for a natural scene where the lack of straight lines and calibration objects precludes most previous techniques. Both computer simulation and real data have been used to test the proposed method; the experimental results show that the proposed method is easy to use and flexible. [full text] [link]
-
Chang li, Xiaojuan Liu, , Zuxun Zhang. (2017) A Stepwise-then-Orthogonal Regression (STOR) with quality control for Optimizing the RFM of High-Resolution Satellite Imagery. In: Photogrammetric Engineering and Remote Sensing 83(9): 611-620.
Abstract: There are two major problems in Rational Function Model (RFM) solution: (a) Data source error, including gross error, random error, and systematic error; and (b) Model error, including over-parameterization and over-correction issues caused by unnecessary RFM parameters and exaggeration of random error in constant term of error-in-variables (EIV) model, respectively. In order to solve two major problems simultaneously, we propose a new approach named stepwise-thenorthogonal regression (STOR) with quality control. First, RFM parameters are selected by stepwise regression with gross error detection. Second, the revised orthogonal distance regression is utilized to adjust random error and address the overcorrection problem. Third, systematic error is compensated by Fourier series. The performance of conventional strategies and the proposed STOR are evaluated by control and check grids generated from SPOT5 high-resolution imagery. Compared with the least squares regression, partial least squares regression, ridge regression, and stepwise regression, the proposed STOR shows a significant improvement in accuracy. [full text] [link]
-
Yanfeng Zhang, , Yunjun ZhangYunjun Zhang, Zongze Zhao. (2017) A Two-Step Semiglobal Filtering Approach to Extract DTM From Middle Resolution DSM. In: IEEE Geoscience and Remote Sensing Letters PP(99): 1-5.
Abstract: Many filtering algorithms have been developed to extract the digital terrain model (DTM) from dense urban light detection and ranging data or the high-resolution digital surface model (DSM), assuming a smooth variation of topographic relief. However, this assumption breaks for a middle-resolution DSM because of the diminished distinction between steep terrains and nonground points. This letter introduces a two-step semiglobal filtering (TSGF) workflow to separate those two components. The first SGF step uses the digital elevation model of the Shuttle Radar Topography Mission to obtain a flat-terrain mask for the input DSM; then, a segmentation-constrained SGF is used to remove the nonground points within the flat-terrain mask while maintaining the shape of the terrain. Experiments are conducted using DSMs generated from Chinese ZY3 satellite imageries, verified the effectiveness of the proposed method. Compared with the conventional progressive morphological filter method, the usage of flat-terrain mask reduced the average root-mean-square error of DTM from 9.76 to 4.03 m, which is further reduced to 2.42 m by the proposed TSGF method. [full text] [link]
-
Yi Wan, . (2017) The P2L method of mismatch detection for push broom high-resolution satellite images. In: ISPRS Journal of Photogrammetry and Remote Sensing 130: 317-328.

Abstract: RANSAC-based mismatch detection methods are widely used in the geometric registration of images. Despite their prevalence, setting the detection thresholds for different situations continues to be difficult without an appropriate geometric model. In high-resolution satellite images, simple image-space transformations are commonly influenced by the terrain or elevation errors. This paper introduces a new method, called the P2L method, which uses the distance between the transformed right image point and the segment of the corresponding epipolar line to distinguish the correct matches and mismatches. The affine model of the P2L method is solved to transform the right image points towards the segment of the epipolar line. The images for demonstration were acquired by GeoEye-1, Ikonos-2, and Ziyuan-3; and each type of image pairs had different intersection angles to explore the influence of the elevation error. The correct matches were manually collected and the mismatches were simulated. The experiments in this paper, which used only correct matches, demonstrated that this method was very robust with one specific threshold (five pixels) and was suitable for all the image pairs. The experiments using simulated mismatches and real matching points demonstrated that this method was able to distinguish most of the mismatches; and even for the image pair that had a 54-degree intersection angle, the ratio of mismatches was reduced from 81% to 11%. [full text] [link]
-
Daifeng Peng, . (2017) Object-based change detection from satellite imagery by segmentation optimization and multi-features fusion. In: International Journal of Remote Sensing 38(13): 3886-3905.

Abstract: This article presents a novel object-based change detection (OBCD) approach in high-resolution remote-sensing images by means of combining segmentation optimization and multi-features fusion. In the segmentation optimization, objects with optimized boundaries and proper sizes are generated by object intersection and merging (OIM) processes, which ensures the accurate information extraction from image objects. Within multi-features fusion and change analysis, the Dempster and Shafer (D-S) evidence theory and the Expectation-Maximization (EM) algorithm are implemented, which effectively utilize multidimensional features besides avoiding the selection of an appropriate change threshold. The main advantages of our proposed method lie in the improvement of object boundary and the fuzzy fusion of multi-features information. The proposed approach is evaluated using two different high-resolution remote-sensing data sets, and the qualitative and quantitative analyses of the results demonstrate the effectiveness of the proposed approach. [full text] [link]
-
Rujun Cao, , Xinyi Liu, Zongze Zhao. (2017) Roof plane extraction from airborne lidar point clouds. In: International Journal of Remote Sensing 38(12): 3684-3703.
Abstract: Planar patches are important primitives for polyhedral building models. One of the key challenges for successful reconstruction of three-dimensional (3D) building models from airborne lidar point clouds is achieving high quality recognition and segmentation of the roof planar points. Unfortunately, the current automatic extraction processes for planar surfaces continue to suffer from limitations such as sensitivity to the selection of seed points and the lack of computational efficiency. In order to address these drawbacks, a new fully automatic segmentation method is proposed in this article, which is capable of the following: (1) processing a roof point dataset with an arbitrary shape; (2) robustly selecting the seed points in a parameter space with reduced dimensions; and (3) segmenting the planar patches in a sub-dataset with similar attributes when region growing in the object space. The detection of seed points in the parameter space was improved by mapping the accumulator array to a 1D space. The range for region growing in the object space was reduced by an attribute similarity measure that split the roof dataset into candidate and non-candidate subsets. The experimental results confirmed that the proposed approach can extract planar patches of building roofs robustly and efficiently. [full text] [link]
-
Rujun Cao, , Xinyi Liu, Zongze Zhao. (2017) 3D Building Roof Reconstruction from Airborne LiDAR Point Clouds--a Framework Based on a Spatial Database. In: International Journal of Geographical Information Science, 31(7): 1359-1380.

Abstract: Three-dimensional (3D) building models are essential for 3D Geographic Information Systems and play an important role in various urban management applications. Although several light detection and ranging (LiDAR) data-based reconstruction approaches have made significant advances toward the fully automatic generation of 3D building models, the process is still tedious and time-consuming, especially for massive point clouds. This paper introduces a new framework that utilizes a spatial database to achieve high performance via parallel computation for fully automatic 3D building roof reconstruction from airborne LiDAR data. The framework integrates data-driven and model-driven methods to produce building roof models of the primary structure with detailed features. The framework is composed of five major components: (1) a density-based clustering algorithm to segment individual buildings, (2) an improved boundary-tracing algorithm, (3) a hybrid method for segmenting planar patches that selects seed points in parameter space and grows the regions in spatial space, (4) a boundary regularization approach that considers outliers and (5) a method for reconstructing the topological and geometrical information of building roofs using the intersections of planar patches. The entire process is based on a spatial database, which has the following advantages: (a) managing and querying data efficiently, especially for millions of LiDAR points, (b) utilizing the spatial analysis functions provided by the system, reducing tedious and time-consuming computation, and (c) using parallel computing while reconstructing 3D building roof models, improving performance. [full text] [link]
-
Lei Yu, , Mingwei Sun, Yihui Lu. (2017) Automatic Reference Image Selection for Color Balancing in Remote Sensing Imagery Mosaic. In: IEEE Geoscience and Remote Sensing Letters PP(99): 1-5.

Abstract: Selection of a reference image is an important step in color balancing. However, the past research and currently available methods do not focus on it, leading to the lack of an effective way to select the reference image for color balancing in remote sensing imagery mosaic. This letter proposes a novel automatic reference image selection method that aims to select the reference images by assessing multifactors according to the land surface types of the target images. The proposed method addresses the limitations caused by the use of a single assessment factor as well as the selection of a single image as the reference in traditional methods. In addition, the proposed method has a wider range of applications than those requiring no reference image. The visual experimental results indicate that the proposed method can select the suitable reference images, which benefits the color balancing result, and outperforms the other comparative methods.Moreover, the absolute mean value of skewness metric of the proposed method is 0.0831, which is lower than the values of the other comparison methods. It indicates that the result of the proposed method had the best performance in the color information. The quantitative analyses with the metric of absolute difference of mean value indicate that the proposed method has a good ability in maintaining the spectral information, and the spectral changing rates had been reduced at least 10.66% by the proposed method when compared with the other methods. [full text] [link]
-
, Lei Yu, Mingwei Sun, Xinyu Zhu. (2017) A Mixed Radiometric Normalization Method for Mosaicking of High-Resolution Satellite Imagery. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.55 No.5: 2972 - 2984.

Abstract: A new mixed radiometric normalization (MRN) method is introduced in this paper which aims to eliminate the radiometric difference in image mosaicking. The radiometric normalization methods can be classified as the absolute and relative approaches in traditional solutions. Though the absolute methods could get the precise surface reflectance values of the images, rigorous conditions required for them are usually difficult to obtain, which makes the absolute methods impractical in many cases. The relative methods, which are simple and practicable, are more widely applied. However, the standard for designating the reference image needed for these methods is not unified. Moreover, the color error propagation and the two-body problems are common obstacles for the relative methods. The proposed MRN approach combines absolute and relative radiometric normalization methods, by which the advantages of both can be fully used and the limitations can be effectively avoided. First, suitable image after absolute radiometric calibration is selected as the reference image. Then, the invariant feature probability between the pixels of the target image and that of the reference image is obtained. Afterward, an adaptive local approach is adopted to obtain a suitable linear regression model for each block. Finally, a bilinear interpolation method is employed to obtain the radiometric calibration parameters for each pixel. Moreover, the CIELAB color space is adopted to evaluate the results quantitatively. Experimental results of ZY-3, GF-1, and GF-2 data indicate that the proposed method can eliminate the radiometric differences between images from the same or even different sensors. [full text] [link]
-
Yanfeng Zhang, , Delin Mo, Yi Zhang, Xin Li. (2017) Direct Digital Surface Model Generation by Semi-Global Vertical Line Locus Matching. In: Remote Sensing, 214-233.

Abstract: As the core issue for Digital Surface Model (DSM) generation, image matching is often implemented in photo space to get disparity or depth map. However, DSM is generated in object space with additional processes such as reference image selection, disparity maps fusion or depth maps merging, and interpolation. This difference between photo space and object space leads to process complexity and computation redundancy. We propose a direct DSM generation approach called the semi-global vertical line locus matching (SGVLL), to generate DSM with dense matching in the object space directly. First, we designed a cost function, robust to the pre-set elevation step and projection distortion, and detected occlusion during cost calculation to achieve a sound photo-consistency measurement. Then, we proposed an improved semi-global cost aggregation with guidance of true-orthophoto to obtain superior results at weak texture regions and slanted planes. The proposed method achieves performance very close to the state-of-the-art with less time consumption, which was experimentally evaluated and verified using nadir aerial images and reference data. [full text] [link]
-
Daifeng Peng, . (2017) Object-based change detection method using refined Markov random field. In: Journal of Applied Remote Sensing, Vol.11 No.1: 016024-1-11.
Abstract: In order to fully consider the local spatial constraints between neighboring objects in object-based change detection (OBCD), an OBCD approach is presented by introducing a refined Markov random field (MRF). First, two periods of images are stacked and segmented to produce image objects. Second, object spectral and textual histogram features are extracted and G-statistic is implemented to measure the distance among different histogram distributions. Meanwhile, object heterogeneity is calculated by combining spectral and textual histogram distance using adaptive weight. Third, an expectation-maximization algorithm is applied for determining the change category of each object and the initial change map is then generated. Finally, a refined change map is produced by employing the proposed refined object-based MRF method. Three experiments were conducted and compared with some state-of-the-art unsupervised OBCD methods to evaluate the effectiveness of the proposed method. Experimental results demonstrate that the proposed method obtains the highest accuracy among the methods used in this paper, which confirms its validness and effectiveness in OBCD. [full text] [link]
-
Dongliang Wang, Wei Cao, Xiaoping Xin, Quanqin Shao, Matthew Brolly, Jianhua Xiao, . (2017) Using Vector Building Maps to Aid in Generating Seams for Low-Attitude Aerial Orthoimage Mosaicking. In: Journal of Applied Remote Sensing, Vol.125: 207-224.

Abstract: A novel seam detection approach based on vector building maps is presented for low-attitude aerial orthoimage mosaicking. The approach tracks the centerlines between vector buildings to generate the candidate seams that avoid crossing buildings existing in maps. The candidate seams are then refined by considering their surrounding pixels to minimize the visual transition between the images to be mosaicked. After the refinement of the candidate seams, the final seams further bypass most of the buildings that are not updated into vector maps. Finally, three groups of aerial imagery from different urban densities are employed to test the proposed approach. The experimental results illustrate the advantages of the proposed approach in avoiding the crossing of buildings. The computational efficiency of the proposed approach is also significantly higher than that of Dijkstra's algorithm. [full text] [link]
-
Yansheng Li, , Chao Tao, Hu Zhu. (2016) Content-Based High-Resolution Remote Sensing Image Retrieval via Unsupervised Feature Learning and Collaborative Affinity Metric Fusion. In: Remote Sensing, 8(9): ID 709.
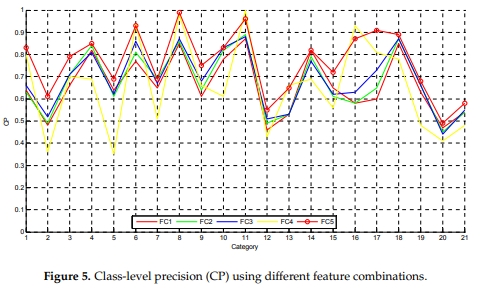
Abstract: With the urgent demand for automatic management of large numbers of high-resolution remote sensing images, content-based high-resolution remote sensing image retrieval (CB-HRRS-IR) has attracted much research interest. Accordingly, this paper proposes a novel high-resolution remote sensing image retrieval approach via multiple feature representation and collaborative affinity metric fusion (IRMFRCAMF). In IRMFRCAMF, we design four unsupervised convolutional neural networks with different layers to generate four types of unsupervised features from the fine level to the coarse level. In addition to these four types of unsupervised features, we also implement four traditional feature descriptors, including local binary pattern (LBP), gray level co-occurrence (GLCM), maximal response 8 (MR8), and scale-invariant feature transform (SIFT). In order to fully incorporate the complementary information among multiple features of one image and the mutual information across auxiliary images in the image dataset, this paper advocates collaborative affinity metric fusion to measure the similarity between images. The performance evaluation of high-resolution remote sensing image retrieval is implemented on two public datasets, the UC Merced (UCM) dataset and the Wuhan University (WH) dataset. Large numbers of experiments show that our proposed IRMFRCAMF can significantly outperform the state-of-the-art approaches. [full text] [link]
-
Yansong Duan, Xu Huang, Jinxing Xiong, , Bo Wang. (2016) A combined image matching method for Chinese optical satellite imagery. In: International Journal of Digital Earth, 9(9): 851-872.
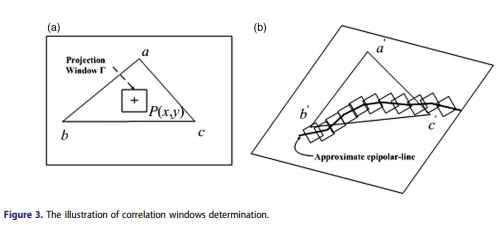
Abstract: Image matching is one of the key technologies for digital Earth. This paper presents a combined image matching method for Chinese satellite images. This method includes the following four steps: (1) a modified Wallis-type filter is proposed to determine parameters adaptively while avoiding over-enhancement; (2) a mismatch detection procedure based on a global-local strategy is introduced to remove outliers generated by the Scale-invariant feature transform algorithm, and geometric orientation with bundle block adjustment is employed to compensate for the systematic errors of the position and attitude observations; (3) we design a novel similarity measure (distance, angle and the Normalized Cross-Correlation similarities, DANCC) which considers geometric similarity and textural similarity; and (4) we introduce a hierarchical matching strategy to refine the matching result level by level. Four typical image pairs acquired from Mapping Satellite-1, ZY-1 02C, ZY-3 and GeoEye-1, respectively, are used for experimental analysis. A comparison with the two current main matching algorithms for satellite imagery confirms that the proposed method is capable of producing reliable and accurate matching results on different terrains from not only Chinese satellite images, but also foreign satellite images. [full text] [link]
-
Lei Yu, . (2016) Colour Balancing of Satellite Imagery Based on Colour Reference Library. In :International Journal of Remote Sensing, Vol.37 N.o2: 5763-5785.
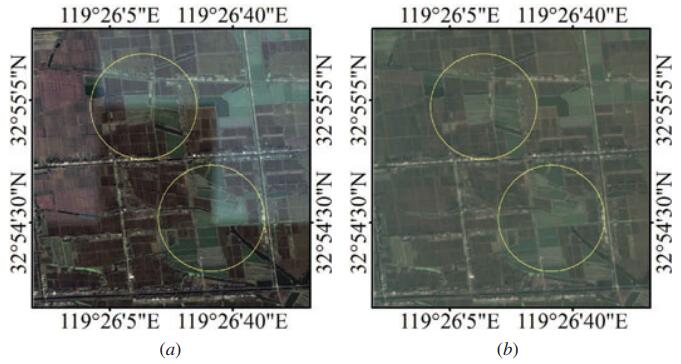
Abstract: Generating mosaics of images obtained at different times is a challenging task because of the radiometric differences between the adjacent images introduced by the solar incident angle, atmosphere, and illumination condition. For most of the existing colour-balancing methods, the standard for determining the reference image is not unified, thus yielding different calibration results. Besides, traditional methods may suffer from colour error propagation and the two-body problems. A novel colour-balancing method for satellite imagery based on a colour reference library is proposed in this article, which aims to eliminate the effect of colour difference between different images for visually appealing and seamless image mosaicking. The proposed method contains two parts: the establishment of a colour reference library and the colour-balancing method based on it. Colour reference library is a database storing colour and other related information from the existing mosaic imagery. The colour information of the existing mosaic imagery is visually appealing and consistent with human visual perception. By automatically selecting appropriate colour reference information from the colour reference library according to the geographical scope and acquisition season information of the target images, the proposed approach provides effective solutions for choosing suitable reference image, colour error propagation, and the two-body problem in traditional colour-balancing methods. Experimental results demonstrate that the proposed approach performs well in the colour-balancing process. [full text] [link]
-
Kai Tan, , Xin Tong. (2016) Cloud Extraction from Chinese High Resolution Satellite Imagery by Probabilistic Latent Semantic Analysis and Object-Based Machine Learning. In: Remote Sensing, Vol.8 No11 :963.
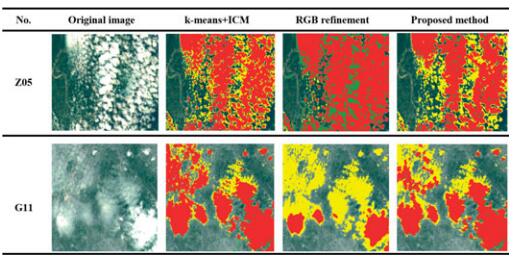
Abstract: Automatic cloud extraction from satellite imagery is a vital process for many applications in optical remote sensing since clouds can locally obscure the surface features and alter the reflectance. Clouds can be easily distinguished by the human eyes in satellite imagery via remarkable regional characteristics, but finding a way to automatically detect various kinds of clouds by computer programs to speed up the processing efficiency remains a challenge. This paper introduces a new cloud detection method based on probabilistic latent semantic analysis (PLSA) and object-based machine learning. The method begins by segmenting satellite images into superpixels by Simple Linear Iterative Clustering (SLIC) algorithm while also extracting the spectral, texture, frequency and line segment features. Then, the implicit information in each superpixel is extracted from the feature histogram through the PLSA model by which the descriptor of each superpixel can be computed to form a feature vector for classification. Thereafter, the cloud mask is extracted by optimal thresholding and applying the Support Vector Machine (SVM) algorithm at the superpixel level. The GrabCut algorithm is then applied to extract more accurate cloud regions at the pixel level by assuming the cloud mask as the prior knowledge. When compared to different cloud detection methods in the literature, the overall accuracy of the proposed cloud detection method was up to 90 percent for ZY-3 and GF-1 images, which is about a 6.8 percent improvement over the traditional spectral-based methods. The experimental results show that the proposed method can automatically and accurately detect clouds using the multispectral information of the available four bands. [full text] [link]
-
Maoteng Zheng, Junfeng Zhu, Xiaodong Xiong, Shunping Zhou, . (2016) 3D Model Reconstruction with Common Hand-held Cameras. In: Virtual Reality, Vol.20: 2211-235.
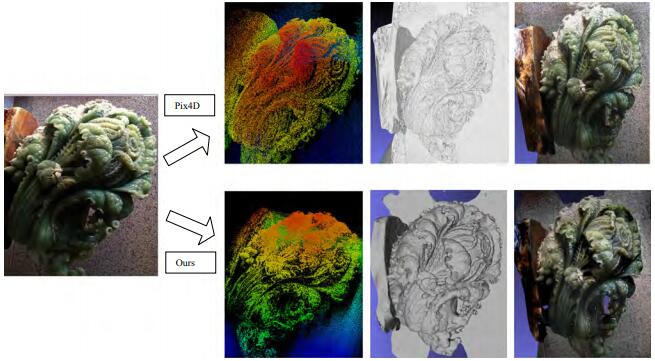
Abstract: A 3D model reconstruction workflow with hand-held cameras is developed. The exterior and interior orientation models combined with the state-of-the-art structure from motion and multi-view stereo techniques are applied to extract dense point cloud and reconstruct 3D model from digital images. An overview of the presented 3D model reconstruction methods is given. The whole procedure including tie point extraction, relative orientation, bundle block adjustment, dense point production and 3D model reconstruction is all reviewed in brief. Among them, we focus on bundle block adjustment procedure; the mathematical and technical details of bundle block adjustment are introduced and discussed. Finally, four scenes of images collected by hand-held cameras are tested in this paper. The preliminary results have shown that sub-pixel (< 1 pixel) accuracy can be achieved with the proposed exterior-interior orientation models and satisfactory 3D models can be reconstructed using images collected by hand-held cameras. This work can be applied in indoor navigation, crime scene reconstruction, heritage reservation and other applications in geosciences. [full text] [link]
-
Xiao Ling, , Jinxin Xiong, Xu Huang, Zhipeng Chen. (2016) An Image Matching Algorithm Integrating Global SRTM and Image Segmentation for Multi-Source Satellit. In: Remote Sensing,672-690.
Abstract: This paper presents a novel image matching method for multi-source satellite images, which integrates global Shuttle Radar Topography Mission (SRTM) data and image segmentation to achieve robust and numerous correspondences. This method first generates the epipolar lines as a geometric constraint assisted by global SRTM data, after which the seed points are selected and matched. To produce more reliable matching results, a region segmentation-based matching propagation is proposed in this paper, whereby the region segmentations are extracted by image segmentation and are considered to be a spatial constraint. Moreover, a similarity measure integrating Distance, Angle and Normalized Cross-Correlation (DANCC), which considers geometric similarity and radiometric similarity, is introduced to find the optimal correspondences. Experiments using typical satellite images acquired from Resources Satellite-3 (ZY-3), Mapping Satellite-1, SPOT-5 and Google Earth demonstrated that the proposed method is able to produce reliable and accurate matching results. [full text] [link]
-
Yansheng Li, , Chao Tao, Hu Zhu. (2016) A Novel Spatio-Temporal Saliency Approach for Robust Dim Moving Target Detection from Airborne Infrared Image Sequences. In: International Journal of Remote Sensing, Vol.369: 548-563.
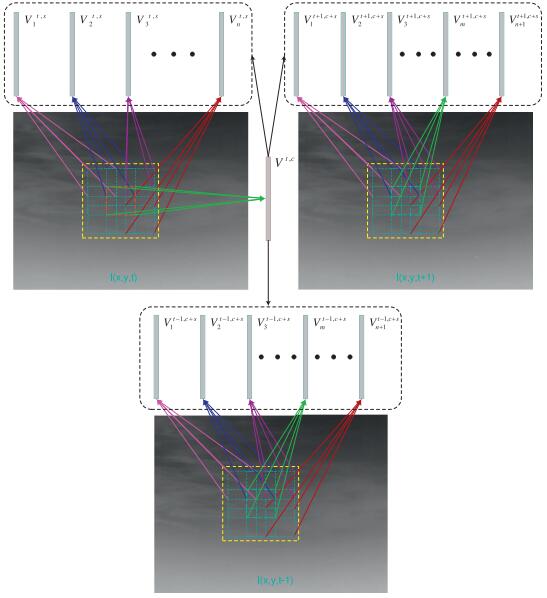
Abstract: Dim moving target detection from infrared image sequences, which lags behind the visual perception ability of humans, has attracted considerable interest from researchers due to its crucial role in airborne surveillance systems. This paper proposes a novel spatio-temporal saliency model to cope with the infrared dim moving target detection problem. Based on a closed-form solution derived from regularized feature reconstruction, a local adaptive contrast operation is proposed, whereby the spatial saliency map and the temporal saliency map can be calculated on the spatial domain and the temporal domain. In order to depict the motion consistency characteristic of the moving target, this paper also proposes a transmission operation to generate the trajectory prediction map. The fused result of the spatial saliency map, the temporal saliency map, and the trajectory prediction map is called the “spatio-temporal saliency map” in this paper, from which the target of interest can be easily segmented. A diverse test dataset comprised of three infrared image sequences under different backgrounds was collected to evaluate the proposed model; and extensive experiments confirmed that the proposed spatio-temporal saliency model can achieve much better detection performance than the state-of-the-art approaches. [full text] [link]
-
Maoteng Zheng, , ShunpingZhou, JunfengZhu, XiaodongXiong. (2016) Bundle block adjustment of large-scale remote sensing data with Block-based Sparse Matrix Compression combined with Preconditioned Conjugate Gradient. In: Computers and Geosciences, Vol.92: 70-78.
Abstract: In recent years, new platforms and sensors in photogrammetry, remote sensing and computer vision areas have become available, such as Unmanned Aircraft Vehicles (UAV), oblique camera systems, common digital cameras and even mobile phone cameras. Images collected by all these kinds of sensors could be used as remote sensing data sources. These sensors can obtain large-scale remote sensing data which consist of a great number of images. Bundle block adjustment of large-scale data with conventional algorithm is very time and space (memory) consuming due to the super large normal matrix arising from large-scale data. In this paper, an efficient Block-based Sparse Matrix Compression (BSMC) method combined with the Preconditioned Conjugate Gradient (PCG) algorithm is chosen to develop a stable and efficient bundle block adjustment system in order to deal with the large-scale remote sensing data. The main contribution of this work is the BSMC-based PCG algorithm which is more efficient in time and memory than the traditional algorithm without compromising the accuracy. Totally 8 datasets of real data are used to test our proposed method. Preliminary results have shown that the BSMC method can efficiently decrease the time and memory requirement of large-scale data. [full text] [link]
-
Chang Li, . (2016) Automatic Keyline Recognition and 3D Reconstruction for Quasi-planar Facades in Close-range Images. In: The Photogrammetric Record, Vol.31 No.153: 29-50.

Abstract: Critical keylines, such as concave and convex edges of a building façade, can be lost in photogrammetric recognition procedures. To solve this problem and to reconstruct quasi-planar 3D façades automatically and precisely, a set of algorithms and techniques for the automatic recognition of lines and 3D reconstruction is proposed. This includes: (1) a procedure for line-segment matching that satisfies the spatial requirements of a 3D scene based on “global independence” and “local dependence”; (2) a technique of generalised point bundle block adjustment combined with spatial line constraints (in the form of virtual observations) to control the propagation of error; and (3) the methods of perceptual organisation, plane fitting and plane-plane intersection are suggested to acquire the critical keylines corresponding to concave and convex building edges. Experimental results show that these new algorithms are feasible and applicable to recognition and 3D reconstruction. Recommendations for recognition methods are provided depending on whether or not a priori topological relationships are available between the planes under consideration. [full text] [link]
-
,Yi Wan. (2016) DEM-assisted RFM Block Adjustment of Pushbroom Nadir Viewing HRS Imagery. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.54 No.2: 1025-1034.
Abstract: Nadir viewing satellite image is an effective data source to generate orthomosaics. Because of the georeferencing error of satellite images, block adjustment is the first step of orthomosaic generation over a large area. However, the geometric relationship of the neighboring orbits of the nadir viewing images is not rigid enough. This paper proposes a new rational function model (RFM) block adjustment approach that constrains the tie point elevation to enhance the relative geometric rigidity. By interpolating the elevations of tie points in a digital elevation model(DEM) and estimating the a priori errors of the interpolated elevations, better overall relative accuracy is obtained, and the local optimal solution problem is avoided. By constraining the adjustedmodel parameters according to the a priori error of RFMs, block adjustment without ground control point (GCP) is performed. By optimal initializing the object-space positions of tie points with multi-backprojection method, the needed iteration times of block adjustment are reduced. The proposed approach is investigated with 46 Ziyuan-3 sensor-corrected images, a 1:50 000 scale DEM, and 586 GCPs. Compared with Teo's approach that constrains the horizontal coordinates and elevations of tie points, the approach in this paper converges much faster when the GCPs are sparse, and meanwhile, the absolute and relative accuracy of the two approaches are almost the same. The result of block adjustment with only four GCPs shows that no accuracy degeneration occurred in the test area and the root-mean-square error of independent check point reaches about 1.5 ground resolutions. Different DEMs and number of tie points are used to investigate whether the block adjustment result is influenced by these factors. The results show that better DEM accuracy and denser tie points do improve the accuracy when the images have large side-sway angles. The proposed approach is also tested with 5118 IKONOS-2 images that cover the southern Europe without GCP. The result shows that the relative mosaicking accuracy is much better than that of Grodecki's approach. [full text] [link]
-
Zongze Zhao, Yansong Duan, , Rujun Cao. (2016) Extracting Buildings from and Regularizing Boundaries in Airborne LiDAR Data Using Connected Operators. In:International Journal of Remote Sensing, Vol.37 No 4 :889-912.

Abstract: The location of building boundary is a crucial prerequisite for geographical condition monitoring, urban management, and building reconstruction. This paper presents a framework that employs a series of algorithms to automatically extract building footprints from airborne (light detection and ranging (lidar)) data and image. Connected operators are utilized to extract building regions from lidar data, which would not produce new contours nor change their position and have very good contour-preservation properties. First, the building candidate regions are separated from lidar-derived digital surface model (DSM) based on a new method proposed within this paper using connected operators, and trees are removed based on the normalized difference vegetation index (NDVI) value of image. Then, building boundaries are identified and building boundary lines are traced by 'sleeve' line simplification method. Finally, the principal directions of buildings are used to regularize the directions of building boundary lines. International Society for Photogrammetry and Remote Sensing (ISPRS) data sets in Vaihingen whose point spacing is about 0.4 m from urbanized areas were employed to test the proposed framework, and three test areas were selected. A quantitative analysis showed that the method proposed within this paper was effective and the average offset values of simple and complex building boundaries were 0.2-0.4 m and 0.3-0.6 m, respectively. [full text] [link]
-
Maoteng Zheng,. (2016) DEM-Aided Bundle Adjustment with Multisource Satellite Imagery: ZY-3 and GF-1 in Large Areas. In:IEEE Geoscience and Remote Sensing Letters, Vol.13 No.6: 880-884.
Abstract: In this letter, a new digital elevation model (DEM)-aided bundle block adjustment (BBA) method is proposed which utilizes a rational-polynomial-coefficient affine transformation model and a preconditioned conjugate gradient (PCG) algorithm with multisource satellite imagery (ZY-3 and GF-1) for producing and updating ortho maps of large areas. To deal with the weak geometry of the large blocks, a reference DEM is used in this method as an additional constraint in the BBA. The PCG algorithm is applied to solve the large normal matrix produced by the massive data of the large areas. Our proposed method was tested on three blocks of real data collected by GF-1 panchromatic and multispectral sensors and ZY-3 three-line-camera sensors. The preliminary results show that the proposed method can achieve an accuracy of better than 0.5 pixels in planimetry and is suitable for wide application in ortho-map production. It also has great potential for the ortho-map production of superlarge areas such as the country of China as one block. [full text] [link]
-
, Qian Li, Hongshu Lu, Xinyi Liu, Xu Huang, Chao Song, Shan Huang, Jingyi Huang.(2015) Optimized 3D Street Scene Reconstruction from Driving Recorder Image. In: Remote Sensing, Vol.7: 091-9121.
Abstract: The paper presents an automatic region detection based method to reconstruct street scenes from driving recorder images. The driving recorder in this paper is a dashboard camera that collects images while the motor vehicle is moving. An enormous number of moving vehicles are included in the collected data because the typical recorders are often mounted in the front of moving vehicles and face the forward direction, which can make matching points on vehicles and guardrails unreliable. Believing that utilizing these image data can reduce street scene reconstruction and updating costs because of their low price, wide use, and extensive shooting coverage, we therefore proposed a new method, which is called the Mask automatic detecting method, to improve the structure results from the motion reconstruction. Note that we define vehicle and guardrail regions as “mask” in this paper since the features on them should be masked out to avoid poor matches. After removing the feature points in our new method, the camera poses and sparse 3D points that are reconstructed with the remaining matches. Our contrast experiments with the typical pipeline of structure from motion (SfM) reconstruction methods, such as Photosynth and VisualSFM, demonstrated that the Mask decreased the root-mean-square error (RMSE) of the pairwise matching results, which led to more accurate recovering results from the camera-relative poses. Removing features from the Mask also increased the accuracy of point clouds by nearly 30%–40% and corrected the problems of the typical methods on repeatedly reconstructing several buildings when there was only one target building. [full text] [link]
-
Xiang Shen,, Xiao Lu, Qian Xie, Qingquan Li. (2015) An Improved Method for Transforming GPS/INS Attitude to National Map Projection Frame. In: IEEE Geoscience and Remote Sensing Letters, Vol.12 No.6: 1302-1306.
Abstract: Global Positioning System/Inertial Navigation System (GPS/INS) integrated navigation systems play a very important role in modern photogrammetry and laser scanning by virtue of their capability of direct measurement of high-precision position and attitude data in the WGS 84 datum. In practice, as georeferencing is often conducted in national coordinates, there is a need to transform GPS/INS data to the required national map projection frame first. This letter presents an improved coordinate-transformation-based method for the GPS/INS attitude transformation by taking the datum scale distortion and the length distortion into account. Experimental results show that the transformation errors of our improved method are on the order of magnitude of 1 x 10-5°, which can be safely ignored in aerial photogrammetric processing, whereas the maximum error of the previous coordinate-transformation-based method can be up to several 0.001°. [full text] [link]
-
Xiang Shen,, Qingquan Li. (2015) Accurate Direct Georeferencing of Aerial Imagery in National Coordinates. In: ISPRS Journal of Photogrammetry and Remote Sensing, Vol.105 No.3: 13-18.
Abstract: In aerial photogrammetry, data products are commonly needed in national coordinates, and, in practice, the georeferencing is often performed in the required national map projection frame directly. However, as a map projection frame is not Cartesian, some additional corrections are necessary in the georeferencing process to take account of various map projection distortions. This paper presents a new map projection correction method for the direct georeferencing of aerial images in national coordinates, which comprises of three consecutive steps: (1) a rough intersection to predict ground point coordinates in the Cartesian space; (2) calculating map projection corrections; and (3) a fine intersection. Benefiting from the explicit estimation of ground positions in the Cartesian space, our new method can directly adopt the accurate map projection distortion model that was previously developed for the direct georeferencing of airborne LiDAR data in national coordinates. Simulations show that the correction residuals of our new method are smaller by one order of magnitude than those of the previous best approach while their computational costs are at the same level, and even in an extreme scenario of 8000 m flight height above ground, the maximum error of our method is only several centimeters, which can be safely neglected in practical applications. [full text] [link]
-
Maoteng Zheng,. (2015) Self-Calibration Adjustment of CBERS-02B Long Strip Imagery. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.53 No.7: 3847-3854.
Abstract: Due to hardware limitations, such as the poor accuracy of its onboard Global Positioning System receiver and star tracks, the direct georeferencing accuracy of the China and Brazil Earth Resource Satellite 02B (CBERS-02B) by its onboard position and attitude measurements is less than 1000 m at times. Thus, the image data cannot be directly used in surveying applications. This paper presents a self-calibration bundle adjustment strategy to improve the georeferencing accuracy of the onboard high-resolution camera (HRC). An adequate number of automatically matched ground control points (GCPs) are used to perform the bundle adjustment. Both the systematic error compensation model and the orientation image model along with the interior self-calibration parameters are used in the bundle adjustment to eliminate the systematic errors. A self-calibration strategy is used to compensate for the time delay and integrated charge-coupled device translation and rotation errors by introducing a total of ten interior orientation parameters. The preliminary results show that the accuracy of self-calibration bundle adjustment is two pixels better than that of bundle adjustment without self-calibration, and the planimetric accuracy of the check points is about 10 m. The unusual variations of the exterior orientation parameters in some cases are eliminated after enlarging the orientation image intervals and increasing the weights of the onboard position and attitude observations. [full text] [link]
-
, Xiaodong Xiong, Maoteng Zheng. (2015) LiDAR Strip Adjustment Using Multifeatures Matched with Aerial Images. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.53 No.2: 976-987.

Abstract: Airborne light detecting and ranging (LiDAR) systems have been widely used for the fast acquisition of dense topographic data. Regrettably, coordinate errors always exist in LiDAR-acquired points. The errors are attributable to several sources, such as laser ranging errors, sensor mounting errors, and position and orientation system (POS) systematic errors, among others. LiDAR strip adjustment (LSA) is the solution to eliminating the errors, but most state-of-the-art LSA methods neglect the influence from POS systematic errors by assuming that the POS is precise enough. Unfortunately, many of the LiDAR systems used in China are equipped with a low-precision POS due to cost considerations. Subsequently, POS systematic errors should be also considered in the LSA. This paper presents an aerotriangulation-aided LSA (AT-aided LSA) method whose major task is eliminating position and angular errors of the laser scanner caused by boresight angular errors and POS systematic errors. The aerial images, which cover the same area with LiDAR strips, are aerotriangulated and serve as the reference data for LSA. Two types of conjugate features are adopted as control elements (i.e., the conjugate points matched between the LiDAR intensity images and the aerial images and the conjugate corner features matched between LiDAR point clouds and aerial images). Experiments using the AT-aided LSA method are conducted using a real data set, and a comparison with the three-dimensional similarity transformation (TDST) LSA method is also performed. Experimental results support the feasibility of the proposed AT-aided LSA method and its superiority over the TDST LSA method. [full text] [link]
-
, Maoteng Zheng, Xiaodong Xiong, Jinxin Xiong. (2015) Multi-strips Bundle Block Adjustment of ZY-3 Satellite Imagery by Rigorous Sensor Model. In: IEEE Geoscience and Remote Sensing Letters, Vol.12 No.4: 865-869.
Abstract: Extensive applications of Zi-Yuan 3 (ZY-3) satellite imagery of China have commenced since its on-orbit test was finished. Most of the data are processed scene by scene with a few ground control points (GCPs) for each scene; this conventional method is mature and widely used all over the world. However, very little work has focused on its application to super large area blocks. This letter aims to study mapping applications without GCPs for a super large area, which is defined as a range of interprovincial or even nationwide areas. The automatic matching and bundle block adjustment (BBA) software developed by our research team are applied to deal with two blocks of ZY-3 three-line camera imagery which covers most of the provinces in eastern China. Our comparison analysis of different data processing methods and the geolocation accuracies of the overlapped areas between adjacent strips are presented in this letter, as well as the possibility of nationwide BBA. The preliminary test results show that multistrip BBA without GCPs can achieve accuracies of about 13-15 m in both planimetry and height, which means that nationwide BBA is considered practical and feasible. [full text] [link]
-
Xiangyun Hu, Yijing Li, Jie Shan, Jianqing Zhang, . (2014) Road Centerline Extraction in Complex Urban Scenes From LiDAR Data Based on Multiple Features. In: IEEE Transactions on Geoscience and Remote Sensing, 52(11): 7448-7456.
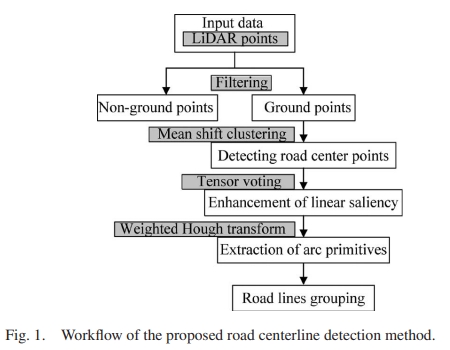
Abstract: Automatic extraction of roads from images of complex urban areas is a very difficult task due to the occlusions and shadows of contextual objects, and complicated road structures. As light detection and ranging (LiDAR) data explicitly contain direct 3-D information of the urban scene and are less affected by occlusions and shadows, they are a good data source for road detection. This paper proposes to use multiple features to detect road centerlines from the remaining ground points after filtering. The main idea of our method is to effectively detect smooth geometric primitives of potential road centerlines and to separate the connected nonroad features (parking lots and bare grounds) from the roads. The method consists of three major steps, i.e., spatial clustering based on multiple features using an adaptive mean shift to detect the center points of roads, stick tensor voting to enhance the salient linear features, and a weighted Hough transform to extract the arc primitives of the road centerlines. In short, we denote our method as Mean shift, Tensor voting, Hough transform (MTH). We evaluated the method using the Vaihingen and Toronto data sets from the International Society for Photogrammetry and Remote Sensing Test Project on Urban Classification and 3-D Building Reconstruction. The completeness of the extracted road network on the Vaihingen data and the Toronto data are 81.7% and 72.3%, respectively, and the correctness are 88.4% and 89.2%, respectively, yielding the best performance compared with template matching and phase-coded disk methods. [full text] [link]
-
, Bo Wang, Zuxun Zhang, Yansong Duan, Yong Zhang, Mingwei Sun, Shunping Ji. (2014) Fully Automatic Generation of Geo-information Products with Chinese ZY-3 Satellite Imagery. In: The Photogrammetric Record, Vol.29 No.148: 383-401.

Abstract: The advantages of continuously and soundly obtaining large multidimensional, multiscale and multitemporal observation datasets from satellite remote sensing make it indispensable in building a national spatial data infrastructure. This paper introduces the ZY-3 satellite developed in China and discusses a fully automatic data-processing system to generate geoinformation products, such as digital elevation models (DEMs) and digital orthophotomaps (DOMs), based on ZY-3 imagery. The key technologies of automatic geoinformation product generation, including strip image-based bundle adjustment together with creating DEMs and DOMs, are illustrated. The accuracies of the georeferencing and automatically generated geoinformation products are also discussed. This automatic data-processing system is shown to provide a good foundation for near real-time derivation of such geoinformation products and for the promotion and application of Chinese domestic satellites. [full text] [link]
-
Xiaodong Xiong, , Junfeng Zhu, Maoteng Zheng. (2014) Camera Pose Determination and 3D Measurement from Monocular Oblique Images with Horizontal Right Angle Constraints. In: IEEE Geoscience and Remote Sensing Letters, Vol.11 No.11: 1976-1980.
Abstract: This letter introduces a novel method for camera pose determination from monocular urban oblique images. Horizontal right angles that widely exist in urban scenes are used as geometric constraints in the camera pose determination, and the proposed 3-D measurement method using a monocular image is presented and then used to check the accuracy of the recovered image's exterior orientation parameters. Compared to the available vertical-line-based camera pose determination method, our new method is more accurate. [full text] [link]
-
, Maoteng Zheng, Xu Huang, Jinxin Xiong. (2014) Bundle Block Adjustment of Airborne Three-Line Array Imagery Based on Rotation Angles. In: Sensors, Vol.14: 8189-8202.

Abstract: In the midst of the rapid developments in electronic instruments and remote sensing technologies, airborne three-line array sensors and their applications are being widely promoted and plentiful research related to data processing and high precision geo-referencing technologies is under way. The exterior orientation parameters (EOPs), which are measured by the integrated positioning and orientation system (POS) of airborne three-line sensors, however, have inevitable systematic errors, so the level of precision of direct geo-referencing is not sufficiently accurate for surveying and mapping applications. Consequently, a few ground control points are necessary to refine the exterior orientation parameters, and this paper will discuss bundle block adjustment models based on the systematic error compensation and the orientation image, considering the principle of an image sensor and the characteristics of the integrated POS. Unlike the models available in the literature, which mainly use a quaternion to represent the rotation matrix of exterior orientation, three rotation angles are directly used in order to effectively model and eliminate the systematic errors of the POS observations. Very good experimental results have been achieved with several real datasets that verify the correctness and effectiveness of the proposed adjustment models. [full text] [link]
-
, Xiang Shen. (2014) Quantitative Analysis on Geometric Size of LiDAR Footprint. In: IEEE Geoscience and Remote Sensing Letters, Vol.11 No.3: 701-705.
Abstract: A light detection and ranging (LiDAR) footprint is the spot area illuminated by a single laser beam, which varies with the beam direction and the regional terrain encountered. The geometric size of the LiDAR footprint is one of the most critical parameters of LiDAR point cloud data. It plays a very important role in the high-precision geometric and radiometric calibration of LiDAR systems. This letter utilizes space analytic geometry to derive LiDAR footprint equations and strictly considers laser beam attitude and terrain slope. Compared to the conventional plane geometry solution, the proposed approach is not only more rigorous in theory but also more powerful in practical applications. [full text] [link]
-
, Maoteng Zheng, Jinxin Xiong, Yihui Lu, Xiaodong Xiong. (2014) On-Orbit Geometric Calibration of ZY-3 Three-Line Array Imagery With Multistrip Data Sets. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.52 No.1: 224-234.

Abstract: ZY-3, which was launched on January 9, 2012, is the first stereo mapping satellite in China. The initial accuracy of direct georeferencing with the onboard three-line camera (TLC) imagery is low. Sensor geometric calibration with bundle block adjustment is used to improve the georeferencing accuracy. A new on-orbit sensor calibration method that can correct the misalignment angles between the spacecraft and the TLC and the misalignment of charge-coupled device is described. All of the calibration processes are performed using a multistrip data set. The control points are automatically matched from existing digital ortho map and digital elevation model. To fully evaluate the accuracy of different calibration methods, the calibrated parameters are used as input data to conduct georeferencing and bundle adjustment with a total of 19 strips of ZY-3 TLC data. A systematic error compensation model is introduced as the sensor model in bundle adjustment to compensate for the position and attitude errors. Numerous experiments demonstrate that the new calibration model can largely improve the external accuracy of direct georeferencing from the kilometer level to better than 20 m in both plane and height. A further bundle block adjustment with medium-accuracy ground control points (GCPs), using these calibrated parameters, can achieve external accuracy of about 4 m in plane and 3 m in height. Higher accuracy of about 1.3 m in plane and 1.7 m in height can be achieved by bundle adjustment using high-accuracy GCPs. [full text] [link]
-
Luping Lu, Yong Zhang, Pengjie Tao, Zuxun Zhang, . (2013) Estimation of Transformation Parameters between Centre-Line Vector Road Maps and High Resolution Satellite Images. In: The Photogrammetric Record, 28(142): 130-144.
Abstract: A method for automatically estimating the transformation parameters between road centre-line vector maps and high resolution satellite images is proposed. The advantages of the method are that global image feature extraction is avoided and feature extraction and matching are achieved simultaneously by using the vector data as guidance. The road width, as estimated by the algorithm, together with the road direction are used as constraints to refine the matching results. Arbitrarily chosen road nodes contribute to improving the adjustment. Map-to-image matching has advantages over image‐to‐image matching and could be a good method for the rapid updating of geographical information system (GIS) data. [full text] [link]
-
Xiangyun Hu, Xiaokai Li, . (2013) Fast Filtering of LiDAR Point Cloud in Urban Areas Based on Scan Line Segmentation and GPU Acceleration. In: IEEE Geoscience and Remote Sensing Letters, 10(2): 308-312.
Abstract: The fast filtering of massive point cloud data from light detection and ranging (LiDAR) systems is important for many applications, such as the automatic extraction of digital elevation models in urban areas. We propose a simple scan-line-based algorithm that detects local lowest points first and treats them as the seeds to grow into ground segments by using slope and elevation. The scan line segmentation algorithm can be naturally accelerated by parallel computing due to the independent processing of each line. Furthermore, modern graphics processing units (GPUs) can be used to speed up the parallel process significantly. Using a strip of a LiDAR point cloud, with up to 48 million points, we test the algorithm in terms of both error rate and time performance. The tests show that the method can produce satisfactory results in less than 0.6 s of processing time using the GPU acceleration. [full text] [link]
-
, Xiang Shen. (2013) Direct georeferencing of airborne LiDAR data in national coordinates. In: ISPRS Journal of Photogrammetry and Remote Sensing, Vol.84: 43-51.
Abstract: The topographic mapping products of airborne light detection and ranging (LiDAR) are usually required in the national coordinates (i.e., using the national datum and a conformal map projection). Since the spatial scale of the national datum is usually slightly different from the World Geodetic System 1984 (WGS 84) datum, and the map projection frame is not Cartesian, the georeferencing process in the national coordinates is inevitably affected by various geometric distortions. In this paper, all the major direct georeferencing distortion factors in the national coordinates, including one 3D scale distortion (the datum scale factor distortion), one height distortion (the earth curvature distortion), two length distortions (the horizontal-to-geodesic length distortion and the geodesic-to-projected length distortion), and three angle distortions (the skew-normal distortion, the normal-section-to-geodesic distortion, and the arc-to-chord distortion) are identified and demonstrated in detail; and high-precision map projection correction formulas are provided for the direct georeferencing of the airborne LiDAR data. Given the high computational complexity of the high-precision map projection correction approach, some more approximate correction formulas are also derived for the practical calculations. The simulated experiments show that the magnitude of the datum scale distortion can reach several centimeters to decimeters for the low (e.g., 500 m) and high (e.g., 8000 m) flying heights, and therefore it always needs to be corrected. Our proposed practical map projection correction approach has better accuracy than Legat's approach,1 but it needs 25% more computational cost. As the correction accuracy of Legat's approach can meet the requirements of airborne LiDAR data with low and medium flight height (up to 3000 m above ground), our practical correction approach is more suitable to the high-altitude aerial imagery. The residuals of our proposed high-precision map projection correction approach are trivial even for the high flight height of 8000 m. It can be used for the theoretical applications such as the accurate evaluation of different GPS/INS attitude transformation methods to the national coordinates. [full text] [link]
-
, Kun Hu, Zuxun Zhang, Tao Ke, Shan Huang. (2013) Precise Calibration of a Rotation Photogrammetric System. In: Geo-spatial Information Science, Vol.16 No.2: 69-74.
Abstract: Rotation photogrammetric systems are widely used for 3D information acquisition, where high-precision calibration is one of the critical steps. This study first shows how to derive the rotation model and deviation model in the object space coordinate system according to the basic structure of the system and the geometric relationship of the related coordinate systems. Then, overall adjustment of multi-images from a surveying station is employed to calibrate the rotation matrix and the deviation matrix of the system. The exterior orientation parameters of images captured by other surveying stations can be automatically calculated for 3D reconstruction. Finally, real measured data from Wumen wall of the Forbidden City is employed to verify the performance of the proposed calibration method. Experimental results show that this method is accurate and reliable and that a millimetre level precision can be obtained in practice. [full text] [link]
-
, Xiang Shen. (2013) Approximate Correction of Length Distortion for Direct Georeferencing in Map Projection Frame. In: IEEE Geoscience and Remote Sensing Letters, Vol.10 No.6: 1419-1423.
Abstract: Many geometric distortions, such as earth curvature distortion and length distortion, exist in the map projection frame. Therefore, in aerial photogrammetry, if direct georeferencing is performed in the map projection frame, the crucial work becomes compensating for the effect of the various geometric distortions. This letter mainly focuses on length distortion and proposes two new correction approaches: the changing image coordinates method and the changing object coordinates method. The experimental results show that the changing object coordinates method is less influenced by terrain fluctuation, and its correction accuracy is therefore commonly higher than the changing image coordinates method as well as two existing approaches (i.e., the changing flight height method and the changing focal length method). [full text] [link]
-
, Liwen Lin, Maoteng Zheng, Jinxin Xiong. (2013) Combined Bundle Block Adjustment with Spaceborne Linear Array and Airborne Frame Array Imagery. In: The Photogrammetric Record, Vol.28 No.145: 162-177.
Abstract: The integration of multi-source earth observation data has become one of the most important developments in photogrammetry. A combined adjustment with linear array and frame array imagery (CALFI) is established in this paper. The mathematical model of CALFI is based on the conventional single-source bundle adjustment. A revised recursive partitioning technique is utilised to solve the large normal matrix of CALFI; the orientation parameters of the linear array imagery are arranged at the border of the reduced normal matrix to save both memory and computation time. The experimental results on simulated data show that both the accuracy and the condition index of the CALFI model are superior to the conventional bundle adjustment model with either linear array or frame array imagery separately due to the higher redundancy. [full text] [link]
-
, Kun Hu, Rongyong Huang. (2012) Bundle Adjustment with Additional Constraints Applied to Imagery of the Dunhuang Wall Paintings. In: ISPRS Journal of Photogrammetry and Remote Sensing, Vol.72 No.1: 113-120.
Abstract: In the digital conservation of the Dunhuang wall painting, bundle adjustment is a critical step in precise orthoimage generation. The error propagation of the adjustment model is accelerated because the near-planar photographic object intensifies correlation of the exterior orientation parameters and the less than 60% forward overlap of adjacent images weakens the geometric connection of the network. According to the photographic structure adopted in this paper, strong correlation of the exterior orientation parameters can be verified theoretically. In practice, the additional constraints of near-planarity and exterior orientation parameters are combined with bundle adjustment to control the error propagation. The positive effects of the additional constraints are verified by experiments, which show that the introduction of weighted observation equations into bundle adjustment contributes a great deal to the theoretical and actual accuracies of the unknowns as well as the stability of the adjustment model. [full text] [link]
-
, Xiaodong Xiong, Xiang Shen, Zheng Ji.(2012) Bundle Block Adjustment of Weakly Connected Aerial Imagery. In: Photogrammetric Engineering and Remote Sensing, Vol.78 No.9: 983-989.
Abstract: In aerial photogrammetry of island and reef areas, traditional aerial triangulation cannot be performed because many images in the block are partially or even completely covered by water, and thus there are not enough tie points among adjacent images. To solve this problem, an effective algorithm of position and orientation system (POS) integrated bundle block adjustment is proposed. The exterior orientation parameters of each image are modeled as functions of corresponding POS observations and their estimated systematic errors. A POS integrated bundle adjustment model is designed with the purpose of effectively eliminating the systematic errors of inertial measurement unit observations. Experimental results of three sets of island aerial images show that the proposed approach can compensate for the systematic errors of POS observations effectively. The topo-graphic mapping requirements of hilly terrain at 1:2 000 scale can be fulfilled, provided that at least one ground control point is used in the bundle adjustment. [full text] [link]
-
, Yihui Lu, Lei Wang, and Xu Huang. (2012) A New Approach on Optimization of the Rational Function Model of High Resolution Satellite Imagery. In: IEEE Transactions on Geoscience and Remote Sensing, Vol.50 No.7: 2758-2764.
Abstract: Overparameterization is one of the major problems that the rational function model (RFM) faces. A new approach of RFM parameter optimization is proposed in this paper. The proposed RFM parameter optimization method can resolve the ill-posed problem by removing all of the unnecessary parameters based on scatter matrix and elimination transformation strategies. The performances of conventional ridge estimation and the proposed method are evaluated with control and check grids generated from Satellites d'observation de la Terre (SPOT-5) high-resolution satellite data. Experimental results show that the precision of the proposed method, with about 35 essential parameters, is 10% to 20% higher than that of the conventional model with all 78 parameters. Moreover, the ill-posed problem is effectively alleviated by the proposed method, and thus, the stability of the estimated parameters is significantly improved. [full text] [link]
-
, Xu Huang, Xiangyun Hu, Fangqi Wan, Liwen Lin. (2011) Direct Relative Orientation with Four Independent Constraints. In: ISPRS Journal of Photogrammetry and Remote Sensing, Vol.66 No.6: 809-817.

Abstract: Relative orientation based on the coplanarity condition is one of the most important procedures in photogrammetry and computer vision. The conventional relative orientation model has five independent parameters if interior orientation parameters are known. The model of direct relative orientation contains nine unknowns to establish the linear transformation geometry, so there must be four independent constraints among the nine unknowns. To eliminate the influence of over parameterization of the conventional direct relative orientation model, a new relative orientation model with four independent constraints is proposed in this paper. The constraints are derived from the inherent orthogonal property of the rotation matrix of the right image of a stereo pair. These constraints are completely new as compared with the known literature. The proposed approach can find the optimal solution under least squares criteria. Experimental results show that the proposed approach is superior to the conventional model of direct relative orientation, especially at low altitude and close range photogrammetric applications. [full text] [link]
-
, Binghua Hu, Jianqing Zhang. (2011) Relative Orientation Based on Multi-features. In: ISPRS Journal of Photogrammetry and Remote Sensing, Vol.66 No.5: 700-707.

Abstract: In digital photogrammetry, corresponding points have been widely used as the basic source of information to determine the relative orientation parameters among adjacent images. Sometimes, though, the conventional relative orientation process cannot be precisely implemented due to the accumulation of random errors or in the case of inadequate corresponding points. A new relative orientation approach with multiple types of corresponding features, including points, straight lines, and circular curves, is proposed in this paper. The origin of the model coordinate system is set at the projection center of the first image of a strip, and all of the exterior orientation parameters, except and ω of the first image, are set at zero. The basic models of relative orientation with corresponding points, straight lines, and circular curves are discussed, and the general form of a least squares adjustment model for relative orientation based on multi-features is established. Our experimental results show that the proposed approach is feasible and can achieve more reliable relative orientation results than the conventional approach based on corresponding points only. [full text] [link]
-
, Zuxun Zhang, Mingwei Sun, Tao Ke. (2011) Precise Orthoimage Generation of Dunhuang Wall Painting. In: Photogrammetric Engineering and Remote Sensing, Vol.77 No.6: 631-640.

Abstract: Wall painting plays an important role in the culture relics of the Mogao Caves in Dunhuang, P.R. China. A novel approach of generating a high-resolution orthoimage of the wall painting is proposed. Since the photographic object is nearly flat and also the forward overlap between adjacent images is smaller than 60 percent, the main difficulty to be resolved is the high correlation problem among the unknowns. Improved models of relative orientation and bundle adjustment with virtual constraints have been developed to resolve the high correlation problem. A Voronoi diagram of projective footprints is applied to automatically determine the mosaic lines of ortho-rectified images. The color quality of the generated orthoimage is improved through global minimization of the color differences among overlapped images. The experimental results show that the proposed approach has great potential for conservation of wall paintings with sub-millimeter to millimeter precision. [full text] [link]
-
, Jinxin Xiong, Lijuan Hao. (2011) Photogrammetric Processing of Low-altitude Images Acquired by Unpiloted Aerial Vehicles. In: The Photogrammetric Record, Vol.26 No.134: 190-211.

Abstract: Low-altitude images acquired by unpiloted aerial vehicles have the advantages of high overlap, multiple viewing angles and very high ground resolution. These kinds of images can be used in various applications that need high accuracy or fine texture. A novel approach is proposed for parallel processing of low-altitude images acquired by unpiloted aerial vehicles, which can automatically fly according to predefined flight routes under the control of an autopilot system. The general overlap and relative rotation angles between two adjacent images are estimated by overall matching with an improved scale-invariant feature transform (SIFT) operator. Precise conjugate points and relative orientation parameters are determined by a pyramid-based least squares image matching strategy and the relative orientation process. Bundle adjustment is performed with automatically matched conjugate points and interactively measured ground control points. After this aerial triangulation process the high-resolution images can be used to advantage in obtaining precise spatial information products such as digital surface models, digital orthophotomaps and 3D city models. A parallel processing strategy is introduced in this paper to improve the computational time of the photogrammetric process. Experimental results show that the proposed approaches are effective for processing low-altitude images, and have high potential for the acquisition of spatial information at large mapping scales, with rapid response and precise modelling in three dimensions. [full text] [link]
-
Zuxun Zhang, , Tao Ke, Dahai Guo. (2009) Photogrammetry for First Response in Wenchuan Earthquake. In: Photogrammetric Engineering and Remote Sensing, Vol.75 No.5: 510-513.
Abstract: To inspect the damages caused by the Wenchuang earthquake on May 12, 2008, aerial photography was practiced in an unconventional manner. The f ight was largely irregular, along the roads, in cities and towns in order to obtain the f rst-time damage information about main roads, bridges and other transportation infrastructure . Hovering f ight is necessary to get more ground information about residential areas when the plane is over the city. All this challenges for advanced techniques to process such collected images in a timely manner. Some key algorithms and data-processing mechanisms in conventional practices should be upgraded to meet this need. This paper mainly focuses on the rapid data processing and applications of mass unconventional aerial images in Wenchuan earthquake relief and emergency response. [full text] [link]
-
Zuxun Zhang, , Jianqing Zhang. (2008) Photogrammetric Modelling of Linear Features with Generalized Point Photogrammetry. In: Photogrammetric Engineering and Remote Sensing, Vol.74 NO.9: 1119-1129.

Abstract: Most current digital photogrammetric workstations are based on feature points. Curved features are quite difficult to be modeled because they cannot be treated as feature points. The focus of the paper is on the photogrammetric modeling of space linear features. In general, lines and curves can be represented by a series of connected points, so called, generalized points in the paper. Different from all existing models, only one collinearity equation is used for each point on the linear curve, which makes the mathematical model very simple. Hereby, the key of generalized point photogrammetry is that all kinds of features are treated as generalized points to use either x or y collinearity equation. A significant difference between generalized point photogrammetry and conventional point photogrammetry is that image features are not necessarily exact conjugates. The exact conjugacy between image features and/or the correspondence between space and image feature are established during bundle block adjustment. Photogrammetric modeling of several space linear features is discussed. Sub-pixel precision has been achieved for both exterior orientation and 3D modeling of linear features, which verifies the correctness and effectiveness of the proposed approach. [full text] [link]
-
, Zuxun Zhang, Jianqing Zhang. (2006) Automatic Measurement of Industrial Sheetmetal Parts with CAD Data and Non-metric Image Sequence. In: Computer Vision and Image Understanding, Vol. 102 No.1: 52-59.
Abstract: A novel approach for three-dimensional (3D) reconstruction and measurement of industrial sheetmetal parts with computer aided design (CAD) data and non-metric image sequence is proposed. The purpose of our approach is to automatically reconstruct and measure the producing imprecision or deformations of industrial parts that are mainly composed of line segments, circles, connected arcs and lines. Principles of two-dimensional (2D) and one-dimensional (1D) least squares template matching to extract precise lines and points are presented. Hybrid point-line photogrammetry is adopted to obtain accurate wire frame model of industrial parts. Circles, arcs, and lines connected to each other on the part are reconstructed with direct object space solution according to known camera parameters. The reconstructed CAD model can be used for visual measurement. Experimental results of several parts are very satisfying. They show that the proposed approach has a promising potential in automatic 3D reconstruction and measurement of widely existed industrial parts mainly composed of lines, circles, connected arcs and lines. [full text] [link]
-
, Christian Heipke, Matthias Butenuth, Xiangyun Hu. (2006) Automatic Extraction of Wind Erosion Obstacles by Integration of GIS Data, DSM and Stereo Images. In: International Journal of Remote Sensing, Vol.27 No.8: 1677-1690.

Abstract: Integrating multiple data sources is a very important strategy to obtain relevant solutions in geo‐scientific analysis. This paper mainly deals with the integration of Geographical Information System (GIS) data, stereo aerial imagery and a Digital Surface Model (DSM) to extract wind erosion obstacles (namely tree rows and hedges) in open landscapes. Different approaches, such as image segmentation, edge extraction, linking, grouping and 3‐dimensional verification with the DSM, are combined to extract the objects of interest. Experiments show that most wind erosion obstacles can be successfully extracted by the developed system. [full text] [link]
-
, Zuxun Zhang, Jianqing Zhang, Jun Wu. (2005) 3D Building Modelling with Digital Map, LIDAR Data and Video Image Sequences. In: The Photogrammetric Record, Vol.20 NO.111: 285-302.

Abstract: Three‐dimensional (3D) reconstruction and texture mapping of buildings or other man‐made objects are key aspects for 3D city landscapes. An effective coarse‐to‐fine approach for 3D building model generation and texture mapping based on digital photogrammetric techniques is proposed. Three video image sequences, two oblique views of building walls and one vertical view of building roofs, acquired by a digital video camera mounted on a helicopter, are used as input images. Lidar data and a coarse two‐dimensional (2D) digital vector map used for car navigation are also used as information sources. Automatic aerial triangulation (AAT) suitable for a high overlap image sequence is used to give initial values of camera parameters of each image. To obtain accurate image lines, the correspondence between outlines of the building and their line features in the image sequences is determined with a coarse‐to‐fine strategy. A hybrid point/line bundle adjustment is used to ensure the stability and accuracy of reconstruction. Reconstructed buildings with fine textures superimposed on a digital elevation model (DEM) and ortho‐image are realistically visualised. Experimental results show that the proposed approach of 3D city model generation has a promising future in many applications. [full text] [link]
-
. (2005) Automatic Inspection of Industrial Sheetmetal Parts with Single Non-metric CCD Camera. In: Lecture Notes in Artificial Intelligence, No.3584: 654-661.

Abstract: A novel approach for three-dimensional reconstruction and inspection of industrial parts with image sequence acquired by single non-metric CCD camera is proposed. The purpose of the approach is to reconstruct and thus inspect the producing imprecision (of deformation) of industrial sheetmetal parts. Planar control grid, non-metric image sequence and CAD-designed data are used as information sources. Principles of least squares template matching to extract lines and points from the imagery are presented. Hybrid point-line photogrammetry is adopted to obtain the accurate wire frame model. Circles, connected arcs and lines on the part are reconstructed with direct object space solution. The reconstructed CAD model can be used for inspection or quality control. Experimental results are very satisfying. [full text] [link]
-
, Zuxun Zhang, Jianqing Zhang. (2004) Deformation Visual Inspection of Industrial Parts with Image Sequence. In: Machine Vision and Applications, Vol.15 No.3: 115-120.
Abstract: A new approach to reconstructing and inspecting the deformation of industrial parts, especially sheetmetal parts based on CAD-designed data and hybrid point-line bundle adjustment with image sequence, is proposed. Nonmetric image sequence and CAD-designed data of parts are used as the source of information. The strategy of our approach is to reconstruct and inspect deformations of parts automatically with image points and line segments extracted from the images. Basic error equation of line photogrammetry and its modified form are addressed in detail. It is shown that when a certain proper weight is selected, adjustment by condition equations and adjustment by observation equations are equivalent for line photogrammetry. A novel hybrid point-line bundle adjustment algorithm is used to reconstruct industrial parts. The proposed hybrid adjustment model can be used in various 3D reconstruction applications of objects mainly composed of points and lines. The developed inspection system is tested with true image data acquired by a CCD camera, and the results are very satisfying. [full text] [link]
-
, Zuxun Zhang, Jianqing Zhang. (2003) Flexible Planar-scene Camera Calibration Technique. In: Wuhan University Journal of Natural Science, Vol.8 No.4: 1090-1096.
Abstract: A flexible camera calibration technique using 2D-DLT and bundle adjustment with planar scenes is proposed. The equation of principal line under image coordinate system represented with 2D-DLT parameters is educed using the correspondence between collinearity equations and 2D-DLT. A novel algorithm to obtain the initial value of principal point is put forward. Proof of Critical Motion Sequences for calibration is given in detail. The practical decomposition algorithm of exterior parameters using initial values of principal point, focal length and 2D-DLT parameters is discussed elaborately. Planar-scene camera calibration algorithm with bundle adjustment is addressed. Very good results have been obtained with both computer simulations and real data calibration. The calibration result can be used in some high precision applications, such as reverse engineering and industrial inspection. [full text] [link]
-
, Jingnan Liu. (2002) Combined GPS/GLONASS Data Processing. In: Geo-Spatial Information Science, Vol.15 No.4: 32-36.
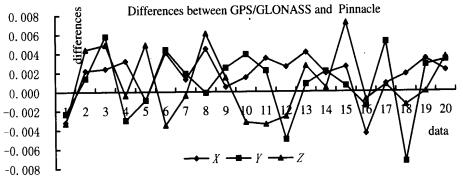
Abstract: To obtain the GLONASS satellite position at an epoch other than reference time, the satellite's equation of motion has to be integrated with broadcasting ephemerides. The iterative detecting and repairing method of cycle slips based on triple difference residuals for combined GPS/GLONASS positioning and the iterative ambiguity resolution approach suitable for combined post processing positioning are discussed systematically. Experiments show that millimeter accuracy can be achieved in short baselines with a few hours' dual frequency or even single frequency GPS/GLONASS carrier phase observations, and the precision of dual frequency observations is distinctly higher than that of single frequency observations. [full text] [link]
-
, Zemin Wang. (2002) Analysis and Solutions of Errors on GPS/GLONASS Positioning. In: Geo-Spatial Information Science, Vol.15 No.2: 6-13.
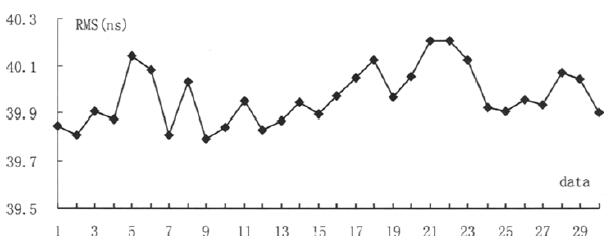
Abstract: This paper focuses mainly on the major errors and their reduction approaches pertaining to combined GPS/GLONASS positioning. To determine the difference in the time reference systems, different receiver clock offsets are introduced with respect to GPS and GLONASS system time. A more desirable method for introducing a independent unknown parameter of fifth receiver, which can be canceled out when forming difference measurements, is dicussed. The error of orbit integration and the error of transformation parameters are addressed in detail. Results of numerical integration are given. To deal with the influence of ionospheric delay, a method for forming dual-frequency ionospheric free carrier phase measurements is detailed. [full text] [link]
-
, Jiaojiao Li, Yiyuan He, Xipeng Shan, Xuezhong Yu, Lei Zhang, Maohong Chen. (2024) 1∶10 000 helicopter aeromagnetic survey and prospecting clues in Taxkorgan iron metallogenic belt, Xinjiang. In: Mineral Deposits 43(05), 1030-1040.
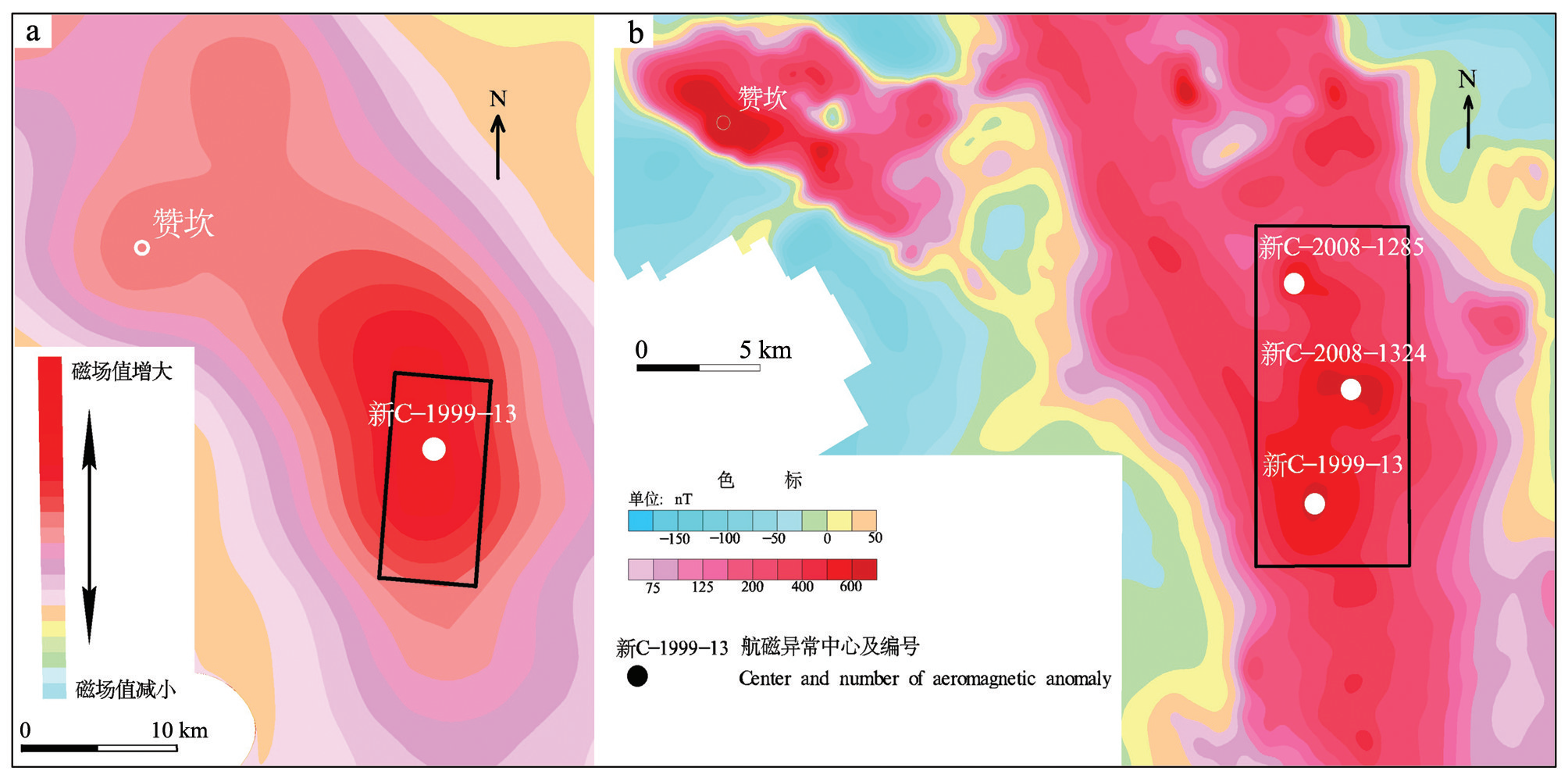
新疆塔什库尔干铁矿带1:1万直升机航磁调查及找矿线索
Abstract: The Taxkorgan metamorphosed sedimentary iron metallogenic belt in Xinjiang is located in the high altitude and sharp topographic Karakoram Mountains. Ore prospecting in this area is a tough challenge in spite of its superior metallogenic geologic conditions due to locating in no-human-zone and poor transportation. 1∶50 000 aeromagnetic survey in study area was finished by using fixed-wing plane. But the average flight altitude is too high (794 m). It’s difficult to discriminate aeromagnetic anomalies caused by magnetite because they are relatively smooth. Helicopter-borne geophysical survey has more advantages in the complicated terrains than fixed-wing plane aero-geophysical survey, for example lower cost, better flexibility, better stability, lower flying altitude to acquire more aero-geophysical information etc. In this paper, we present the results of a 1:10 000 helicopter-borne aeromagnetic survey over aeromagnetic anomaly Xin-C-1999-13,Xin-C-2008-1324 and Xin-C-2008-1285 in no-human-zone of Taxkorgan, which were discovered by 1∶50 000 fixed-wing aeromagnetic survey. Compared with the past data, the newly collected high-precision and high-resolution aeromagnetic data can depict the aeromagnetic anomalies more meticulously. Various anomaly separation techniques were used to decompose aeromagnetic anomalies and some aeromagnetic anomalies maybe caused by magnetite were discriminated. We attempted to use a helicopter to transport personnel to the centre of magnetic anomalies for field geologic reconnaissance immediately after finishing aeromagnetic survey, and discovered floats/boulders of magnetite in the area of aeromagnetic anomaly Xin-C-1999-13. This attempt proves that the helicopter aeromagnetic survey and field magne-tic anomaly verification by helicopter transportation are fast and effective in high altitude and deep cutting mountainous areas. This might offer the valuable reference for the new round of prospecting breakthrough strategy in mineral exploration covering the high altitude, deep cutting and uninhabited mountainous areas. [full text] [link]
-
, Yansheng Li, Bo Dang, Kang Wu, Xin Guo, Jian Wang, Jingdong Chen, Ming Yang. (2024) Multi-modal remote sensing large foundation models: current research status and future prospect. In: Acta Geodaetica et Cartographica Sinica 53(10), 1942-1954.
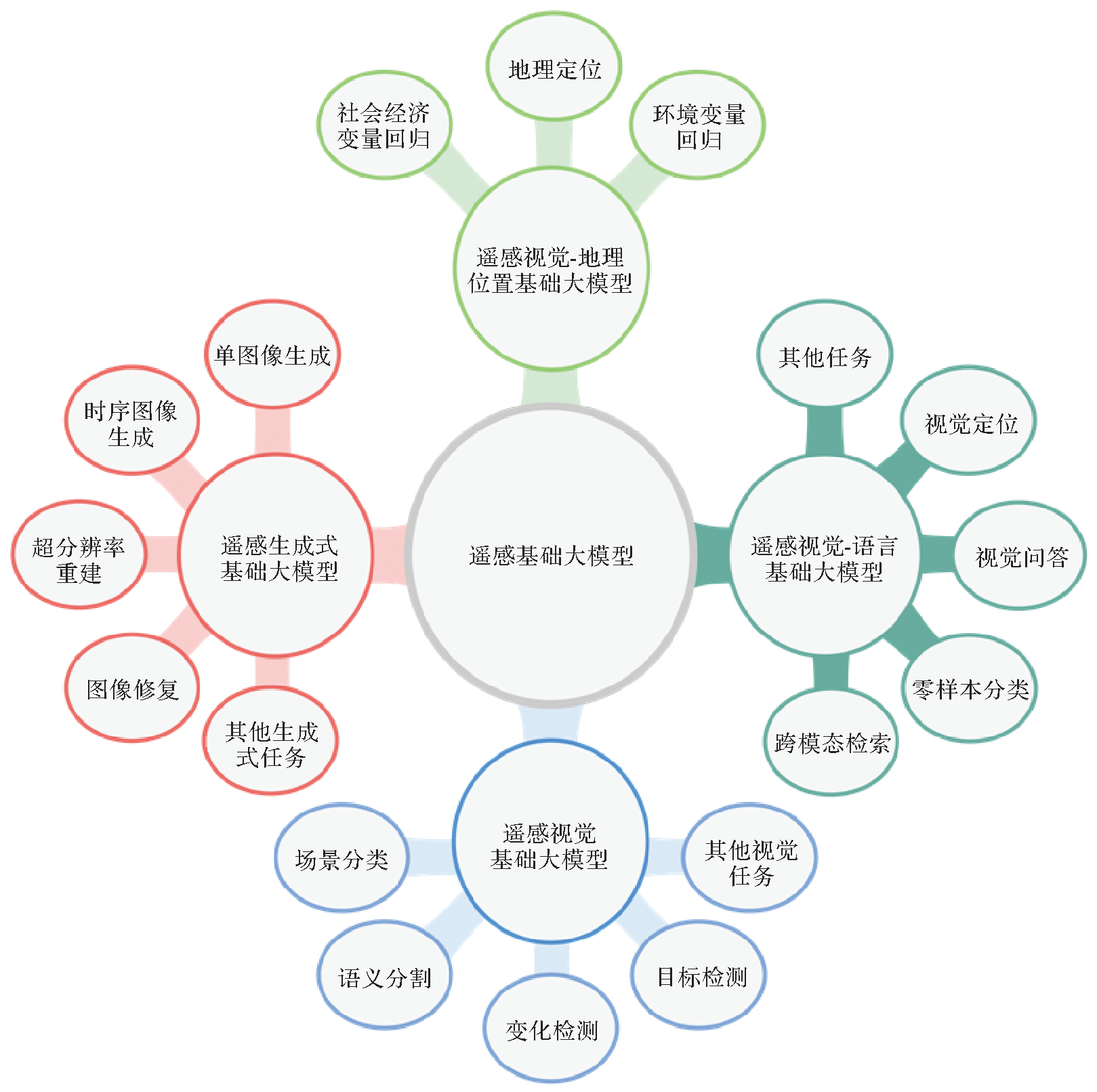
多模态遥感基础大模型:研究现状与未来展望
Abstract: The increasing remote sensing capabilities for Earth observation have eased the access to abundant data and enabled the emergence and development of remote sensing foundation models (RSFMs). Designing distinct deep neural networks and optimizing for different data and task types require substantial development efforts and prohibitively high computational resources. In order to address these issues, researchers in the remote sensing field have shifted their focus to the study of RSFMs and presented many dedicated designed unified models. To enhance the generalizability and interpretability of RSFMs, the integration of extensive geographic knowledge has been recognized as a pivotal/key approach. While existing works have explored or incorporated geographic knowledge into the architecture design or pre-training methods of RSFMs, there lacks of a comprehensive survey to review the current status of geographic knowledge-guided RSFMs. Therefore, this paper starts with summarizing and categorizing large-scale pre-training datasets and then provides an overview of the research progress in this field. Subsequently, we introduce intelligent interpretation algorithms for remote sensing imagery guided by geographic knowledge, along with advancements in the exploration and utilization of geographic knowledge specifically tailored for RSFMs. Finally, several future research prospects are outlined to tackle the persisting challenges in this field, aiming to shed light on future investigations into RSFMs. [full text] [link]
-
Dong Wei, Xinyi Liu, . (2024) The technology and intelligent development of 3D line cloud reconstruction from multiple images. In: Acta Geodaetica et Cartographica Sinica 53(06), 1025-1036.
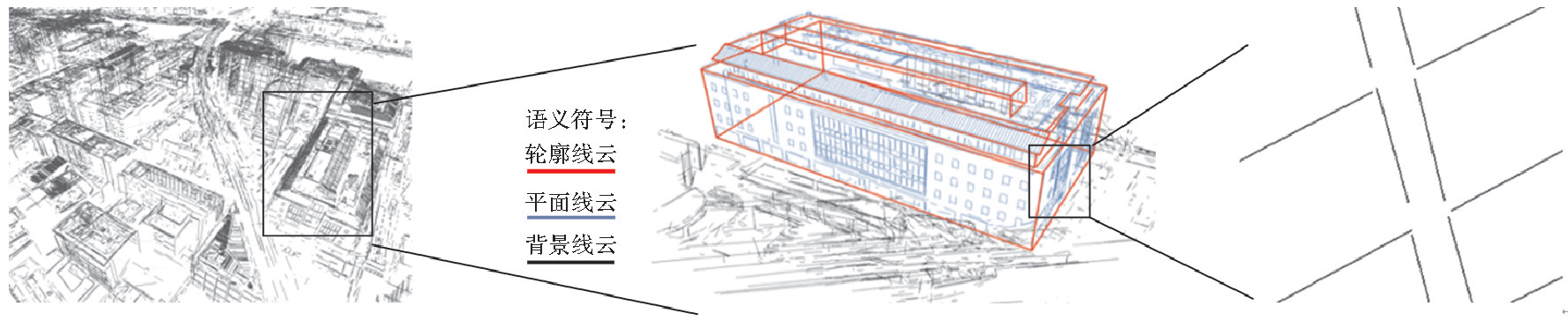
多视影像三维线云重建技术及其智能化发展展望
Abstract: As a collection of line segments, 3D line clouds shave distinct geometric structures and semantic information in each individual feature. They can serve as efficient guiding, controlling, and abstract representation elements in structured 3D reconstruction, compensating for the deficiencies in edge description and lack of initial structure in point clouds. These line clouds represent important structured features that can change the traditional “one-layer skin” 3D model (where different objects are mutually adherent, making spatial analysis and decision-making difficult). However, how to reconstruct useful line clouds from multi-view images and make effective use of them has always been a challenging problem in this field. This article reviews the development of 3D line clouds, introduces related reconstruction methods, and analyzes existing difficulties and shortcomings. Combining the background of transformation from digitization to intelligent surveying and mapping technology, it discusses the three questions of what to build, how to build, and how to use line clouds in real-world 3D scenarios. The article also introduces and prospects the intelligent development of line cloud reconstruction and application, hoping to provide a reference for researchers working on real 3D reconstruction and line clouds. [full text] [link]
-
Yansheng Li, Minlang Wu, . (2024) Knowledge graph-guided deep network for high-resolution remote sensing image scene classification. In: Acta Geodaetica et Cartographica Sinica 53(04), 677-688.
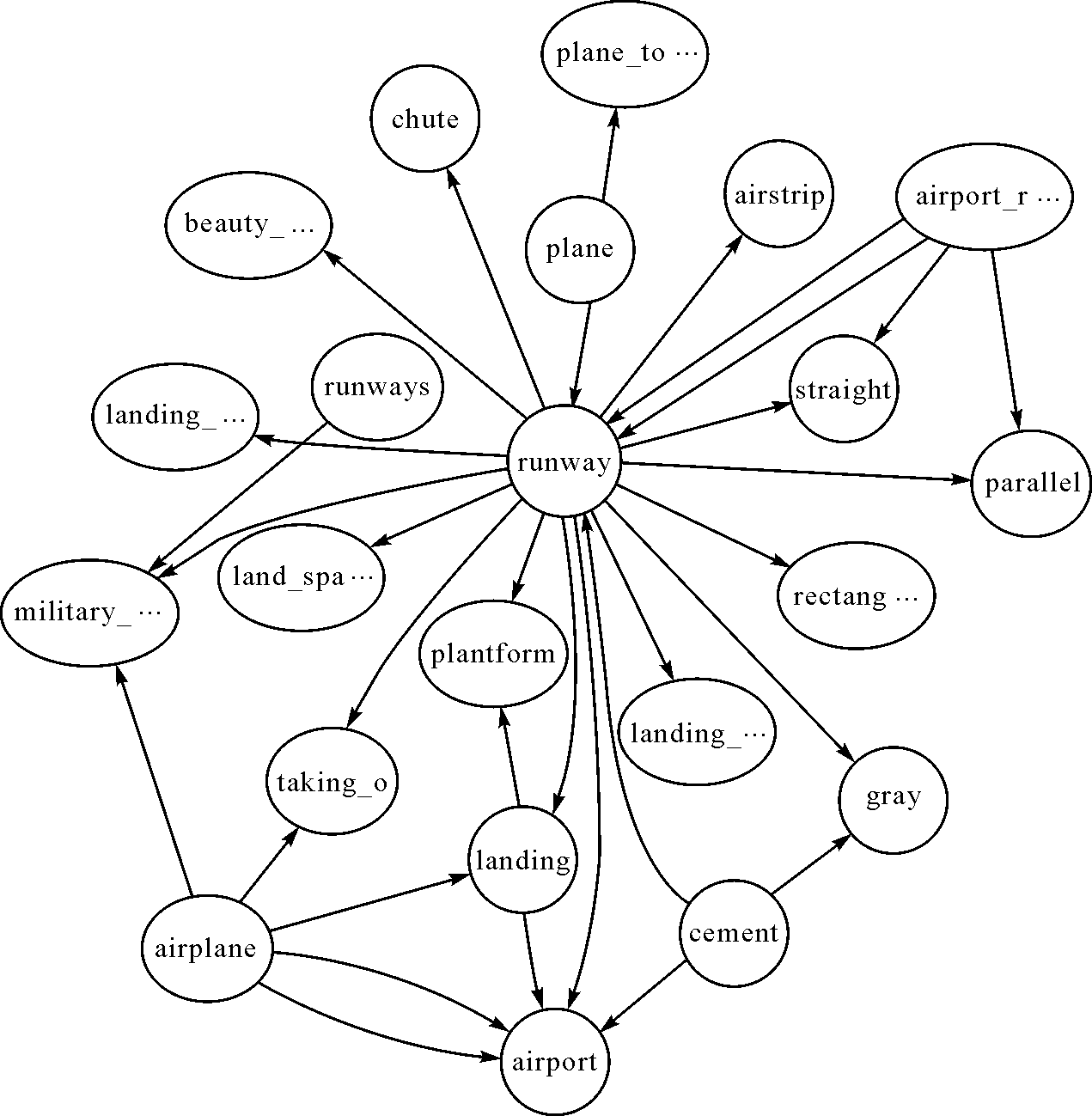
知识图谱约束深度网络的高分辨率遥感影像场景分类
Abstract: Thanks to the rapid development of deep network theory and methods, deep networks have gradually become the mainstream technology for remote sensing image scene classification tasks. However, existing deep network-based remote sensing image scene classification methods are highly dependent on a large number of manually labeled training samples and cannot effectively integrate and utilize the rich prior knowledge in the remote sensing field. In order to improve the utilization of domain knowledge while reducing the dependence on labeled samples, this paper proposes a knowledge graph-guided deep network learning method for high-resolution remote sensing image scene classification. First, this paper constructs a land cover concept knowledge graph that includes various sources of knowledge in the field to more flexibly and conveniently apply domain prior knowledge. Furthermore, through the knowledge graph representation learning method, the semantic categories of remote sensing scenes in the land cover concept knowledge graph are expressed as semantic vectors to form a semantic benchmark for remote sensing scene categories. In the knowledge-guided learning stage, the cross-modal alignment constraint between the scene category semantic vector and the shallow visual feature vector of the deep network is applied to guide the shallow part of the deep network to more effectively learn shared features of different categories of remote sensing image scenes, while in the deep part of the deep network, it is still guided by scene category labels to learn discriminative features of different remote sensing scenes. In the testing stage, the optimized deep network model can complete high-precision remote sensing image scene classification without relying on any prior knowledge. The experimental results on the currently largest publicly available remote sensing image scene classification dataset show that the proposed knowledge-guided learning method can obtain optimal classification performance at different training sample ratios such as 10%, 30%, and 50% compared with existing methods. Under the condition of 10% sample ratio, our proposed method can achieve an improvement of 5.11% in overall accuracy (OA) compared with baseline deep networks. [full text] [link]
-
Yansheng Li, Kang Wu, Song Ouyang, Kun Yang, Heping Li, . (2024) Geographic knowledge graph-guided remote sensing image semantic segmentation. In: Journal of Remote Sensing 28(02), 455-469.
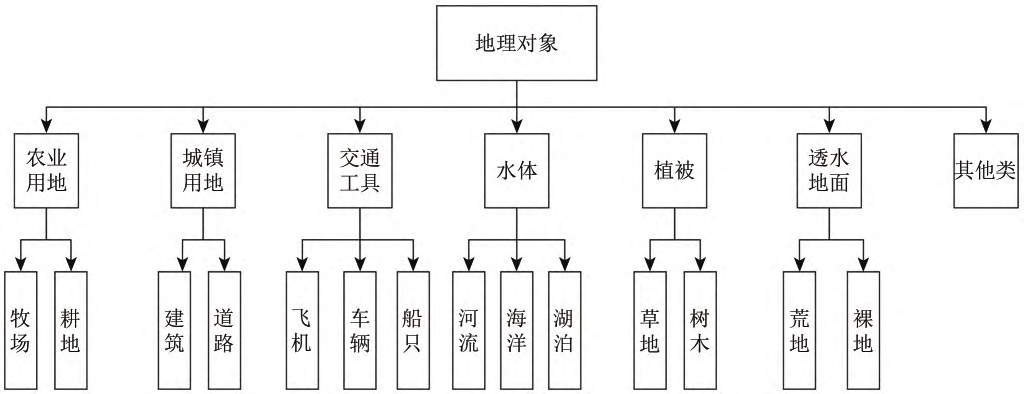
地学知识图谱引导的遥感影像语义分割
Abstract: Although the Deep Semantic Segmentation Network (DSSN) has notably enhanced remote-sensing image semantic segmentation, it still falls short of human experts’ visual interpretation. Unlike DSSN’s data-driven, pixel-level optimization, human experts rely on visual features, semantic insight, and prior knowledge for remote-sensing image interpretation. DSSN’s pixel-level approach is constrained by spatial scale, lacking comprehensive target inference and struggling to bridge structured data and unstructured knowledge. In response to the two issues above, this paper proposes a geographic knowledge graph-guided deep semantic segmentation network for remote-sensing imagery. We use the ground-object semantic information and geoscience prior knowledge extracted from the geographic knowledge graph to construct loss constraints, thereby autonomously guiding the training process of DSSN. The essence of our approach lies in the intricately crafted design of loss constraints. These loss constraints include the entity-level connectivity constraint and the inter-entity symbiosis constraint. The former calculates the loss in the unit of connected domain entities instead of pixels to achieve overall constraints on the entity. The latter embeds the spatial symbiosis knowledge quantified by the symbiosis conditional probability into the data-driven DSSN to constrain the spatial distribution of segmented entities. The entity-level connectivity constraint guides DSSN to autonomously learn entity-level feature representations during training. Accordingly, the segmentation results become more holistic and suppresses blurry boundaries and random noise. The inter-entity symbiosis constraint adjusts the spatial distribution of entities according to the spatial semantic information and the prior geoscience knowledge. This adjustment realizes the automatic optimization of the spatial distribution of segmented entities. Extensive experiments show that under the guidance of the entity-level connectivity constraint and the inter-entity symbiosis constraint, DSSN can complete the learning of entity-level features. It can also automatically optimize the spatial distribution of ground objects based on spatial symbiosis knowledge, thereby effectively improving the performance of remote-sensing image semantic segmentation. Our novel geographic knowledge graph-guided approach to deep semantic segmentation in remote-sensing imagery has successfully addressed the challenges posed by DSSN’s pixel-level optimization. By incorporating entity-level connectivity and inter-entity symbiosis constraints, we have enabled DSSN to autonomously learn comprehensive feature representations and optimize spatial distribution. The resulting improvements in semantic segmentation performance showcase the potential of merging domain-specific knowledge with data-driven techniques, bridging the gap between automated methods and human interpretation in remote-sensing image analysis. [full text] [link]
-
Pengcheng Shi, Jiayuan Li, Xinyi Liu, . (2024) Indoor Cylinders Guided LiDAR Global Localization and Loop Closure Detection. In: Geomatics and Information Science of Wuhan University 49(7), 1088-1099.
室内圆柱引导的激光雷达全局定位与回环检测
Abstract: Objectives Localization is an important module of the light detection and ranging (LiDAR) simultaneous localization and mapping (SLAM) system, which provides basic information for perception, control, and planning, further assisting robots to accomplish higher-level tasks. However, LiDAR localization methods still face some problems: The localization accuracy and efficiency cannot meet the requirements of the robot products. In some textureless or large open environments, the lack of features easily leads to dangerous robot kidnappings. Consequently, aiming at the localization problems of mobile robots in large indoor environments, a global localization method based on cylindrical features is proposed.Methods First, an offline parameterized map is designed, which consists of some map cylinders and a raster map. Because the point cloud map contains a large number of 3D points and complete cylinders, random sample consensus (RANSAC) and geometric models are combined to directly segment the cylindrical points. The raster map is employed to describe the distributions of stable artificial structures. Then, some lightweight binary files are used to offline record the geometric model of cylinders and the feature distribution of the map. Next, based on three unique geometric characteristics of the cylinder (outlier, symmetry, and saliency), a real-time LiDAR point cloud cylinder segmentation method is proposed. Finally, two pose computation strategies are designed. The first is an optimization model based on heuristic search, which searches for the best matching cylinder between the map and real-time point cloud, and calculates the translation and rotation, respectively. The second is an optimization model based on multi-cylinder constraints, which employs both the topological relation (point-to-point and point-to-line constraints) and geometry attributes to find approximately congruent cylinders, then computes optimal pose.Results To verify the feasibility of the proposed method, we use a 16-line LiDAR to collect the experimental data in three real-world indoor environments, i.e., lobby, corridor, and hybrid scenarios. The global localization experiment is compared to a similar wall-based localization method, and the loop closure detection is compared to M2DP, ESF, Scan Context, and the wall-based localization. The experimental results show that the proposed method outperforms the baseline methods. The place recognition and localization performance of the proposed method reach the mainstream method level, with a localization success rate of 90% and an error of 0.073 m. Some data can reach millimeter localization accuracy, and the fastest speed is within 100 ms.Conclusions The proposed method can effectively realize the global localization and place recognition of the robots in typical open indoor environments. It meets the accuracy and efficiency requirements of autonomous driving for global localization in practical applications. It can be applied to solve the problems of position initialization, re-localization, and loop closure detection. [full text] [link]
-
Zihang Liu, Xinyi Liu, . (2024) Building Damage Assessment from Satellite Images Combining Global-Local Features and Dynamic Error Supervision. In: Geomatics and Information Science of Wuhan University, 2024.
联合全局-局部特征和动态错误监督的遥感影像建筑物损伤评估方法
Abstract: After a disaster, it is essential to quickly and accurately assess the extent and severity of the disaster area for subsequent humanitarian relief and reconstruction. Traditional damage assessment methods are constrained by time efficiency, labor cost, and accessibility. In contrast, satellite images can quickly obtain the real situation of a wide range of disaster areas, and gradually become an important data source for building damage assessment. Automated building damage assessment from satellite images relies on deep learning methods, but current deep learning building damage assessment methods for satellite images face challenges such as insufficient modeling of feature differences, inadequate utilization of global-local features, and lack of difficult sample perception ability. Methods: To address these problems, a building damage assessment method based on global-local feature fusion and dynamic error supervision network (GLESNet) is proposed. At the encoding stage, the dual-temporal image features were extracted by a shared weight backbone, and the features were sent to the difference enhancement fusion module (DEFM) to enhance the difference between the features, filter out spurious changes, and obtain the fusion features. At the decoding stage, the fusion features are passed by the vertical and horizontal global-local feature fusion modules (GLFFM) and the dynamic error aware decoder (DEAD), to fuse the global and local features and percept the difficult samples. Results: The proposed GLESNet achieves 86.03% F1-score of building extraction, 75.20% F1-score of damage classification, and 78.45% overall F1-score on xBD, the largest global level high-resolution satellite image dataset for building damage assessment. Conclusions: The quantitative evaluation and visualization results are better than other advanced comparison methods. Ablation study verifies the effectiveness of each module. Transfer experiments and change detection experiments carried out on the IdaBD and LEVIR-CD datasets verify the generalization of the proposed GLESNet to different data and tasks. [full text] [link]
-
, Siyuan Zou, Xinyi Liu. (2023) DEM Sparse Point Cloud Guided Digital Surface Model Generation for Aerial Images. In: Geomatics and Information Science of Wuhan University, 2023, Vol 48 No.11: 1854-1862.

稀疏点云引导的航空影像数字表面模型生成方法
Abstract: Objectives Digital surface model is of great significance in the fields of real-life 3D modeling, smart city construction, natural resources management, geoscience research, and hydrology and water resources management. However, dense matching, as a core step in generating digital surface models, is prone to matching failures in regions with a lack of texture, disparity gap and inconsistent illumination. The sparse point cloud data with high accuracy and extensive coverage after aerial triangulation, which can be used as a priori information to improve the accuracy of dense matching results.Methods First, this paper proposes a sparse point cloud guidance (SPCG) method for generating digital surface models of aerial images. The method aims to constrain the dense matching of images using sparse point cloud encrypted by aerial triangulation. The sparse point cloud guidance first selects stereo image pairs with good geometric configurations, high overlap, and extensive coverage. Then, the number of sparse points is extended by using the closest proximity clustering and pyramid propagation methods. Additionally, the matching cost of the extended points is optimized by using the improved Gaussian function to enhance the accuracy of the dense matching results. Finally, the sparse point cloud is fused with the dense matching point cloud to generate the digital surface model.Results Experiments on simulated stereo images and real aerial stereo images show that the optimized semi-global matching by the SPCG method in this paper significantly improves the matching accuracy of the original semi-global matching algorithm and outperforms the semi-global matching optimized by the Gaussian method and the deep learning method, pyramid stereo matching network. Numerically, the percentages of disparity maps generated by semi-global matching with greater than 1, 2, or 3 pixels difference from the true disparities are 46.72%, 32.83%, or 27.32%, respectively, whereas the SPCG method decreases by 7.67%, 9.75%, or 10.28%, respectively, compared to the former. The experimental results of the multiview aerial images show that the SPCG method accurately generates the digital surface model of the whole survey area, and it is better than the digital surface model generated by the superior SURE software in both qualitative and quantitative aspects.Conclusions Compared to the original dense matching, sparse point cloud-guided dense matching improves the matching accuracy in difficult matching regions such as weak textures, repetitive textures and depth discontinuities. In turn, high precision and high density point clouds are generated. A complete digital surface model is generated by the fusion of the densely matched point clouds. [full text] [link]
-
Chen Jia, Xinyi Liu, , Xianzhang Zhu, Weicheng Ren, Qing He, Yougui Feng. (2023) Repetitive texture detection of building facade constrained by baseline. In: Bulletin of Surveying and Mapping, 2023, 0(3): 49-54.

基准线约束的建筑物立面重复纹理检测
Abstract: Repeated texture is one of the most important features in building facades. How to automatically detect repeating textures from facade images is an important part of building facade analysis. This paper proposes a new Baseline Constrained Texture Detection Method to automatically detect the exact location and size of repeating objects. The method first uses Bayesian adaptive superpixel segmentation to construct a superpixel adjacency map, and then separates the wall by calculating chromatic aberration to obtain candidate objects. Secondly, extract straight lines from the original image, and perform preprocessing such as normal classification and line segment clustering on the obtained straight lines. Finally, texture repair is performed based on prior knowledge of building facade structure. The experimental results show that the proposed method can effectively detect the position and size information of repeated textures when detecting repeated textures whose geometric shapes are rectangles, and repair the occluded repeated objects. [full text] [link]
-
, Fei Wang, Yansheng Li, Song Ouyang, Dong Wei, Xiaojian Liu, Deyu Kong, Ruixian Chen, Bin Zhang. (2023) Remote sensing knowledge graph construction and its application in typical scenarios. In: Bulletin of Surveying and Mapping, Vol 27, No 2: 249-266.
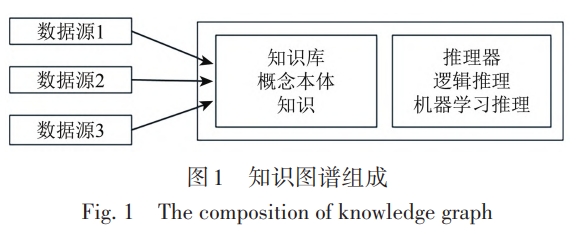
遥感知识图谱创建及其典型场景应用技术
Abstract: Compared with the current powerful acquisition capabilities of remote sensing data, its intelligent processing and knowledge service capabilities are relatively lagging. The contradiction between the accumulation of massive multisource remote sensing data and the limited information island is becoming increasingly prominent. Therefore, there is an urgent need for effective remote sensing domain knowledge modeling technology to assist in mining the useful information of remote sensing big data and form knowledge service capabilities. A Knowledge Graph (KG) describes the concepts and their relationships in the physical world in symbolic form. It has strong knowledge modeling and reasoning capabilities and has been successfully applied in search engines, e-commerce, social network analysis and other fields. Inspired by the general KGs, this paper conceives of establishing a remote sensing domain KG for the first time, which can provide support for knowledge modeling and knowledge services in the remote sensing field. First, this paper reviews the development history of general KGs. Second, it discusses the technologies of constructing remote sensing KGs. Compared with general KGs, remote sensing KGs are oriented to the field of remote sensing geosciences. They have significant disciplinary characteristics and spatiotemporal graph characteristics in terms of graph nodes, graph relationships and graph reasoning. Specific performances are as follows: (1) Images are an important part of remote sensing, which play an irreplaceable role and are ignored by general KGs. (2) Remote sensing knowledge is oriented to spatial entities. In addition to semantic relationships, the description of entity relationships also requires spatial and temporal relationships. (3) Traditional logical reasoning and natural language processing learning reasoning cannot effectively deal with image entities and spatial relationships. To solve the above problems, this paper draws on the construction scheme of the general KG and related domain KG and proposes the basic construction process of the remote sensing KG. Third, it introduces typical geoscience application cases driven by remote sensing KGs, which include three cases: (1) Marine oil spill monitoring. Marine oil spill KG is used for oil pollution identification, cause reasoning, and spill risk assessment, etc. (2) Land cover classification. Coupling remote sensing KG reasoning and deep learning for land cover classification. Numerous experiments have proven that KG can improve the classification results. (3) Evaluation of the carrying capacity of resources and the environment and suitability of land and space development. Ontology can not only express the knowledge system of evaluation in a standardized manner but also infer the evaluation results based on the constructed knowledge. Finally, it analyzes the application status and future research directions of remote sensing KGs. This paper points out four feasible and important research directions: (1) Exploring the theories and methods of creating multimodal remote sensing KGs; (2) Cooperative update and alignment fusion of remote sensing KGs; (3) Intelligent remote sensing image classification based on remote sensing KG representation learning; and (4) Scientific decision support analysis assisted by remote sensing KGs. Generally, the research of remote sensing KGs is conducive to better summarizing the conceptual knowledge of remote sensing, managing the new knowledge contained in remote sensing big data, and providing flexible and convenient remote sensing knowledge query and service capabilities to users in multiple fields, and it will help comprehensively improve the application capabilities of massive multisource remote sensing observation results and will play an important role in the study of global remote sensing land cover classification, climate change, international humanitarian assistance, and so on. [full text] [link]
-
Pengcheng Shi, Jiayuan Li, Xinyi Liu, . (2023) LiDAR Global Localization and Loop Closure Detection Based on Indoor Cylinders. In: Geomatics and Information Science of Wuhan University, 2023.

基于室内圆柱的激光雷达全局定位与回环检测
Abstract: Objectives: Localization is an important module of the LiDAR SLAM system, which provides basic information for perception, control, and planning, further assisting robots to accomplish higher-level tasks. However, LiDAR localization methods still face some problems:the localization accuracy and efficiency cannot meet the requirements of the robot products. In some textureless or large open environments, the lack of features easily leads to dangerous robot kidnappings. Consequently, aiming at the localization problems of mobile robots in large indoor environments, a global localization method based on cylindrical features is proposed. Methods: Firstly, an offline parameterized map is designed, which consists of some map cylinders and a raster map. Because the point cloud map contains a large number of 3D points and complete cylinders, random sample consensus (RANSAC) and geometric models are combined to directly segment the cylindrical points. The raster map is employed to describe the distributions of stable artificial structures. Then, some lightweight binary files are used to offline record the geometric model of cylinders and the feature distribution of the map. Next, based on three unique geometric characteristics of the cylinder (outlier, symmetry, and saliency), a real-time LiDAR point cloud cylinder segmentation method is proposed. Finally, two pose computation strategies are designed. The first is an optimization model based on heuristic search, which searches for the best matching cylinder between the map and real-time point cloud, and calculates the translation and rotation, respectively. The second is an optimization model based on multicylinder constraints, which employs both the topological relation (point-to-point and point-to-line constraints) and geometry attributes to find approximately congruent cylinders, then computes optimal pose. Results: To verify the feasibility of the proposed method, we use a 16-line LiDAR to collect the experimental data in three real-world indoor environments, i.e., lobby, corridor, and hybrid scenarios. The global localization experiment is compared to a similar wall-based localization method, and the loop closure detection is compared to M2DP, ESF, Scan Context, and the wall-based localization. The experimental results show that the proposed method outperforms the baseline methods. The place recognition and localization performance of the proposed method reach the mainstream method level, with a localization success rate of 90% and an error of 0.088m. Some data can reach millimeter localization accuracy, and the fastest speed is within 100ms. Conclusions: The proposed method can effectively realize the global localization and place recognition of the robots in typical open indoor environments. It meets the accuracy and efficiency requirements of autonomous driving for global localization in practical applications. It can be applied to solve the problems of position initialization, re-localization, and loop closure detection. [full text] [link]
-
Xinyi Liu, , Weiwei Fan, Senyuan Wang, Dongdong Yue, Zihang Liu, Chen Jia, Huiying Jing, Jiachen Zhong. (2023) 3D Modeling based on UAV Oblique Photogrammetry: Research Status and Prospect. In: Geomatics World, 30(1): 41-48.
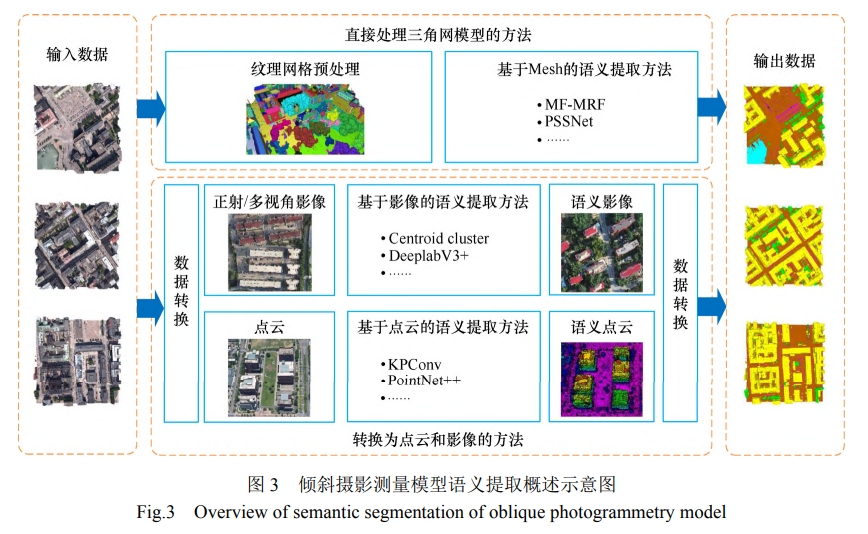
无人机倾斜摄影三维建模技术研究现状及展望
Abstract: Unmanned aerial vehicle (UAV) oblique photogrammetry, which synchronously collects images from multiple perspectives on the aerial platforms, can generate realistic 3D models through oblique photogrammetry measurements and 3D modeling technologies. It is currently one of the main technical means for reconstructing real-world 3D models from terrain to city scales. The article summarizes and categorizes the key technologies in UAV oblique 3D modeling, focusing on the current methods and research status of 3D scene reconstruction, semantic segmentation, individualization, and objectified processing of oblique photogrammetry triangular mesh models. The article points out the existing problems in UAV oblique 3D modeling technology and analyzes and forecasts potential development trends and research directions in terms of UAV path planning, and data acquisition, modeling techniques, and model representation. [full text] [link]
-
Yansheng Li, . (2022) A New Paradigm of Remote Sensing Image Interpretation by Coupling Knowledge Graph and Deep Learning. In: Geomatics and Information Science of Wuhan University, Vol 47, No.8: 1176-1190.
耦合知识图谱和深度学习的新一代遥感影像解译范式
Abstract: Objectives In the remote sensing (RS) big data era, intelligent interpretation of remote sensing images (RSI) is the key technology to mine the value of big RS data and promote several important applications. Traditional knowledge-driven RS interpretation methods, represented by expert systems, are highly interpretable, but generally show poor performance due to the interpretation knowledge being difficult to be completely and accurately expressed. With the development of deep learning in computer vision and other fields, it has gradually become the mainstream technology of RSI interpretation. However, the deep learning technique still has some fatal flaws in the RS field, such as poor interpretability and weak generalization ability. In order to overcome these problems, how to effectively combine knowledge inference and data learning has become an important research trend in the field of RS big data intelligent processing. Generally, knowledge inference relies on a strong domain knowledge base, but the research on RS knowledge graph (RS-KG) is very scarce and there is no available large-scale KG database for RSI interpretation now. Methods To overcome the above considerations, this paper focuses on the construction and evolution of the RS-KG for RSI interpretation and establishes the RS-KG takes into account the RS imaging mechanism and geographic knowledge. Supported by KG in the RS field, this paper takes three typical RSI interpretation tasks, namely, zero-shot RSI scene classification, interpretable RSI semantic segmentation, and large-scale RSI scene graph generation, as examples, to discuss the performance of the novel generation RSI interpretation paradigm which couples KG and deep learning. Results and Conclusions A large number of experimental results show that the combination of RS-KG inference and deep data learning can effectively improve the performance of RSI interpretation.The introduction of RS-KG can effectively improve the interpretation accuracy, generalization ability, anti-interference ability, and interpretability of deep learning models. These advantages make RS-KG promising in the novel generation RSI interpretation paradigm. [full text] [link]
-
Xinwei Li, Yansheng Li, . (2021) Weakly supervised deep semantic segmentation network for water body extraction based on multi-source remote sensing imagery. In: Journal of Image and Graphics | J Image Graph, Vol 26, No.12: 3015-3026.
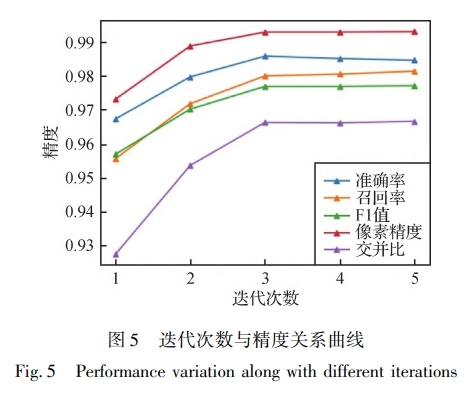
弱监督深度语义分割网络的多源遥感影像水体检测
Abstract: Objective Water body detection has shown important applications in flood disaster assessment, water resource value estimation and ecological environment protection based on remote sensing imagery. Deep semantic segmentation network has achieved great success in the pixel-level remote sensing image classification. Water body detection performance can be reasonably expected based on the deep semantic segmentation network. However, the excellent performance of deep semantic segmentation network is highly dependent on the large-scale and high-quality pixel-level labels. This research paper has intended to leverage the existing open water cover products to create water labels corresponding to remote sensing images in order to reduce the workload of labeling and meantime maintain the fair detection accuracy. The existing open water cover products have a low spatial resolution and contain a certain degree of errors. The noisy low-resolution water labels have inevitably affected the training of deep semantic segmentation network for water body detection. A weakly supervised deep learning method to train deep semantic segmentation network have been taken into consideration to resolve the difficulties. The optimization method to train deep semantic segmentation network using the noisy low-resolution labels for the high accuracy of water detection has been presented based on minimizing the manual annotation cost. Method In the training stage, the original dataset has been divided into several non-overlapped sub-datasets. The deep semantic segmentation network has been trained on each sub-dataset. The trained deep semantic segmentation networks with different sub-datasets have updated the labels simultaneously. As the non-overlapped sub-datasets generally have different data distributions, the detection performance of different networks with different sub-datasets is also complementary. The prediction of the same region by different networks is different, so the multi-perspective deep semantic segmentation network can realize the collaborative update of labels. The updated labels have been used to repeat the above process to re-train new deep semantic segmentation networks. Following each step of iteration, the output of the network has been used as the new labels. The noisy labels have been removed with the iteration process. The range of truth value of the water has also be expanded continuously along with the iteration process. Several good deep semantic segmentation networks can be obtained after a few iterations. In the test stage, the multi-source remote sensing images have been predicted by several deep semantic segmentation networks representing different perspectives and producing the final water detection voting results. Result The multi-source remote sensing image training dataset, validation dataset and testing dataset have been built up for verification. The multi-source remote sensing imagery has composed of Sentinel-1 SAR (synthetic aperture radar) images and Sentinel-2 optical images. The training dataset has contained 150 000 multi-source remote sensing samples with the size of 256×256 pixels. The labels of the training dataset have been intercepted with the public MODIS (moderate-resolution imaging spectroradiometer) water coverage products in geographic scale. The spatial resolution of the training dataset is low and contains massive noise. The validation dataset has contained 100 samples with the size of 256×256 pixels and the testing dataset have contained 400 samples with the size of 256×256 pixels, and the labels from the validation and testing datasets have accurately annotated with the aid of domain experts. The training, validation and testing datasets have not been overlapped each and the dataset can geographically cover in global scale. Experimental results have shown that the proposed method is convergent, and the accuracy tends to be stable based on four iterations. The fusion of optical and SAR images can improve the accuracy of water body detection. The IoU (intersection over union) has increased by 5.5% compared with the traditional water index segmentation method. The IoU has increases by 7.2% compared with the deep semantic segmentation network directly using the noisy low-resolution water labels. Conclusion The experimental results have shown that the current method can converge fast, and the fusion of optical and SAR images can improve the detection results. On the premise of the usage of the noisy low-resolution water labels, the water body detection accuracy of the trained multi-perspective model is obviously better than the traditional water index segmentation method and the deep semantic segmentation network based on the direct learning of the noisy low-resolution water labels. The accuracy of the traditional deep semantic segmentation method is slightly lower than that of the traditional water index method, which indicates that the effectiveness of deep learning highly depends on the quality of the training data labels. The noisy low-resolution water labels have reduced the effect of deep learning. The effect of the proposed method on small rivers and lakes has been analyzed. The accuracy on small rivers and lakes has decreased slightly. The result has still higher than the traditional water index method and the deep learning method with the direct training of the noisy low-resolution water labels. [full text] [link]
-
, Yi Wan, Wenzhong Shi, Zuxun Zhang, Yansheng Li, Shunping Ji, Haoyu Guo, Li Li. (2021) Technical framework and preliminary practices of photogrammetric remote sensing intelligent processing of multi-source satellite images. In: Acta Geodaetica et Cartographica Sinica, Vol 50, No.8: 1068-1083.

多源卫星影像的摄影测量遥感智能处理技术框架与初步实践
Abstract: The history and recent development of photogrammetry and remote sensing are reviewed and analyzed firstly. Then the novel concept of "photogrammetric remote sensing" is put forward to meet the needs of accurate and fast processing of multi-source remote sensing images in the new era of big data and intelligent surveying and mapping. The new photogrammetric remote sensing discipline is the deep integration of the frontier theories and technologies of photogrammetry and remote sensing, and concentrates on solving the theories and technologies about simultaneously determine the geometric positions, physical attributes, semantic information and temporal changes of interested scenes and objects. Its theoretical and fundamental basis are photogrammetry, remote sensing, artificial intelligence, big data processing, and high-performance computation, etc. It will break through the current isolated status and serial technical route that photogrammetry mainly focuses on geometric processing, while remote sensing mainly focuses on semantic information extraction and inversion. It forms an innovation of the closed-loop fusion of semantic extraction and geometric processing. A novel geometric-semantic integrated processing framework is formed through the deep fusion of geometric model and spectral radiative and reflective information. Based on the proposed concept of photogrammetric remote sensing, this paper discusses the main scientific problems and related research and application fields, and then attempts to build a new theoretical and technical framework of integrated intelligent photogrammetric remote sensing processing of multi-source satellite images. Closed-loop fusion of semantic information extraction and accurate geometric processing has significantly improved the level of accuracy, automation and intelligence. The correctness and effectiveness of the proposed theory and methods are preliminarily verified by several practical applications. [full text] [link]
-
Yongxiang Yao, , Yi Wan, Xinyi Liu, Haoyu Guo. (2021) Heterologous Images Matching Considering Anisotropic Weighted Moment and Absolute Phase Orientation. In: Geomatics and Information Science of Wuhan University, Vol 46, No.11: 1727-1736.
顾及各向异性加权力矩与绝对相位方向的异源影像匹配
Abstract: Objectives With the enrichment of heterologous image acquisition methods, heterologous image is widely used in many fields, such as change detection, target recognition and disaster assessment. However, matching is the premise of heterologous image fusion application. Simultaneously, due to the differences in imaging mechanisms of different sensors, heterologous images are more sensitive to differences in illumination, contrast, and nonlinear radiation distortion. Therefore, heterologous image matching still faces some problems. There are two main problems, heterologous image feature detection is difficult due to the difference of imaging mechanism, which indirectly increases the difficulty of matching, heterologous image has significant differences in illumination, contrast and nonlinear radiation distortion, which reduces the robustness of feature description and easily leads to matching failure directly. Methods This paper proposes a new matching method considering anisotropic weighted moment and the histogram of the absolute phase orientation. Firstly, anisotropic filtering is used for image nonlinear diffusion. Based on this, the maximum moment and minimum moment of image phase consistency are calculated, and the anisotropic weighted moment equation is constructed to obtain the anisotropic weighted moment map. Then, the phase consistency model is extended to establish the absolute phase consistency orientation gradient. Combined with the log polar description template, a histogram of absolute phase consistency gradients (HAPCG) is established. Finally, the Euclidean distance is used as the matching measure for corresponding point recognition. Results Several groups of heterologous remote sensing images with illumination, contrast, and nonlinear radiation distortion are used as data sources of experiments with scale invariant feature transform(SIFT), position scale orientation-SIFT(PSO-SIFT), Log-Gabor histogram descriptor(LGHD) and radiation-variation insensitive feature transform(RIFT) methods, respectively. The results show that HAPCG method is superior to SIFT, PSO-SIFT and LGHD in the comprehensive matching performance of heterologous remote sensing images, and the average matching number of corresponding points is increased by over 2 times, and the root mean square error is 1.83 pixels. When compared with RIFT method, HAPCG method can achieve higher matching accuracy in the case of similar corresponding points and can realize the robust matching of heterologous remote sensing images. Conclusions The proposed HAPCG method can achieve robust matching performance in heterologous remote sensing images and provide stable data support for multi-source image data fusion and other tasks. [full text] [link]
-
, Zuxun Zhang, Jianya Gong. (2021) Generalized photogrammetry of spaceborne, airborne and terrestrial multi-source remote sensing datasets. In: Acta Geodaetica et Cartographica Sinica, Vol 50, No.1:1-11.
天空地多源遥感数据的广义摄影测量学
Abstract: Since the 21st century, with the rapid development of cloud computing, big data, internet of things, machine learning and other information technology fields, human beings have entered a new era of artificial intelligence. The subject of photogrammetry has also followed the tide of the new round of scientific and technological revolution and developed rapidly into the brand-new generalized photogrammetry and entered the era of integrated intelligent photogrammetry. Its carrier platform, instruments and data processing theories as well as application fields have also changed significantly. The multi-sensor and multi-level integrated stereo observation technologies from spaceborne, airborne and terrestrial platforms have been greatly developed. In this paper, the novel concept of generalized photogrammetry is first put forward, and its subject connotation, development characteristics and some key technologies and applications are discussed in details. Under the brand-new generalized photogrammetry framework, data acquisition presents the characteristics of multi-angle imaging, multi-modal collaboration, multi-time integration, multi-scale linkage, while data processing presents the trends of multi-feature coupling, multi-control constraints, multi architecture processing, and multi-disciplinary intersection. The all-round development and intelligent service of the general photogrammetry still need to make greater breakthroughs in the aspects of spaceborne, airborne and terrestrial multi perspective or multi-modal image processing, intelligent information extraction and monitoring, combined 3D modeling with point cloud and image, autonomous control of unmanned system, visual inspection of intelligent manufacturing system, etc. Finally, new theories and technologies from real-time or quasi real-time intelligent geometric processing of multi-source remote sensing datasets to information extraction and intelligent service need to be established, which will make a well foundation to meet the new eara of intelligent surveying and mapping. [full text] [link]
-
Yansheng Li, Deyu Kong, , Zheng Ji, Rui Xiao. (2020) Zero-shot Remote Sensing Image Scene Classification Based on Robust Cross-domain Mapping and Gradual Refinement of Semantic Space. In: Acta Geodaetica et Cartographica Sinica, Vol 49, No.12: 1564-1574.
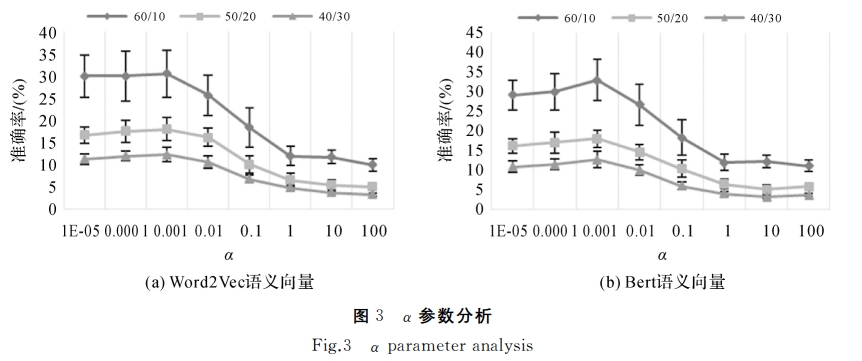
联合稳健跨域映射和渐进语义基准修正的零样本遥感影像场景分类
Abstract: Zero-shot classification technology aims to acquire the ability to identify categories that do not appear in the training stage (unseen classes) by learning some categories of the data set (seen classes), which has important practical significance in the era of remote sensing big data. Until now, the zero-shot classification methods in remote sensing field pay little attention to the semantic space optimization after mapping, which results in poor classification performance. Based on this consideration, this paper proposed a zero shot remote sensing image scene classification method based on cross-domain mapping with auto-encoder and collaborative representation learning. In the supervised learning module, based on the class semantic vector of seen class and the scene image sample, the depth feature extractor learning and robust mapping from visual space to semantic space are realized. In the unsupervised learning stage, based on the class semantic vectors of all classes and the unseen remote sensing image samples, collaborative representation learning and k-nearest neighbor algorithm are used to modify the semantic vectors of unseen classes, so as to alleviate the problem of the shift of seen class semantic space and unseen class semantic space one after another and unseen after self coding cross domain mapping model mapping the shift of class semantic space and unseen class semantic space after collaborative representation. In the testing phase, based on the depth feature extractor, self coding cross domain mapping model and modified unseen class semantic vector, the classification of unseen class remote sensing image scene can be realized. We integrate a number of open remote sensing image scene data sets and build a new remote sensing image scene data set, experiments were conducted using this dataset The experimental results show that the algorithm proposed in this paper were significantly better than the existing zero shot classification method in the case of a variety of seen and unseen classes. [full text] [link]
-
Yansheng Li, Deyu Kong, , Zheng Ji, Rui Xiao. (2020) Registration of Airborne LiDAR Data and Multi-View Aerial Images Constrained by Junction Structure Features. In: Geo-Information Science, Vol 22, No.9, 1868-1877.
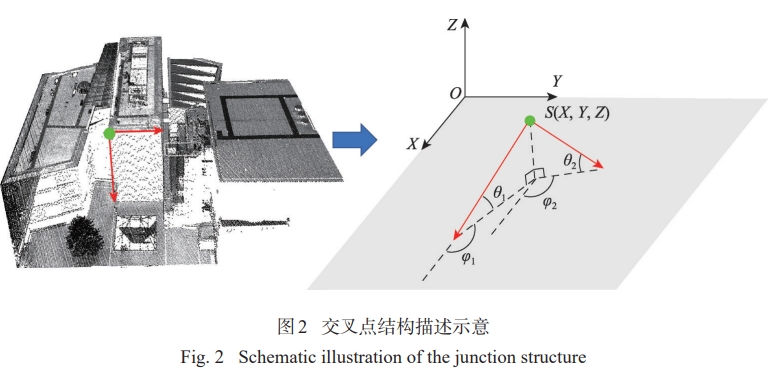
交叉点结构特征约束的机载LiDAR点云与多视角航空影像配准
Abstract: The integration of Airborne LiDAR data and aerial imagery is useful in data interpretation, land monitoring, and 3D reconstruction. As the first step of these tasks, the geometric registration of the two types of data should be conducted to ensure their alignment. The alignment is sometimes difficult because of differences in their data acquisition mechanisms. The LiDAR data is more reliable and more accurate on smooth surfaces like grounds, walls, and roofs which are difficult to extract from aerial imagery. LiDAR points are mostly sparser than the pixels on aerial images. Considering that the a priori ranging error (1~5 cm) of airborne LiDAR data is usually much smaller than the average point distance (10~50 cm), this paper introduced a plane-constrained block adjustment model to align the two types of data, where the planes were obtained by the intersection of corresponding junction structures. The planar constraints were implemented by forcing surrounding LiDAR points to be on the planes. The proposed block adjustment model is a mixture of the conventional POS-aided and self-calibrated bundle adjustment model and two more types of observing equations. One is the distance between image junction structure observations, and reprojection of the spatial junction structure should be zeros. The other is the normal distance between LiDAR points, and the spatial planes obtained by junction structure should be zeros. In this paper, firstly junction structures in object space were solved based on least squares theory. Then, conjugate planes of junction structures in LiDAR points were detected automatically. Finally, the aerial images block adjustment under constraints of junction structure was performed to obtain the precise interior and exterior orientation parameters. The experimental results showed that both the horizontal and the vertical accuracy of the proposed method could reach 1~2 pixels of the aerial images, which was obviously better than the building-corner-based method. In order to probe into the influence of point cloud density, the LiDAR points were thinned randomly before the geometric registration. The results showed that the accuracy of the proposed method was not influenced but the accuracy of building-corner-based method decreased when the point cloud density decreased, especially the horizontal accuracy. In conclusion, the proposed method takes the advantage of the high-ranging accuracy of LiDAR data to reach high registration accuracy and avoids the influence of the point cloud density. When the density of the LiDAR point cloud is low, a high registration accuracy can be reached using the proposed method. [full text] [link]
-
, Xingbei Huang, Xinyi Liu. (2020) A Terrain-adaptive Airborne LiDAR Point Cloud Filtering Method Using Regularized TPS. In: Geo-Information Science, Vol 22, No.4, 898-908.
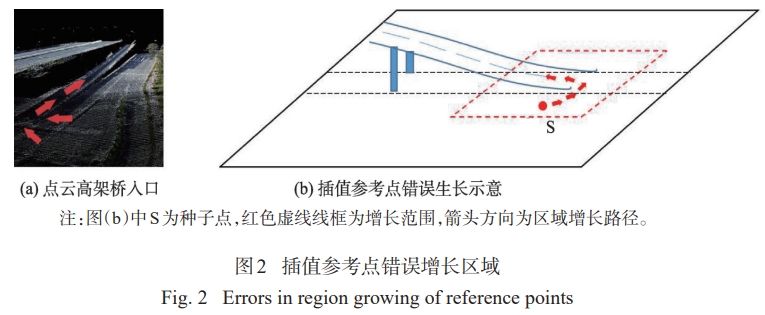
一种地形自适应的机载LiDAR点云正则化TPS滤波方法
Abstract: With the continuous development of LiDAR technology, the research of LIDAR point cloud data processing is also in-depth. Point cloud filtering is one of the key steps in airborne LiDAR point cloud processing. The existing point cloud filtering algorithms often work well on some specific terrains, however, their filtering results are not satisfying in the cases of undulating terrains or mixed terrains, some post-processing measures are always needed. Based on relative coefficient of variation and regularized thin-plate-spline interpolation, a new terrain adaptive point cloud filtering method is proposed in this paper. The initial seed points are obtained by two-dimensional and 8-directional region-growing method, and then optimized by extracting line features from the point clouds, the points with low reliability are removed from the sets of reference points. After that the reference points are mostly reliable and scattered in the whole test area, and could be used to generate classifying surface. Finally, the classifying surface between ground points and non-ground points is fitted using thin-plate-spline interpolation. Classifying surface is used to absorb more ground points from point cloud, which could provide reference information for the next round of interpolation. In this process we use regularization item of adaptive coefficient to control the bending extent of classifying surface, in order to make the filtering algorithm adaptive to different types of terrains. Ground points are totally filtered after several iterations. The experimental results on point clouds from multiple devices show that the total errors of our proposed method were 4.14% and 4.17% in Guangzhou and ISPRS datasets, respectively. The result of the proposed filtering method is not the best, but it is more stable and has better terrain adaptability compared to state-of-the-art popular algorithms such as progressive TIN filter, cloth simulation filter, semi-global filter, etc. The proposed method outperforms other comparison methods in both error rate and overall performance in several complex or special terrains, as well as high computational efficiency. Additionally, the promising experimental results demonstrate that the proposed adaptive terrain filtering method is an accurate and efficient solution for airborne LiDAR point cloud filtering in complex terrains, such as slopes, ridges, and mixed terrains including vegetation and buildings. [full text] [link]
-
Ping Sun, Xudong Hu, (2019) Object Detection Based on Deep Learning and Attention Mechanism. In: Computer Engineering and Applications, Vol 55, No.17: 180-184.
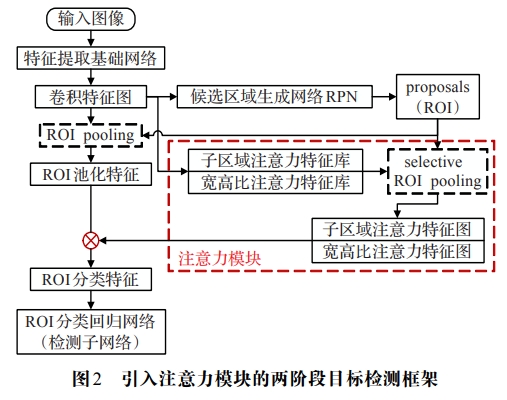
结合注意力机制的深度学习图像目标检测
Abstract: In the Convolution Neural Network(CNN), convolutional layers are translation-invariant, which weaken the localization performance of object detector. Actually, objects usually have distinct sub-region spatial characteristics and aspect ratio characteristics, but in prevalent two-stage object detection methods, these translation-variant feature components are rarely considered. In order to optimize the feature representations, the sub-region attention bank and aspect ratio attention bank are introduced into the two-stage object detection framework and generate the corresponding attention maps to refine the original ROI features.In addition, with the aid of the attention maps, the feature dimension can be greatly reduced.The experimental results show that object detectors equipped with attention module improve the accuracy and inference speed signi cantly. [full text] [link]
-
Xiangguang Chen, (2019) Automatic DSM Extraction Based on SuperView-1 Satellite Imagery. In: Journal of Geomatics, Vol 44, No.5: 11-15.
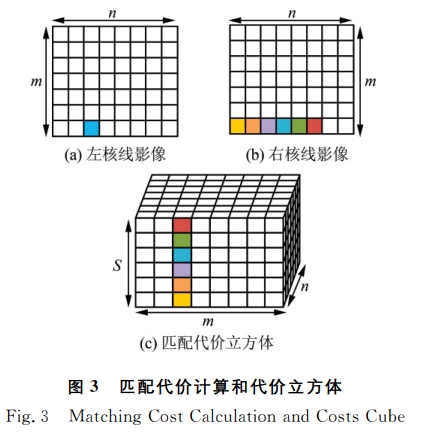
高景一号卫星影像DSM自动提取方法
Abstract: SuperView-1 is China's first ultra-high resolution commercial satellite with spatial resolution up to 0.5 m. Its application marking domestic commercial remote sensing officially steps into the international leading ranks. The stereo data obtained by SuperView-1 is used to analyze, the epipolarity between the stereo pairs, and a polynomial model is used to generate epipolar images. Then, combining the strategy of image block matching and refusion, the semi-global matching algorithm is used for dense matching to generate parallax graph. Finally, the automatic extraction of digital surface model (DSM) is realized through the forward intersection. The experimental results show that the epipolar line of SuperView-1image has the characteristic of being straight; the high resolution DSM generated by this method has a complete macro terrain; and the mountain terrain is rebuilt accurately and the details are rich in texture. It shows that the application of the proposed method has achieved good results on the SuperView-1. [full text] [link]
-
Kun Hu, Xu Huang, , Hongjian You (2018) Satellite Platform Jitter Detection and Image Geometric Quality Compensation Based on High-frequency Angular Displacement Data. In: Journal of Electronics & Information Technology, 40(07): 1525-1531.
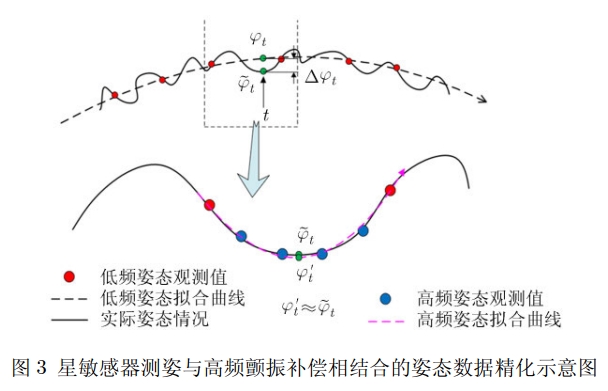
基于高频角位移数据的卫星平台颤振检测与影像几何质量补偿
Abstract: With the improvement of imaging resolution and on-orbit mobility of earth observation satellites, the imaging geometric quality is more apparently influenced by the attitude's high-frequency jittering of satellite platform. The traditional time-division imaging data based jitter detection and compensation methods have many drawbacks, which include large amount of calculation and high degree of error interference in dense matching, and it is unable to decompose the jitter quantity in each rotation angle direction. This paper takes the high-frequency angular displacement equipment which is carried by China's remote sensing optical satellite for example, studies on the direct jitter detection method and the image geometric quality compensation method based on high-frequency attitude measurement angular displacement data, which include the windowed FIR filter pre-processing of angular displacement data, the phase distribution analysis on time-dependent jitter curve in pitch, roll and yaw directions, as well as image direct positioning compensation based on angular displacement data. The high-frequency jitter compensation is applied to attitude recovery and geometric rectification based on strict imaging geometric model.The experimental results of China' remote sensing satellite images in Beijing area illustrate that the methods proposed in this paper can significantly improve the accuracy and reliability of the high- frequency jitter detection, and can effectively improve the internal geometric quality of satellite image after jitter compensation. For example, the length deformation accuracy can be improved by 0.5 pixel. [full text] [link]
-
Zhaoxi Yue, , Yansong Duan, Lei Yu. (2018) DEM Assisted Shadow Detection and Topography Correction of Satellite Remote Sensing Images in Mountainous Area. In: Acta Geodaetica et Cartographica Sinica, Vol. 47, No. 1: 113-122.
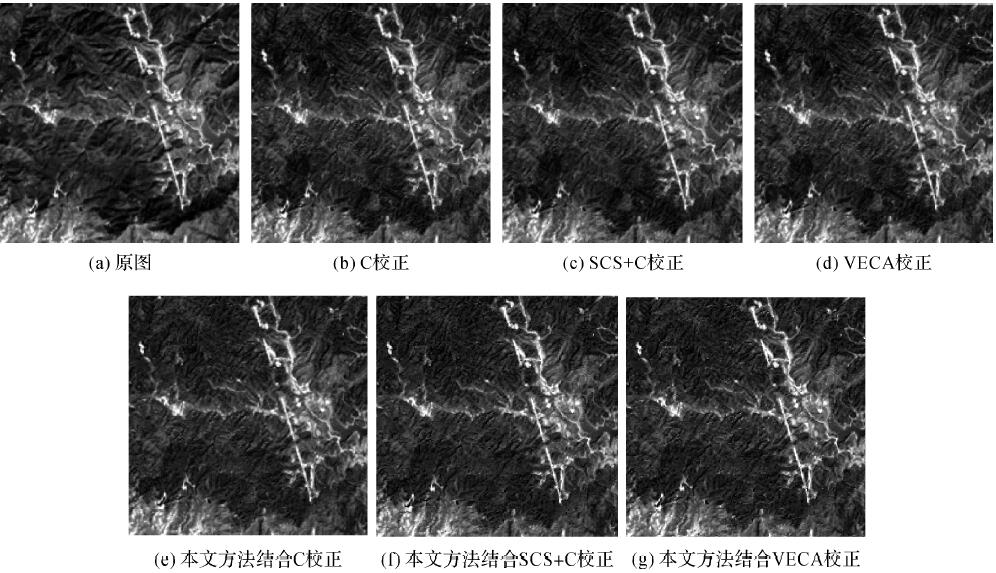
DEM辅助的卫星光学遥感影像山体阴影检测与地形辐射校正
Abstract: A shadow detection and topography correction method based on DEM is proposed.Firstly,characteristic method is used to detect the shadow area in the satellite imagery.Then the shady slope and cast shadow area can be detected by model method using DEM data.The shadow is divided into 8 categories with the cause of formation.And then,the compensation method of shadow area and topography correction model are used to correct the optical remote sensing satellite imagery.The results suggest that the proposed method can recover the shadow area information effectively and weaken the effect of terrain. [full text] [link]
-
Qian Li, , Hongshu Lu, Xinyi Liu. (2018) Detection of Pedestrian Crossings with Hierarchical Learning Classifier from Multi-angle Low Altitude Images. In: GEOMATICS AND INFORMATION SCIENCE OF WUHAN UNIVERS, Vol. 43, No. 1: 46-52.
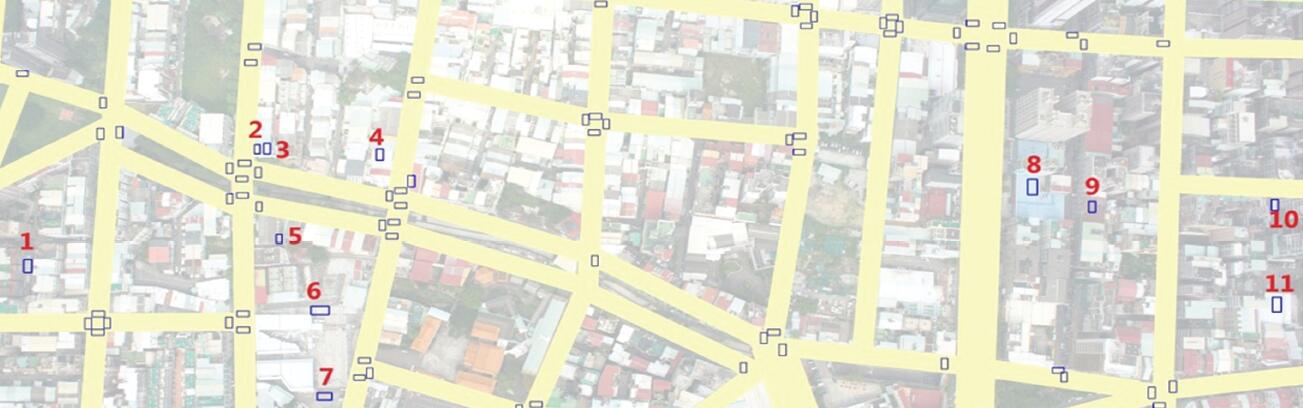
基于错误式学习的低空影像人行横道多角度自动识别
Abstract: This paper proposes a new training method for feature-based iterative hierarchical learning classifiers. It can be used to detect pedestrian crossings from multi-angle low altitude images. The training procedure and the method for merging multi-angle detection results are introduced in this paper. The performance of the classifier was evaluated based on random testing results. Experimental results from several datasets show that the iterative classifier has higher correctness, lower missing rate and lower error rate than the general classifier. Furthermore, the proposed method will not reduce the detection speed. [full text] [link]
-
Maoteng Zheng, , Junfeng Zhu, Xiaodong Xiong, Shunping Zhou. (2017) A Fast and Effective Block Adjustment Method with Big Data. In: Acta Geodaetica et Cartographica Sinica, Vol.46, No.2: 188-197(10).
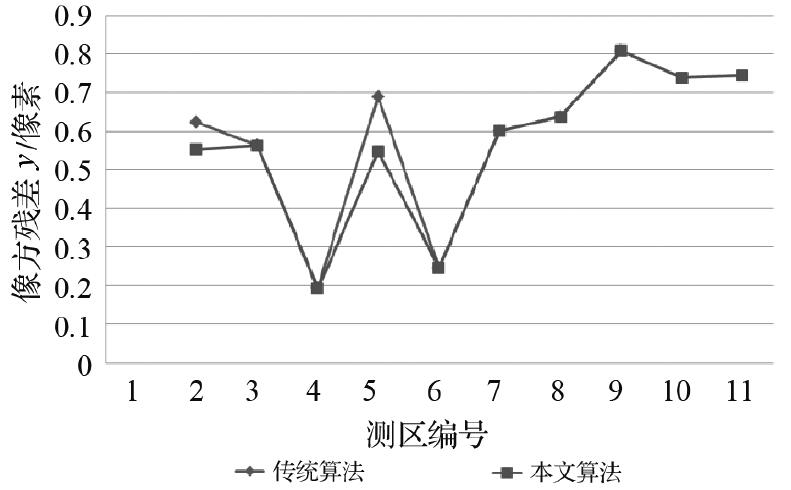
一种快速有效的大数据区域网平差方法
Abstract: To deal with multi-source, complex and massive data in photogrammetry, and solve the high memory requirement and low computation efficiency of irregular normal equation caused by the randomly aligned and large scale datasets, we introduce the preconditioned conjugate gradient combined with inexact Newton method to solve the normal equation which do not have strip characteristics due to the randomly aligned images. We also use an effective sparse matrix compression format to compress the big normal matrix, a brand new workflow of bundle adjustment is developed. Our method can avoid the direct inversion of the big normal matrix, the memory requirement of the normal matrix is also decreased by the proposed sparse matrix compression format. Combining all these techniques, the proposed method can not only decrease the memory requirement of normal matrix, but also largely improve the efficiency of bundle adjustment while maintaining the same accuracy as the conventional method. Preliminary experiment results show that the bundle adjustment of a dataset with about 4500 images and 9 million image points can be done in only 15 minutes while achieving sub-pixel accuracy. [full text] [link]
-
Zhongze Zhao, (2016) Satellite Platform Jitter Detection and Image Geometric Quality Compensation Based on High-frequency Angular Displacement Data. In: Acta Optica Sinica, Vol 36, No.10: 503-511.

基于植被指数限制分水岭算法的机载激光点云建筑物提取
Abstract: Building extraction plays an important role in building reconstruction and urban management. In this study, a normalized difference vegetation index (NDVI) constrained watershed segmentation algorithm is utilized to segment airborne LiDAR data, and certain criteria are used to discriminate building regions as follows. First, grid data is attained by the interpolation of LiDAR point clouds. Then, the NDVI constrained watershed segmentation algorithm is applied to segmenting the digital surface model data, which is generated from LiDAR. Further, NDVI is introduced in the flooding process of the watershed algorithm to separate the vegetation from the buildings. Finally, the building regions are identified through some of the criteria (elevation difference, size, and NDVI) according to the adjacency relationship of each region. The benchmark data of the International Society for Photogrammetry and Remote Sensing for Vaihingen are used to evaluate the building detection results. The average completeness, correctness, and quality are respectively 89.2%, 94.3%, and 84.7% at the pixel level and 81.8%, 93.1%, and 76.9% respectively at the object level. Moreover, for an object with area larger than 50 m2, the average completeness, correctness, and quality are 99.1%, 100%, and 99.1%, respectively. [full text] [link]
-
Lei Yu, , Mingwei Sun, Xinyu Zhu. (2016) Fusion of Cloudy Optical Satellite Imagery by Cloud Detection and High Pass Filtering. In: Geomatics and Information Science of Wuhan University, Vol.41 No.9: 1160-1167.

联合云检测与高通滤波的含云影像融合方法
Abstract: Noise from clouds is a common problem in optical satellite image processing. The high pass filter (HPF) fusion method is analyzed as a way to estimate the influence of cloud noise during image fusion. An approach combining cloud detection with HPF is introduced that refines the results of image fusion containing clouds. A, NIR/R-OTSU cloud detection approach is employed for real-time cloud detection, thus areas covered by clouds can be identified. A local optimization strategy is adopted in image fusion with HPF in cloudless blocks to get the fused image. Merged multispectral and panchromatic iZY-3 satellite image results show that the algorithm discussed in this paper performs better than HPF, IHS transform and Pansharp methods for merging images with clouds. [full text] [link]
-
Wenqing Feng, . (2016) Object-oriented Change Detection for Remote Sensing Images Based on Fuzzy Comprehensive Evaluation. In: Geomatics and Information Science of Wuhan University, Vol.41 No.9: 875-881.

利用模糊综合评判进行面向对象的遥感影像变化检测
Abstract: In the process of object-oriented change detection, the accuracy of the final result is directly related to the change threshold. Aiming at this problem, this paper presents a novel object-oriented change detection method using fuzzy comprehensive evaluation. Firstly, multi-scale segmentation is used to obtain initial objects; then, optional features for each object are chosen. Several criteria, such as objects change vector analysis, Chi-square transformation, the similarity of vector, and correlation coefficient, are treated as factors to get the “synthetic inter-layer logical values” of the fuzzy comprehensive evaluation model. The fuzzy comprehensive evaluation model is used to decide whether the target object has changed or not. Finally, the result of fuzzy comprehensive evaluation model is compared with the result of each single “inter-layer logical value” that using OTSU threshold segmentation. Based on this theory, experiments are done with SPOT5 multi-spectral remote sensing imagery. The experimental results illustrate that the model proposed can integrate the spectral and texture features and also overcome the defects caused by using single criteria. The fuzzy comprehensive evaluation model is proved to outperform other methods. [full text] [link]
-
Kai Tan, , Xin Tong, Yifei Kang. (2016) Automatic Cloud Detection for Chinese High Resolution Remote Sensing Satellite Imagery. In: Acta Geodaetica et Cartographica Sinica, Vol.45 No.5: 581-591.

国产高分辨率遥感卫星影像自动云检测
Abstract: Cloud detection is always an arduous problem in satellite imagery processing, especially the thin cloud which has the similar spectral characteristics as ground surfacehas long been the obstacle of the production of imagery product. In this paper, an automatic cloud detection method for Chinese high resolution remote sensing satellite imagery is introduced to overcome this problem.Firstly, the image is transformed from RGB to HIS color space by an improved color transformation model. The basic cloud coverage figure is obtained by using the information of intensity and saturation,followed by getting the modified figure with the information of near-infrared band and hue. Methods of histogram equalization and bilateral filtering, combined with conditioned Otsu thresholding are adopted to generate texture information. Then the cloud seed figureis obtained by using texture information to eliminate the existed errors in the modified figure. Finally, cloud covered areas are accurately extracted by integration of intensity information from the HIS color space and cloud seed figure. Compared to the detection results of other automatic and interactive methods, the overall accuracy of our proposed method achieves nearly 10% improvement, and it is capable of improving the efficiency of cloud detection significantly. [full text] [link]
-
Xiang Wang, , Shan Huang, Xiongwei Xie. (2016) Bandwidth Optimization of Normal Equation Matrix in Bundle Block Adjustment in Multi-baseline Rotational Photography. In: Acta Geodaetica et Cartographica Sinica, Vol.45 No.2: 170-177.

旋转多基线摄影光束法平差法方程矩阵带宽优化
Abstract: A new bandwidth optimization method of normal equation matrix in bundle block adjustment in multi-baseline rotational close range photography by image index re-sorting is proposed. The equivalent exposure station of each image is calculated by its object space coverage and the relationship with other adjacent images. Then, according to the coordinate relations between equivalent exposure stations, new logical indices of all images are computed, based on which, the optimized bandwidth value can be obtained. Experimental results show that the bandwidth determined by our proposed method is significantly better than its original value, thus the operational efficiency, as well as the memory consumption of multi-baseline rotational close range photography in real-data applications, is optimized to a certain extent. [full text] [link]
-
Xu Huang, , Jinglin Yang, Lianwei Ma, Xiaodong Xiong, Rongyong Huang. (2016) Closed-form Solution to Space Resection Based on Homography Matrix. In: Journal of Remote Sensing. Vol.20 No.3: 431-440.
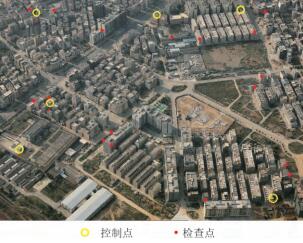
单应性几何下的后方交会直接解法
Abstract: Space resection is the method of acquiring the exterior orientation parameters of a camera based on three ground control points (GCPs) at least and the corresponding image points. The traditional least squares method of space resection needs good initial values of exterior orientation parameters. However, good initial values are difficult to obtain in the oblique photogrammetry condition. The objective of this study is to compute accurate exterior orientation parameters automatically to provide good initial values for the least squares method of space resection. Solving the space resection problem needs three GCPs and the corresponding image points at least. This study initially starts from three GCPs and then derives a direct solution model of space resection. The three GCPs must be coplanar and the corresponding image points must also be coplanar. Thus, the homography matrix can be used to describe the geometric relationship between a set of coplanar points and another set of coplanar points. This study transforms the collinearity equation into a homography matrix model and derives two constraints based on the orthogonality of the rotation matrix. When only three GCPs exist, the space resection problem can be transformed into a set of binary quadratic equations. The binary quadratic equations have four solutions at most. An additional GCP is necessary to decide the unique solution. When three ground control points exist, the unique solution can be directly computed based on a set of linear equations, which are derived from the homography matrix model. After computing the homography matrix solution, the exterior orientation parameters can be obtained using the relationship between the homography matrix and collinearity equation. Three experiments tested the effectiveness and reliability of the proposed method... [full text] [link]
-
Wenqing Feng, . (2015) Object-oriented Change Detection for Remote Sensing Images Based on Multi-scale Fusion. In: Acta Geodaetica et Cartographica Sinica, Vol.44 No.10: 1142-1151.

利用多尺度融合进行面向对象的遥感影像变化检测
Abstract: In the process of object-oriented change detection, the determination of the optimal segmentation scale is directly related to the subsequent change information extraction and analysis. Aiming at this problem, this paper presents a novel object-level change detection method based on multi-scale segmentation and fusion. First of all, the fine to coarse segmentation is used to obtain initial objects which have different sizes; then, according to the features of the objects, the method of change vector analysis is used to obtain the change detection results of various scales. In order to improve the accuracy of change detection, this paper introduces fuzzy fusion and two kinds of decision level fusion methods to get the results of multi-scale fusion. Based on these methods, experiments are done with SPOT5 multi-spectral remote sensing imagery. Compared with pixel-level change detection methods, the overall accuracy of our method has been improved by nearly 10%, and the experimental results prove the feasibility and effectiveness of the fusion strategies. [full text] [link]
-
Daifeng Peng, , Xiaodong Xiong. (2015) 3D Building Change Detection by Combining LiDAR Point Clouds and Aerial Imagery. In: Geomatics and Information Science of Wuhan University, Vol.40 No.4: 462-468.

结合LiDAR点云和航空影像的建筑物三维变化检测
Abstract: 针对传统建筑物变化检测方法没有考虑高程信息的缺点,提出了一种结合LiDAR点云数据和航空影像的建筑物三维变化检测方法,可同时提取建筑物高程变化信息和面积变化信息。首先将不同时期LiDAR点云分别生成数字表面模型(DSM);然后对不同时期的DSM进行差值、滤波和形态学操作得到DSM变化区,并根据共线方程将其反投影到航空影像中,再使用航空影像的光谱、纹理等信息排除树木等伪变化区的干扰;最后计算高程变化值和面积变化值。试验结果表明该方法能定量地提取高程和面积变化信息,提供更加全面准确的建筑物变化信息。 [full text] [link]
-
, Xu Huang, Xinhui Huang, Xiaodong Xiong. (2015) Relative Orientation based on Intersecting Lines. In: Geomatics and Information Science of Wuhan University, Vol.40 No.3: 303-307.

基于相交直线的相对定向方法
Abstract: In this paper, a new relative orientation algorithm based on intersecting lines is proposed. Relative orientation parameters are obtained with the intersection equations of the extracted corresponding intersecting lines.The algorithm needs no corresponding points and can be used to solve the problem of relative orientation lacking corresponding points.Experiments with aerial images, close-range images, and oblique images show that the proposed algorithm can get robust results. Relative orientation results are more accurate and robust when combining the proposed algorithm and the traditional relative orientation method using corresponding points. [full text] [link]
-
, Bo Wang, Qi Chen, Zheng Ji. (2014) Automatic Extraction Algorithm of Mark Centers in Close-range Photogrammetry. In: Journal of Tongji University (Natural Science), Vol.42 No.8: 1261-1266.

近景摄影测量标志中心的自动提取算法
Abstract: An automatic algorithm was proposed for extracting center of irregular shape mark in the close range photogrammetry. Combined with close range photogrammetry engineering practice and based on photogrammetry control information, the edge of man made mark was detected by using adaptive canny operator, then, reconstructed via automatic clustering. A case study of the Meridian Gate of the Forbidden City in Beijing and Wuhan University Campus's Flag Station Building surveying projects proves that the method greatly reduces the workload of the mark measurement. [full text] [link]
-
Haiqing He, , Shengxiang Huang. (2014) Phase Correlation Supported Low Altitude Images Matching with Repeated Texture. In: Geomatics and Information Science of Wuhan University, Vol.39 No.10: 1204-1207.

相位相关法辅助的重复纹理区低空影像匹配
Abstract: Low altitude image matching with repeated texture may have a small amount of corresponding points or beunsuccessful because of ambiguous matching. To solve the problem aphase correlation method supportes low altitude aerial image matching with repeated texture is proposed. The method estimates the traversal range of corresponding points including translation rotation and scale space. The traversal range is estimated by a cross-power spectrum of the image Fourier transform and a complex conjugate of another image Fourier transform. Next Harris-Laplace scale space is estimated by the scale traversal range and corners detection.Then corresponding point matching is a chieved by a correlation coefficient and epipolar constraint. The experimental results show that the method maybe reliable and practical for low altitude images matching with a repeated textureand obtains enough and well-distributed corresponding points. [full text] [link]
-
, Jinxin Xiong, Lei Yu, Xiao Ling. (2014) Automatic Matching for Optical Imagery from Domestic Satellites Based on Rigorous Sensor Model. In: Geomatics and Information Science of Wuhan University, Vol.39 No.8: 897-900.
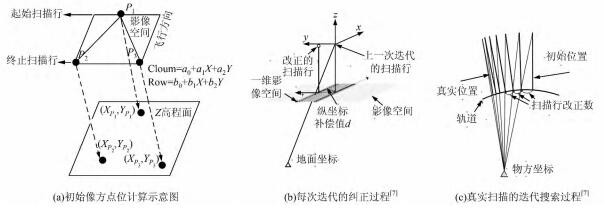
严密定位模型辅助的国产卫星影像匹配
Abstract: An image matching method based on a rigorous orientation model is presented that exploitsthe characteristics of optical imagery acquired from domestic satellites from different sensors.Firstly,this paper improves the method for scan line iterative search on the basis of the existing methods,andproposes the rapid correspondence prediction method.Next,with the help of the global SRTM(Shut-tle Radar Topography Mission)data,the approximate epipolar line is constructed by projection track-ing.The geometric and radiometric deformation in the matching window is eliminated by the correc-tion of local distortion.At last,in original level,the MPGC algorithm is adopted to refine the matc-hing results.This paper proposes a matching algorithm based on the geometric correction of the facetand the matching growth algorithm of a control network,which improves matching accuracy and thedistribution of the matching points.A test with imagery data from the TH1、ZY02Cand ZY3satellitesshowed that the proposed method can combine the characteristics of the optical imagery acquired fromdomestic satellites,and yield multi-source image matching from multi-source sensors.A well distribu-ted set of matching points can be obtained. [full text] [link]
-
, Bo Wang, Xu Huang, Yansong Duan. (2014) Eliminating of Image Matching Gross Errors Based on Local Vector Field. In: Acta Geodaetica et Cartographica Sinica, Vol.43 No.7: 717-723.

影像匹配粗差的局部矢量面元剔除方法
Abstract: This paper proposes a method that can be applied to eliminating gross errors in image matching. The whole process can be divided into three steps. Firstly,the systematic difference is removed. Then triangulated irregular network (TIN) of image matching points is constructed to get the partitioning local field. Based on the normal distribution of the image matching gross error,a vector descriptor is proposed in the statistics on the local field. Finally,a reasonable threshold is used in eliminating gross errors. The feasibility of the proposed method is verified based on the experiments of two groups of data. The results showed high processing speed and success rate of gross error elimination. This method also provided a new viewpoint to the research of photographic error processing and reliability theory. [full text] [link]
-
, Xiaodong Xiong, Mengqiu Wang, Yihui Lu. (2014) A New Aerial Image Matching Method Using Airborne LiDAR Point Cloud and POS Data. In: Acta Geodaetica et Cartographica Sinica, Vol.43 No.4: 380-388.

机载激光雷达点云与定位定姿系统数据辅助的航空影像自动匹配方法
Abstract: A novel aerial image tie point matching algorithm with the assistance of airborne LiDAR point cloud and POS data is proposed. Firstly,the conjugate point searching strategy used in traditional correlation coefficient matching is improved and a fast algorithm is presented. Secondly,an automatic camera boresight misalignment calibration method based on virtual ground control points is proposed,then the searching range of image matching is adaptively determined and applied to the image matching of the entire surveying area. Test results verified that the fast correlation coefficient matching algorithm proposed can reduce approximately 25% of the matching time without the loss of matching accuracy. The camera boresight misalignment calibration method can effectively increase the accuracy of exterior orientation elements of images calculated from POS data,and thus can significantly improve the predicted position of conjugate point for tie point matching. Our proposed image matching algorithm can achieve high matching accuracy with multi-scale,multi-view,cross-flight aerial images. [full text] [link]
-
, Bo Wang, Yansong Duan. (2013) An Algorithm of Gross Error Elimination in Image Matching for Large Rotation Angle Images. In: Geomatics and Information Science of Wuhan University, Vol.38 No.10: 1135-1138.

一种针对大倾角影像匹配粗差剔除的算法
Abstract: This paper has proposed an gross error elimination algorithm for image matching based on the imaging surface transformation. Image matching practice which embedded this algorithm in the coarse to fine the matching strategy showes that this algorithm can effective-ly control matching error and correct matching parameters. Experiments with large rotation angle images, such as low-altitude images and close-range images prove that the method can greatly reduce the gross errors in the matching results and ensure the quality and efficiency of image matching. [full text] [link]
-
Jinxin Xiong, , Maoteng Zheng, Yuanxin Ye. (2013) An SRTM Assisted Image Matching Algorithm for Long-strip Satellite Imagery. In: Journal of Remote Sensing, Vol.17 No.5: 1103-1117.
SRTM高程数据辅助的国产卫星长条带影像匹配
Abstract: Faced with the problem of unstable reliability in matching long-strip imagery of Chinese satellite, a matching algorithm is presented using the global Shuttle Radar Topography Mission (SRTM) data as elevation control. First, this algorithm employs the block partition mechanism, and introduces Local Binary Pattern/Contrast (LBP/C) operator to filter the interest points. Second, the global SRTM data is used to compute the true topographic relief within the image coverage. Based on the true topographic relief, the approximate epipolar line is constructed and the accuracy is analyzed. Third, on the pyramid level, two-dimensional correlation matching is executed to search for the optimal matches along the epipolar line. During the matching process, the geometry rectification method is applied to improve the accuracy of matching. Finally, on the original level, Multi-Photo Geometrically Constrained (MPGC) matching algorithm is adopted to refine the matching result, and Random Sample Consensus (RANSAC) is imbedded to eliminate mismatches. In order to ensure the distribution uniformity of matches, the region-growing algorithm is introduced. The main advantage of the proposed algorithm is that it can realize the automatic matching for long-strip imagery of different Ground Sample Distance (GSD), different visual angles in parallel environment. Through the comparison between the proposed method and the mainly existing methods, the results show that the matching accuracy is improved. [full text] [link]
-
Yijing Li, Xiangyun Hu, Jianqing Zhang, Wanshou Jiang, . (2012) Automatic Road Extraction In Complex Scenes Based on Information Fusion From LiDAR and Remote Sensing Imagery. In: Acta Geodaetica et Cartographica Sinica, Vol 41, No.6: 870-876.
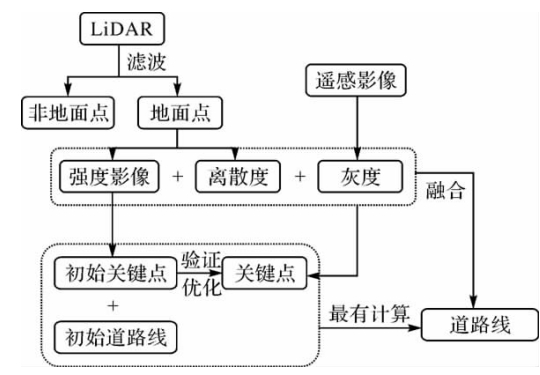
影像与LiDAR数据信息融合复杂场景下的道路自动提取
Abstract: Automatic road extraction from remote sensing images in urban area has been a very challenging task due to the complexity of the scene, especially in the occluded or shadowed areas. This paper proposes an integrated method to fuse LiDAR data and high resolution imagery for automatic extraction of road centrelines. Firstly the LiDAR point cloud is filtered to get the ground points whose intensity data is used to detect initial road centrelines and key points of the roads. A road model is then built on the intensity and dispersion of the ground points as well as spectral information obtained from the high resolution image. Based on the model, the dynamic programming algorithm is applied to find the optimal road centrelines linking the key points which are selected by evaluation. The experimental results indicate its effectiveness in automatic road extraction in urban and complex scenes. [full text] [link]
-
, Maoteng Zheng, Xinyi Wang, Xinhui Huang. (2012) Strip-based Bundle Adjustment of Mapping Satellite-1 Three-line Array Imagery. In: Journal of Remote Sensing, Vol.16 No.6: 84-89.

“天绘一号”卫星三线阵影像条带式区域网平差
Abstract: Space borne linear array sensors have been introduced into photogrammetry since twenty years ago. However, the traditional solution of frame photograph cannot deal with image data obtation by linear array sensors because the position and attitude observations of the spacecraft vary at each scanner line. Thus it is impossible to determinate the exterior orientation parameters of each scanner line. A proper approximation has to be applied to the spacecraft trajectory model to reduce the unknown factors in bundle adjustment. There are three models feasible to represent the satellite trajectory: Quadratic Polynomial Model (QPM), Systematic Error Compensation Model (SECM), and Orientation Image Model (OIM). Revealing the differences of the three sensor models and relationships between different control strategies and the fi nal accuracy of geo-referencing after bundle adjustment is the main purpose of this paper. To fully evaluate the accuracy that the space borne three-line scanner can achieve, experiments with LMP, SECM and OIM triangulation algorithms are performed with a 500 km length data sets of the Mapping Satellite-1 under the WGS-84 coordinate system. [full text] [link]
-
Zuxun Zhang, . (2012) Establishing Geographic Information Infrastructure with Chinese Remote Sensing Imagery. In: Journal of Geomatics, Vol.37 No.5: 7-9.
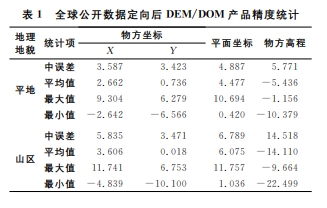
利用国产卫星影像构建我国地理空间信息
Abstract: Current status of earth observation technology based high resolution satellite is introduced. And the problems in data processing of domestic satellite imagery are discussed. Then key technologies in building the geospatial information of China are proposed. Furthermore, the achievements in fully automatic processing of ZY-3 satellite imagery are presented. [full text] [link]
-
, Xiaodong Xiong. (2012) Automatic Registration of Urban Aerial Imagery with Airborne LiDAR Data. In: Journal of Remote Sensing, Vol.16 No.3: 579-595.

城区机载LiDAR数据与航空影像的自动配准
Abstract: This paper presents a new algorithm for the automatic registration of airborne LiDAR data with aerial images using building corner features as registration primitives. First, three-dimensional building outlines are directly extracted from LiDAR points and building corner features which consist of two orthogonal straight lines are obtained by the regularization of threedimensional building outlines. Straight lines are also extracted from every aerial image. Second, the building corner features are projected onto aerial images and corresponding image corner features are determined using the similarity measures. Lastly, the exterior orientation parameters are refined by bundle adjustment using the corner points of corner features as control points. Iteration strategy is adopted to obtain optimal results. The main advantage of the proposed algorithm is that the three-dimensional building outlines are extracted directly from LiDAR points without transforming LiDAR points into range image or intensity image, and therefore there are no interpolation errors. The experimental results show that the proposed algorithm can obtain more accurate results in comparison with the registration method based on LiDAR intensity image. [full text] [link]
-
, Lei Wang, Yihui Lu. (2011) Optimization of the Rational Function Model of Satellite Imagery. In: Acta Geodaetica et Cartographica Sinica, Vol.40 No.6: 756-761.
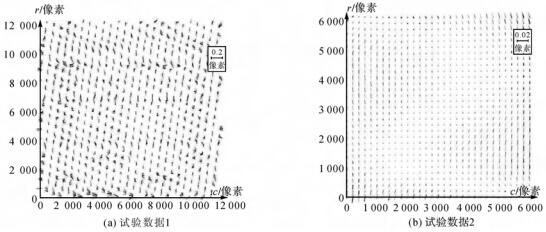
卫星遥感影像有理函数模型优化方法
Abstract: To solve the problems of over-parameterization and low geo-referencing accuracy of rational function model (RFM), a novel method of parameter optimization based on scatter matrix and elimination transformation and a new method of remnant systematic error compensation without ground control points are proposed. The proposed parameter optimization method can resolve the ill-posed problem of RFM by rejecting all excess parameters. The systematic error compensation method introduces a new correction model with Fourier coefficients. Experimental results indicate that the performance of the proposed method with less parameters is equal to that of the conventional model which all of the 78 parameters. Moreover, the ill-posed problem is effectively eliminated and thus the stabilities of estimated parameters are improved. The systematic error compensation scheme significantly eliminates the remnant systematic error of RFM and improves the geo-referencing accuracy. [full text] [link]
-
, Jinxin Xiong, Xiaodong Xiong, Jiwei Deng. (2011) Main Error Source of Vertical Parallax and Compensation Regression Model of POS Data. In: Acta Geodaetica et Cartographica Sinica, Vol.40 No.5: 604-609.
POS数据的上下视差误差源检测及误差补偿回归模型
Abstract: Main reason of the existence of systematic error of POS data is analyzed. Error equation of POS-based relative orientation is deduced. Regression model to compensate the systematic error of POS is established. Three sets of aerial images in different scales with POS data are used for experiment. Experimental results show that the systematic error of angular elements in POS data is the main error source which causes large vertical parallax. Compared with original POS data, the POS data corrected by the regression model can significantly decrease vertical parallax. Accuracy of geo-referencing is considerably improved without block adjustment. Satisfying result of experiment verifies the correctness and feasibility of the regression model. [full text] [link]
-
Chang Li, Zuxun Zhang, . (2011) Evaluating the Theoretical Accuracy of Error Distribution of Vanishing Points. In: Acta Geodaetica et Cartographica Sinica, Vol.40 No.3: 393-396.

灭点误差分布的理论精度评定
Abstract: The related researches of vanishing point have been focusing on its automatic detection and camera calibration for a long time, however there were few researches on its error distribution. Aiming at the closing error issue of lines intersection and the error distribution of vanishing points, we have made in-depth discussions. How to set initial weights for the adjustment solution of single image vanishing points is presented. Furthermore, we propose solving and estimating error distribution of vanishing points based on iteration method with variable weights, co-factor matrix and error ellipse theory. Not only do experimental results reveal the law of error distribution of vanishing points, but also pave the way for the theory and practicability of 3D reconstruction based on vanishing points. [full text] [link]
-
, Binghua Hu, Jianqing Zhang. (2011) Relative Orientation Based on Multiple Conjugate Features. In: Acta Geodaetica et Cartographica Sinica, Vol.40 No.2: 194-199.
基于多种同名特征的相对定向方法研究
Abstract: To resolve the current problems of relative orientation caused by lacking of obvious feature points in applications of industrial and architectural photogrammetry, a new method of relative orientation based on multiple types of conjugate features is proposed on the basis of the theory of generalized point photogrammetry. The models of independent and continuous relative orientation by conjugate lines and circular curves are addressed respectively. Experimental results show that the proposed approach is feasible in practice, and can get reliable relative orientation results even in the case of a few conjugate points. [full text] [link]
-
, Lei Wu, Liwen Lin, Jiaping Zhao. (2010) Automatic Water Body Extraction Based on LiDAR Data and Aerial Images. In: Geomatics and Information Science of Wuhan University, Vol.35 No.8: 936-940.

基于LiDAR数据和航空影像的水体自动提取
Abstract: A new approach of automatic water body extraction based on LiDAR data and aerial images is proposed.The LiDAR intensity image and aerial images are co-registrated by SIFT operator.Transformation parameters from LiDAR image to aerial image can be computed by the matched conjugated points.Black regions that have no reflection on height image generated by LiDAR data are automatically extracted.Geometric constraint conditions are used to remove non-water body areas.Edge information is used for region growing with the projected inilial position as initial value.Finally,mathematical morphology techniques are used to get more precise water body areas.Experimental results show that the proposed approach can achieve very good water body information. [full text] [link]
-
, Binghua Hu, Jianqing Zhang. (2011) Absolute Orientation of Large Rotation Angle Images. In: Geomatics and Information Science of Wuhan University, Vol.35 No.4: 427-431.
大旋角影像的绝对定向方法研究
Abstract: Absolute orientation is one of the fundamental issues in Photogrammetry and Remote Sensing. It is also an important topic in computer vision and three-dimensional reconstruction. To overcome the problem of large rotation angles between model coordinates of images and the corresponding world coordinates in close range applications, a new method of absolute orientation which is suitable for large oblique angle image is proposed. Singular value decomposition of rotation matrix is used to obtain accurate initial values of the angular elements. Least squares adjustment with gross error detection is also performed to achieve precise results of absolute orientation. Experimental results show that the proposed algorithm is effective and has well potential in various absolute orientation applications. [full text] [link]
-
, Lei Wu, Liwen Lin, Jiaping Zhao. (2010) Condition Numbers for Evaluation of Ill-Posed Problems in Photogrammetry. In: Geomatics and Information Science of Wuhan University, Vol.35 No.3: 308-312.
摄影测量中病态问题的条件数指标分析
Abstract: We discuss the principle of condition numbers that used for evaluating the extent of ill-posed problem of normal matrix.There is a contradiction between the stability of solution and the condition number of resection in photogrammetry.We find that it is not suitable in all cases to evaluate the extent of ill-posed problem by condition numbers.Three types of possible risks for evaluation of ill-condition extent with condition numbers were addressed in detail.Removing of outliers and re-parameterization are the prerequisites for evaluation of ill-condition extent with condition numbers.There are two effects of re-parameterization for ill-posed problems.One is improving the problem of ill-condition caused by numerical computation,and the other is avoiding the risk of using norm to evaluate the extent of ill-condition.Results of simulated experiments show that the proposed approach is validate for improving the problem of ill-condition. [full text] [link]
-
, Jiwei Deng, Jinxin Xiong, Hongya Zhang. (2010) Aerial Photographic Route Optimization Based on DEM and Simulated Bundle Adjustment. In: Journal of Geomatics, Vol.35 No.5: 30-32.
基于DEM及模拟平差的航空摄影航线优化设计方法
Abstract: 采用了模拟数据解算及变基线敷设航线的方法,自动解算了地形、相机参数及飞行器参数最优重叠度,设计出最适合该测区的航线。... [full text]
-
, Wei Kong. (2009)
Pose Determination of Space Object with Single Image. In: Journal of Xi'an Jiaotong University, 43(9): 56-61.
利用单幅影像的空间目标姿态测定方法
Abstract: A new method for space object pose determination by single image with known exterior orientation parameters is proposed. Initial values of object pose under world coordinate system are acquired by space resection and coordinate transformation. Then , precise pose parameters are obtained by least squares adjustment wit h collinearity equations where t he exterior orientation pa2 rameters are known. The proposed approach avoids t he synchronization problem of determining object pose wit h two or more cameras. Bot h simulated and real data experiments verify t he cor2 rect ness and validity of t he proposed approach. The experimental results show t hat t he precision of pose determination is significantly influenced by focal length of camera and distance between object and camera , t hus the number of control points and focal lengt h ought to be f ully considered according to the precision requisition for application. [full text]
-
, Yazhou Ding. (2009) Approximate Epipolar Image Generation of Linear Array Satellite Stereos with Rational Polynomial Coefficients. In: Geomatics and Information Science of Wuhan University, 34(9): 1068-1071.

基于有理多项式系数的线阵卫星近似核线影像的生成
Abstract: The basic principle of projective locus method to calculate local approximate epipolar image of linear array satellite stereo is discussed.A Line segment fitting approach is proposed to improve the precision of epipolar image.A new object space longitude and latitude based approximate epipolar image re-sampling approach is put forward.The proposed approach has well potential in dense image matching for generating high precision digital elevation models.Both searching range and mismatch possibility can be decreased.The experimental results show that the projective locus method is qualified for calculating local epipolar lines.The precision of line segment fitting is superior to that of traditional line fitting method.There is no y-parallax on re-sampled epipolar image with the proposed approach,which is advantageous for dense image matching.The precision of reverse calculation from epipolar image coordinates to original image coordinates is better than 0.04 pixel,which verifies the correctness of the proposed re-sampling approach. [full text] [link]
-
. (2009) Geometric Processing of Low Altitude Remote Sensing Images Captured by Unmanned Airship. In: Geomatics and Information Science of Wuhan University, Vol.34 No.3: 284-288.

无人驾驶飞艇低空遥感影像的几何处理
Abstract: The composition and technical characteristics of low altitude remote sensing system based on unmanned airship are introduced. The unmanned airship automated flies along the predefined routes and captures image sequences under the controlment of autopilot system. Geometric processing of captured low altitude stereo images, such as image matching, relative orientation, bundle block adjustment, panorama and orthoimage generation, are addressed in detail. Experimental results show that the developed system is qualified for high overlap and high resolution stereo imagery acquisition, and has good potential in large scale mapping and precise three dimensional reconstruction areas. [full text] [link]
-
. (2008) Reconstruction of Circles and round rectangles by generalized point photogrammetry. In: Journal of Harbin Institute of Technology. Vol.40 No.1: 136-140.

基于广义点摄影测量的圆和圆角矩形三维重建
Abstract: The composition and technical characteristics of low altitude remote sensing system based on unmanned airship are introduced. The unmanned airship automated flies along the predefined routes and captures image sequences under the controlment of autopilot system. Geometric processing of captured low altitude stereo images, such as image matching, relative orientation, bundle block adjustment, panorama and orthoimage generation, are addressed in detail. Experimental results show that the developed system is qualified for high overlap and high resolution stereo imagery acquisition, and has good potential in large scale mapping and precise three dimensional reconstruction areas. [full text]
-
Youchuan Wan, Liangming Liu, . (2007) Development of Photogrammetry and Remote Sensing in China. In: Bulletin of Surveying and Mapping, No.1: 1-4.
我国摄影测量与遥感发展探讨
Abstract: 随着摄影测量发展到数字摄影测量阶段及多传感器、多分辨率、多光谱、多时段遥感与其他边缘学科的交叉渗透、相互融合,摄影测量与遥感已逐渐发展成为一门新型的地球空间信息科学。分析近年来我国摄影测量与遥感技术表现出的许多新的特点,分别从数字摄影测量、航空摄影自动定位技术、近景摄影测量、低空摄影测量、机载激光扫描、稀少或无地面控制的卫星影像测图及应用、SAR数据处理、多源空间数据挖掘、遥感图像处理的智能化实用系统等方面予以总结。 [full text]
-
, Yong Zhang. (2006) Direct Geo-referencing of SPOT 5 HRS Imagery Without (or with a Few) Ground Control Point. In: Geomatics and Information Science of Wuhan University, Vol.31 No.11: 941-944.
SPOT 5 HRS立体影像无(稀少)控制绝对定位技术研究
Abstract: The photographic principle of SPOT 5 HRS is discussed in detail.By a series of coordinate system transforming,the rigorous orbit model of direct geo-referencing without ground control point is established.Experimental results of three datasets show that there are systematic errors existed.Once a ground control point is introduced,the result is improved tremendously.Results of 580 km test dataset with one ground control point are still better than 20 m for the planar position and about 10m for the altitude.It shows that the orbit itself is very stable.The HRS imagery has promising potential for various applications. [full text] [link]
-
. (2005) Automatic Extraction of Tree Rows and Hedges by Data Integration. In: Geomatics and Information Science of Wuhan University, Vol.30 No.11: 970-974.

基于数据融合的行树与篱笆三维信息自动提取
Abstract: This paper mainly focuses on the integration of GIS data, DSM information and CIR stereo imagery to derive automatically tree rows and hedges in the open landscape. Different approaches, such as segmentation by CIE L*a*b, edge extraction, linking and grouping, and verifying with 3D information, are successfully integrated to extract the objects of interest. The extracted tree rows and hedges can be used to update the GIS database, to derive wind erosion risk fields for soil monitoring and preservation. [full text] [link]
-
, Yong Zhang. (2005) Analysis of Precision of Relative Orientation and Forward Intersection with High-overlap Images. In: Geomatics and Information Science of Wuhan University, Vol.30 No.2: 126-130.

大重叠度影像的相对定向与前方交会精度分析
Abstract: Image sequence acquired by digital cameras has the advantages of high-overlap and redundancy of observations, which makes it more and more popular in 3D reconstruction. Precision of relative orientation and forward intersection with high overlapping image sequence is analyzed. The higher the overlap is, the better the result of relative orientation is. The more images are used, and the bigger the intersection angle is, the higher the precision of forward intersection is. In practice, images with 80 % overlap are optimal for 3D reconstruction and other applications. [full text] [link]
-
, Zuxun Zhang, Jianqing Zhang. (2004) Three-Dimensional Reconstruction and Visual Inspection of Industrial Sheetmetal Parts with Image Sequence. In: Tsinghua Science and Technology, Vol.44, No.4: 534-537.

基于序列图像的工业钣金件三维重建与视觉检测
Abstract: 针对目前工业制造领域面临的难题,提出利用非量测数字摄像机进行工业钣金件高精度三维重建与视觉检测。采用二维直接线性变换分解摄像机参数初值并结合光束法平... [full text]
-
, Jingnan Liu, Zuxun Zhang, Jianqing Zhang. (2004) Imprecision Inspection of Sheetmetal Parts with Non-metric CCD Camera. In: Acta Geodaetica et Cartographica Sinica, Vol. 33, No.2: 132-137.

基于非量测CCD摄像机的钣金件误差检测
Abstract: A new approach of three2dimensional reconstruction and inspection of industrial sheetmetal parts with non2metric CCD camera is proposed. Principle of line segment least squares template matching to extract precise points and lines from imagery is discussed. Wire2frame model of the sheetmetal part can be accurately reconstructed with hybrid point2line photogrammetry. One2dimensional template matching and direct object space solution is used to reconstruct complex shapes such as circles and connected arcs and lines. Producing imprecision can be inspected automatically or interactively by the results of reconstruction. The proposed inspection technique has the advantages of low cost of hardware and can run automatically and fastly. Inspection results of several parts are very satisfying. [full text]
-
, Cheng Wang, Zuxun Zhang, Jianqing Zhang. (2004) Object Space-based Matching and Reconstruction of Circles. In: Chinese Journal of Mechanical Engineering, Vol. 40, No.2: 92-95.
基于物方直接解的圆匹配与重建
Abstract: 提出一种基于物方直接解的圆匹配与重建方法,建立了灰度影像与空间圆参数间的函数关系,根据已知的相片内外方位元素及空间圆参数的初值,利用直线段最小二乘模板匹配方法直接获取空间圆的参数。系统论述了基于物方直接解和直线段最小二乘模板匹配方法进行空间圆匹配与重建的数学模型。实际图像数据的试验结果表明,本算法具有较高的重建精度。 [full text] [link]
-
, Jianqing Zhang. (2003) Orientation of Remote Sensing Image Pairs from Different Orbits. In: Geomatics and Information Science of Wuhan University, Vol.28 No.5: 521-524.
异轨遥感立体像对外方位元素的求解算法
Abstract: This paper mainly focuses on the approach of obtaining camera orientation parameters of remote sensing image pairs from different orbits.The fundamental mathematical models of obtaining camera orientation parameters from collinearity equations and coplanar conditions are discussed in detail.To combine the two models,spatial resection model based on coplanar conditions is modified.Results of the combined model can be obtained with adjustment by observation equations.Algorithms of how to calculate the initial values of orientation parameters are also addressed.The proposed approach is tested with a stereo image pair and some results are given. [full text] [link]
-
, Zuxun Zhang, Jianqing Zhang. (2003) Dimensional Inspection of Industrial Parts with Image Sequence. In: Journal of Shanghai Jiaotong University, Vol.37 No.9: 1447-1451.

基于序列图像的工业零件尺寸检测技术
Abstract: 提出利用像面上的点、直线信息进行混合光束法平差,对工业零件进行高精度三维重建并检测其尺 寸误差.介绍了零件坐标系与物方坐标系之间的变换方法,讨论了直线摄影测量误差方程式的基本形式、基于距离的改化形式以及点线混合光束法平差的数学模型, 提出在适当选取直线观测值的权值时,可以按间接平差模型解算直线空间前方交会.所开发的工业零件视觉检测系统可全自动运行,取得了约0.1 mm的实验精度,为工业领域中广泛存在的以直线段为主要特征的工业零件如钣金件的自动化三维检测提供了一条有效途径. [full text]
-
, Zuxun Zhang. (2003) Camera Calibration using 2D-DLT and Bundle Adjustment. In: Geomatics and Information Science of Wuhan University, Vol.27 No.6: 566-571.

利用二维DLT及光束法平差进行数字摄像机标定
Abstract: A flexible camera calibration technique using 2D-DLT and bundle adjustment with planar scenes is proposed in this paper. The equation of principal vertical line under image coordinate system represented by 2D-DLT parameters is worked out using the correspondence between collinearity equations and 2D-DLT. Proof of ambiguities in camera parameter decomposition with 2D-DLT parameters is given. Initial value of principal point can be obtained with at least two equations of principal vertical lines. Proof of critical motion sequences(CMS) is also given in detail. The practical decomposition algorithm of extrinsic parameters using initial values of principal point, focal length and 2D-DLT parameters is discussed elaborately. Planar-scene camera calibration algorithm with bundle adjustment(using collinearity equations) is addressed. For the proposed technique, either the camera or the planar pattern can be moved freely, and the motion need not be known. Very good results have been obtained with both computer simulations and real data calibration. [full text] [link]
-
, Shaoquan Xu, Zemin Wang. (2001) Ambiguity Resolution Approach in Combined GPS/GLONASS Positioning. In: Geomatics and Information Science of Wuhan University, Vol.26 No.1: 58-63.
GPS/GLONASS组合定位中模糊度的处理
Abstract: A flexible camera calibration technique using 2D-DLT and bundle adjustment with planar scenes is proposed in this paper. The equation of principal vertical line under image coordinate system represented by 2D-DLT parameters is worked out using the correspondence between collinearity equations and 2D-DLT. Proof of ambiguities in camera parameter decomposition with 2D-DLT parameters is given. Initial value of principal point can be obtained with at least two equations of principal vertical lines. Proof of critical motion sequences(CMS) is also given in detail. The practical decomposition algorithm of extrinsic parameters using initial values of principal point, focal length and 2D-DLT parameters is discussed elaborately. Planar-scene camera calibration algorithm with bundle adjustment(using collinearity equations) is addressed. For the proposed technique, either the camera or the planar pattern can be moved freely, and the motion need not be known. Very good results have been obtained with both computer simulations and real data calibration. [full text] [link]
-
Yingbing Li, Shaoquan Xu, . (2001) The Application of Spectrum Analysis in GPS Auto-monitoring System. In: Geomatics and Information Science of Wuhan University, Vol.26 No.4: 343-348.
谱分析在GPS自动化监测系统中的应用研究
Abstract: Deformation monitoring system is the safeguard of dam.Space estate and time characteristic of dam are attained by deformation monitoring,which is used to investigate the stability,discover the problems,take some measures,study deformation mechanism,validate designing theory as well as set up proper prediction model and methods of the dam.The real-time effective data processing and analysis are important in dam deformation monitoring.Dynamic deformation is taken as placidity random course.Dam deformation as well as water level change of reservoir and temperature variation is taken as linear system in this paper.Fast Fourier Transform transfers those signals from time domain to frequency domain. The deformation data,including water level of reservoir,are taken from the database of Geheyan GPS auto-monitoring system from June 10,1998 to October 23,1999,in total 491 days.Temperature data only about 343 days which are between June 10,1998 and May 18,1999.Those data are prepared as 4 data each day by tri-spline function.A difference filter is used to remove long-term trend.The Power spectrum of dam deformation,water level and temperature are shown in Fig.5,Fig.6 and Fig.7.From the figures we know their main frequency are near 1 Hz(about 1 day).Day change of water level of reservoir and temperature is one of main reasons of day deformation of dam.Delivering function curve of deformation and water level is shown in Fig.8.Delivering function curve of deformation and temperature is shown in Fig.9.The signals energies both reach max value at 1.884 Hz.Power spectrum of velocity of dam deformation,water level of reservoir and temperature are shown in Fig.10,Fig.11 and Fig.12. A discussion is carried out at the end of this paper.In order to verify the performance of the result derived from spectrum analysis,cross correlation between deformation and water level as well as temperature is studied,and the result is presented in Fig.13 and Fig.14.However,there is only one temperature data available,but four temperature data are required for analysis.From the discussion we knew that it is a big problem in such a condition.At last two conclusions are drawn: 1) Day change of water level of reservoir and temperature is one of main reason of day deformation of dam.If there were only two reasons,the effect of water level is about 63% and temperature is about 37%. 2) Power spectrum of velocity of dam deformation,water level of reservoir and temperature shown very similar and their energy is mostly in high frequency. The velocity of water level of reservoir and temperature is one of the reasons of velocity of dam deformation.But there are still some further work to do in future.Long-term data and more data for each day should be studied further if possible. [full text] [link]
-
Yingbing Li, Shaoquan Xu, , Xiaohong Zhang. (2001) Spectral Analysis in Application of Automatic GPS based Dam Deformation Monitoring. In: Global Positioning System, Vol.26 No.1: 31-34.
谱分析在大坝外观GPS自动化监测中应用的研究
Abstract: Deformation monitoring system is the safeguard of dam.Space estate and time characteristic of dam are attained by deformation monitoring,which is used to investigate the stability,discover the problems,take some measures,study deformation mechanism,validate designing theory as well as set up proper prediction model and methods of the dam.The real-time effective data processing and analysis are important in dam deformation monitoring.Dynamic deformation is taken as placidity random course.Dam deformation as well as water level change of reservoir and temperature variation is taken as linear system in this paper.Fast Fourier Transform transfers those signals from time domain to frequency domain. The deformation data,including water level of reservoir,are taken from the database of Geheyan GPS auto-monitoring system from June 10,1998 to October 23,1999,in total 491 days.Temperature data only about 343 days which are between June 10,1998 and May 18,1999.Those data are prepared as 4 data each day by tri-spline function.A difference filter is used to remove long-term trend.The Power spectrum of dam deformation,water level and temperature are shown in Fig.5,Fig.6 and Fig.7.From the figures we know their main frequency are near 1 Hz(about 1 day).Day change of water level of reservoir and temperature is one of main reasons of day deformation of dam.Delivering function curve of deformation and water level is shown in Fig.8.Delivering function curve of deformation and temperature is shown in Fig.9.The signals energies both reach max value at 1.884 Hz.Power spectrum of velocity of dam deformation,water level of reservoir and temperature are shown in Fig.10,Fig.11 and Fig.12. A discussion is carried out at the end of this paper.In order to verify the performance of the result derived from spectrum analysis,cross correlation between deformation and water level as well as temperature is studied,and the result is presented in Fig.13 and Fig.14.However,there is only one temperature data available,but four temperature data are required for analysis.From the discussion we knew that it is a big problem in such a condition.At last two conclusions are drawn: 1) Day change of water level of reservoir and temperature is one of main reason of day deformation of dam.If there were only two reasons,the effect of water level is about 63% and temperature is about 37%. 2) Power spectrum of velocity of dam deformation,water level of reservoir and temperature shown very similar and their energy is mostly in high frequency. The velocity of water level of reservoir and temperature is one of the reasons of velocity of dam deformation.But there are still some further work to do in future.Long-term data and more data for each day should be studied further if possible. [full text]
-
Xiaohong Zhang, Zhenghang Li, . (2000) Effective Strategies to Improve the Precision of GPS Positioning in Mountain Areas. In: Dynamic Geodesy, Vol.16, No.2/3: 56-60.
-
, Shaoquan Xu. (2000) Research on GLONASS Broadcast Ephemeris Orbit Computation. In: GPS World of China, Vol.25, No.1: 58-62.
GLONASS广播历书轨道计算方法研究
Abstract: GLONASS与GPS观测数据联合处理引起了许多GPS用户的广泛关注。本文在简单介绍GLONASS系统的基础上,阐述了常用的广播历书轨道积分模型,并提出了一种新的积分方法。该方法具有编程简单,运算速度快等优点。 [full text]
-
Shaoquan Xu, . (2000) Precision Analysis of Combined GPS/GLONASS Positioning System. In: WTUSM Bulletin of Science and Technology, No.1: 22-25.
GPS/GLONASS组合定位系统的精度分析
Abstract: 介绍了GLONASS的组成及其运行状况,并与GPS进行了比较.为了检验GPS/GLONASS组合定位系统的灵敏度及其定位精度,在进行大量实验的基础上,对GPS、GLONASS、GPS/GLONASS三... [full text]
-
, Zemin Wang. (1999) Baseline Resolution Approach of GPS Data and Compatibility Check of Control Points. In: TianLu HangCe.
GPS的基线解算及已知点兼容性检验
Abstract: 全球定位系统(简称GPS)是美国国防部为满足军事部门对海上、陆地和空中设施进行高精度导航和定位要求而建立的,它具有全球性、全天候、连续的精密三维导航与定位能力。经过全世界科技工作者、仪器生产厂商的共同努力,GPS定位技术日趋成熟,而且具有自动化... [full text]
-
, Zemin Wang, Shaoquan Xu, Yingbing Li. (1999) Development of Multimedia Teaching Software "GPS Receivers and Applications". In: TianLu HangCe, No.4: 30-32.
多媒体教学软件“GPS仪器及软件使用”的研制
Abstract: 本文简述了“GPS仪器及软件使用”多媒体教学软件的设计思想和制作过程。该软件利用近几年才出现并迅速发展的计算机多媒体技术,图文并茂、直观形象地演示了GPS测量仪器... [full text]
-
, Shaoquan Xu, Yingbing Li. (1999) Research on the Applications of GPS/GLONASS Integrated Positioning System. In: Journal of Xi’an Research Institute of Surveying and Mapping, Vol.19, No.4: 22-27.
- All
- All
- English Conference
- Chinese Conference
-
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, Huimei He, Jian Wang, Jingdong Chen, Ming Yang, , Yansheng Li. (2024) SkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). At: Seattle, WA.
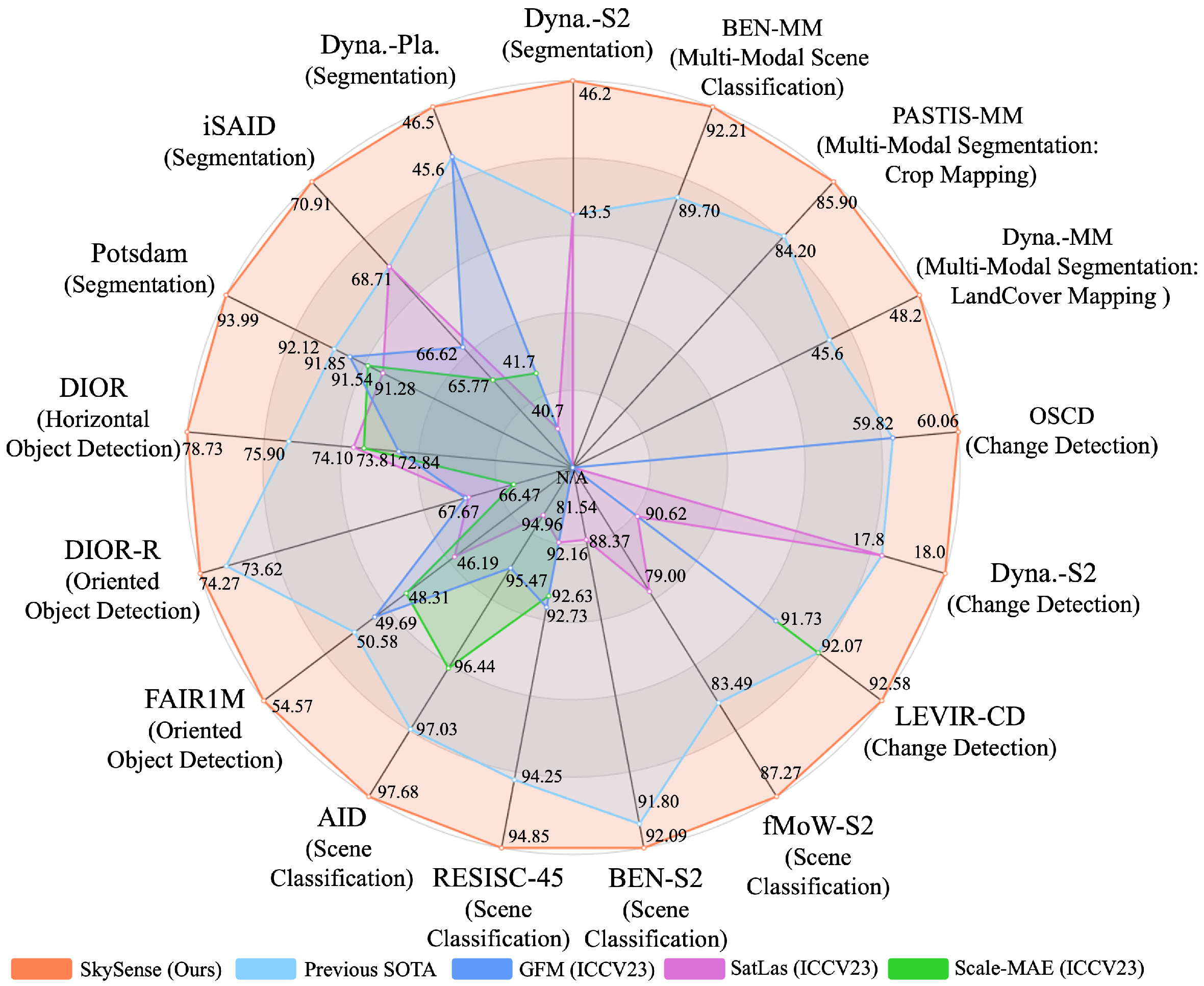
Abstract: Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primar-ily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pretrained on a curated multimodal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multimodal spatiotemporal encoder taking temporal sequences of opti-cal and Synthetic Aperture Radar (SAR) data as input. This encoder is pretrained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multimodal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thor-ough evaluation encompassing 16 datasets over 7 tasks, from single- to multimodal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pretrained weights to facilitate future research and Earth Observation applications. [full text] [link]
-
Xinyi Liu, Zihang Liu, , Zhi Gao, Yuhui Tan. (2024) UMeshSegNet: Semantic Segmentation of 3D Mesh Generated from UAV Photogrammetry. In: 2024 IEEE 18th International Conference on Control & Automation (ICCA). At: Reykjavik, Iceland.
Abstract: 3D mesh generated from UAV photogrammetry can depicts the urban scene realistically. Most of the studies on semantic segmentation of 3D mesh based on deep learning convert mesh data into point cloud or 2D image, resulting in original information lost and poor segmentation effect. To address the problem, a semantic segmentation convolutional neural network UMeshSegNet is designed in this paper based on MeshCNN, which directly processes the mesh data. The network combines geometric, elevation and texture features, and attention mechanism is also introduced to enhance the sensitivity to the feature. Experiments and analyses are conducted on public dataset SUM and our own Wuhan test data, and the experimental results indicate that UMeshSegNet can effectively segment mesh data with significantly higher semantic segmentation accuracy than previous deep learning methods. [full text] [link]
-
Qiong Wu, Zhi Zheng, Yi Wan, . (2023) M2-CDNet: A Multi-scale and Multi-level Network for Remote Sensing Image Change Detection. In: IGARSS 2023 - 2023 IEEE International Geoscience and Remote Sensing Symposium. At: Pasadena, California.
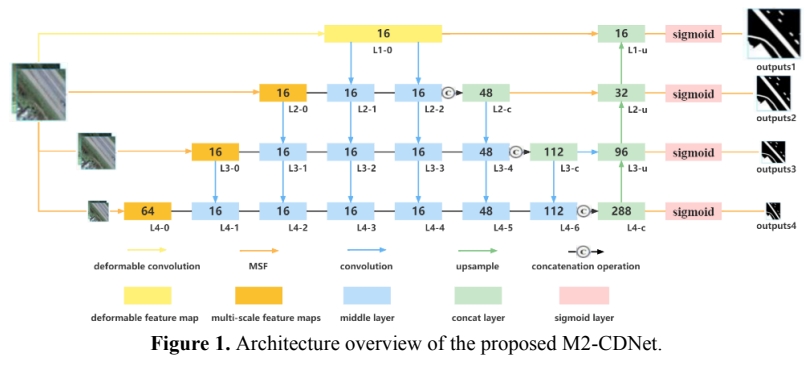
Abstract: Change detection plays a crucial role in environmental monitoring and earth observation tasks, leveraging the abundant data acquired by remote sensing platforms. While learning-based methods have shown promise in strictly registered datasets, their practical applicability in real-world scenarios remains challenging. This paper addresses the limitations of existing methods by proposing M2-CDNet, a novel approach that integrates the U-Net architecture with the multi-scale fusion (MSF) strategy, deformable convolutions, and multi-scale outputs. Experiments on the public and self-collected datasets demonstrate that M2-CDNet achieves superior accuracy-efficiency trade-offs compared to state-of-the-art methods. Moreover, M2-CDNet shows better robustness against image projection bias and registration errors. [full text] [link]
-
Haoyu Guo, Yi Wan, . (2023) Semantic Information-Aided Geometric Correction of High Resolution Satellite Images. In: IGARSS 2023 - 2023 IEEE International Geoscience and Remote Sensing Symposium. At: Pasadena, California.
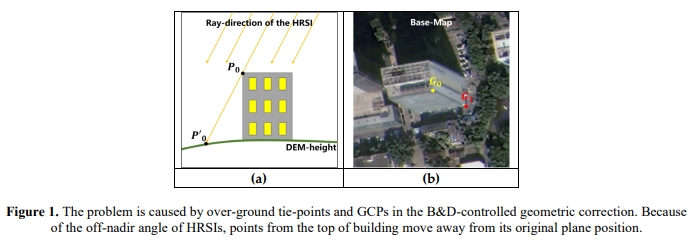
Abstract: With the rapid development of deep learning technology, the automatic classification and semantic segmentation of remote sensing imagery become more and more accurate. Meanwhile, with the improvement of the generalization, this technology is more and more widely used in the industry. This paper proposes a new framework of sematic-information-aided geometric correction of high-resolution satellite images (HRSIs) to achieve higher accuracy and automation. [full text] [link]
-
, Xiaoliang Meng, Yan Gong, Jiale Kang, Bing Lu. (2023) "Remote Sensing Plus" Training Mode of Innovation and Entrepreneurship Talent Nurturing Through College Student Competitions. In: ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Science, X-5/W1-2023, 83-86 At: Hong Kong, China.

Abstract: Innovation leads the development of technology and society, so the position of innovation and entrepreneurship training to nurture innovative talents is very important. The paper explores the 'trinity' innovation and entrepreneurship talent training model of 'promoting learning through competition, education through competition, and innovation through competition', focus on high level innovation and entrepreneurship competitions, enhance the stickiness among colleges, educators, students, and social enterprises, and enable students to participate in extracurricular academic activities that are highly consistent with the needs of the industrial market. To achieve this goal, School of Remote Sensing and Information Engineering of Wuhan University puts forward a 'remote sensing +' training model. Through the two-year practice of this model, 136 students from different schools and majors participated in the training of the 'Remote Sensing +' Innovation and Entrepreneurship Center in Wuhan University, and won three gold awards in the China's largest innovation and entrepreneurship competition. Due to the characteristics of cross-integration of remote sensing science and technology itself, it has played a supporting role in innovation education, integrating other multi-specialized knowledge, and providing more entrepreneurial and employment opportunities for students of related majors. [full text] [link]
-
Wei Dong, Wan Yi, , Xinyi Liu, Bin Zhang, Xiqi Wang. (2022) ELSR: Efficient Line Segment Reconstruction with Planes and Points Guidance. In:Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2022, 2022-June, 15786-15794. At: Orleans, LA.

Abstract: Three-dimensional (3D) line segments are helpful for scene reconstruction. Most of the existing 3D-line-segment reconstruction algorithms deal with two views or dozens of small-size images; while in practice there are usually hundreds or thousands of large-size images. In this paper, we propose an efficient line segment reconstruction method called ELSR11Available at https://skyearth.org/publication/project/ELSR. ELSR exploits scene planes that are commonly seen in city scenes and sparse 3D points that can be acquired easily from the structure-from-motion (SfM) approach. For two views, ELSR efficiently finds the local scene plane to guide the line matching and exploits sparse 3D points to accelerate and constrain the matching. To reconstruct a 3D line segment with multiple views, ELSR utilizes an efficient abstraction approach that selects representative 3D lines based on their spatial consistence. Our experiments demonstrated that ELSR had a higher accuracy and efficiency than the existing methods. Moreover, our results showed that ELSR could reconstruct 3D lines efficiently for large and complex scenes that contain thousands of large-size images. [full text] [link]
-
Yameng Wang, Bin Zhang, Yi Wan, . (2022) A Cascaded Cross-Modal Network for Semantic Segmentation from High-Resolution Aerial Imagery and RAW Lidar Data. In: International Geoscience and Remote Sensing Symposium (IGARSS), 2022, 2022-July, 3480-3483. At: Kuala Lumpur, Malaysia.
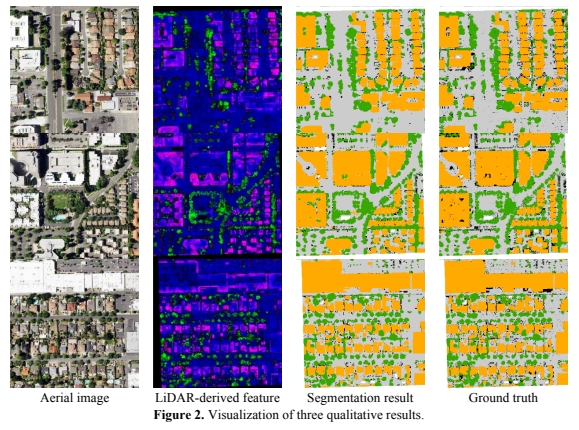
Abstract: As various sensors appear, extracting information from multimodal data becomes a prominent topic. Current multimodal approaches for image and LiDAR normally discard the point-to-point topology relationship of the latter to keep the dimension matched. To tackle this task, we propose a cascaded cross-modal network (CCMN) to extract the joint-features from high-resolution aerial imagery and LiDAR point directly, instead of their abridged derivatives. Firstly, point-wise features are extract from raw LiDAR data by a forepart 3D extractor. Subsequently, the LiDAR-derived features are executed spatial reference conversion to project and align to the imagery coordinate space. Finally, the cross-modal compounds containing the obtained feature maps and the corresponding images are placed into a U-shape structure to generate segmentation results. The experiment results indicate that our strategy surpasses the popular multimodal method by 6% on mIoU. [full text] [link]
-
Hong Ji, Zhi Gao, Xiaodong Liu, , Tiancan Mei. (2021) Small Object Detection Leveraging on Simultaneous Super-Resolution. In: Proceedings - International Conference on Pattern Recognition, 2020, 9054-9061, 9413058. At: Milan, Italy.
Abstract: Despite the impressive advancement achieved in object detection, the detection performance of small object is still far from satisfactory due to the lack of sufficient detailed appearance to distinguish it from similar objects. Inspired by the positive effects of super-resolution for object detection, we propose a framework that can be incorporated with detector networks to improve the performance of small object detection, in which the low-resolution image is super-resolved via generative adversarial network (GAN) in an unsupervised manner. In our method, the super-resolution network and the detection network are trained jointly. In particular, the detection loss is back-propagated into the super-resolution network during training to facilitate detection. Compared with available simultaneous super-resolution and detection methods which heavily rely on low-/high-resolution image pairs, our work breaks through such restriction via applying the CycleGAN strategy, achieving increased generality and applicability, while remaining an elegant structure. Extensive experiments on datasets from both computer vision and remote sensing communities demonstrate that our method obtains competitive performance on a wide range of complex scenarios. [full text] [link]
-
Xuhui Zhao, Zhi Gao, , Ben M. Chen. (2021) A Target Tracking and Positioning Framework for Video Satellites Based on SLAM. In: IEEE International Conference on Intelligent Robots and Systems, 2021, 1887-1894, 9341270. At: Las Vegas, NV.
Abstract: With the booming development in aerospace technology, the video satellite which observes the live phenomena on the ground by video shooting has gradually emerged as a new Earth observation method. And remote sensing comes into a "dynamic"era with the demand for new processing techniques, especially the near-real-time tracking and geo-positioning algorithm for ground moving targets. However, many researchers merely extract pixel-level trajectories in post-processed video products, resulting in fairly limited applications. We regard the video satellite as a robot flying in space and adopt the SLAM framework for the positioning of ground moving targets. The designed framework is based on the representative ORB-SLAM and we make improvements mainly in feature extraction, satellite pose estimation, moving target tracking and positioning. We coordinate a moving fishing boat with GPS-RTK (Real-time Kinematic) devices and a video satellite observing it simultaneously for verification and evaluation of our method. Experiments demonstrate that our framework provides reasonable geolocation of the moving target in satellite videos. Finally, some open problems and potential research directions are discussed. [full text] [link]
-
Xinyi Liu, , X Huang, Yining Wan. (2020) Terrain-Adaptive Ground Filtering of Airborne LIDAR Data Based on Saliency-Aware Thin Plate Spline. In:International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences - ISPRS Archives, 2020, 43(B2),279-285. At: Nice, France.
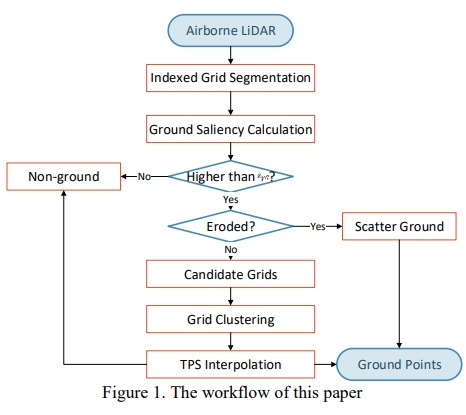
Abstract: Ground filtering separates the ground and non-ground points from point clouds, which is the essential process for DEM generation, semantic segmentation, model reconstruction and so forth. Considering the topologically complex terrain environments, the segmentation results are prone to be disturbed dealing with steep slopes, buildings, bridges, cliffs, etc. from Airborne LiDAR point clouds. In this paper, a saliency-aware Thin-Plate-Spline (SATPS) interpolation method is proposed including two steps: saliency division and adaptive regularized TPS interpolation with relative variance coefficient. Firstly, the point clouds are indexed in 2D grids and segments are clustered step probing toward 8-adjacent scanning directions. Then, the saliency of each grid is calculated according to the elevation variance of adjacent segments towards each scanning direction. Subsequently, grids of high ground saliency are considered as candidates for seed point selection and then clustered by region growing. The TPS surface is interpolated for each cluster loosely fitting to the seed points involving an adaptive relative variance coefficient which is according to ground saliency and elevation deviation. And finally, the ground points are extracted around the TPS surface. Experimental results indicate that the proposed SATPS algorithm achieves better Type 1 accuracy and total accuracy than the state-of-the-art algorithms in scenes with complex terrain structures, which is practical to generate DEM products. [full text] [link]
-
Bin Zhang, , Yansheng Li, Yi Wan, Fei Wen. (2020) Semi-Supervised Semantic Segmentation Network Via Learning Consistency for Remote Sensing Land-Cover Classification. In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2020, 5(2), 609-615. At: Nice, France.
Abstract: Current popular deep neural networks for semantic segmentation are almost supervised and highly rely on a large amount of labeled data. However, obtaining a large amount of pixel-level labeled data is time-consuming and laborious. In remote sensing area, this problem is more urgent. To alleviate this problem, we propose a novel semantic segmentation neural network (S4Net) based on semi-supervised learning by using unlabeled data. Our model can learn from unlabeled data by consistency regularization, which enforces the consistency of output under different random transforms and perturbations, such as random affine transform. Thus, the network is trained by the weighted sum of a supervised loss from labeled data and a consistency regularization loss from unlabeled data. The experiments we conducted on DeepGlobe land cover classification challenge dataset verified that our network can make use of unlabeled data to obtain precise results of semantic segmentation and achieve competitive performance when compared to other methods. [full text] [link]
-
Yi Wan, , Guangshuai Wang, Xinyi Liu. (2020) Accurate Registration of Aerial Images and Als-Pointcloud Via Automated Junction Matching and Planar Constraints. In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2020, 5(2), 79-86. At: Nice, France.

Abstract: Accurate geometric registration of images and pointclouds is the key step of many 3D-reconstruction or 3D-sensing tasks. In this paper, a novel L-junction based approach is proposed for semi-automatic accurate registration of aerial images and the airborne laser scanning (ALS) point-cloud in urban areas. The approach achieves accurate registration by associating the LiDAR points with the local planes extracted via L-junction detection and matching from multi-view aerial images. An L-junction is an intersection of two line-segments. Through the forward intersection of multi-view corresponding L-junctions, an accurate local junction-plane can be obtained. In the proposed approach, L-junction is manually collected from one view on the flat object-surfaces like walls, roads, and roofs and then automatically matched to other views with the aid of epipolar-geometry and vanishing-point constraints. Then, a plane-constrained bundle block adjustment of the image-orientation parameters is conducted, where the LiDAR points are treated as reference data. The proposed approach was tested with two datasets collected in Guangzhou city and Ningbo city of China. The experimental results showed that the proposed approach had better accuracy than the closest-point based method. The horizontal/vertical registration RMS of the proposed approach reached 4.21cm/5.72cm in Guangzhou dataset and 4.46cm/4.34cm in Ningbo dataset, which was much less than the average LiDAR-point distance (over 25cm in both datasets) and was very close to the image GSDs (3.2cm in Guangzhou and 4.8cm in Ningbo) and the a-priori ranging accuracy of the ALS equipment (about 3cm). [full text] [link]
-
, Sizhe Xiang, Yi Wan, Hui Cao, Yimin Luo, Zhi Zheng. (2020) DEM Extraction from Airborne Lidar Point Cloud in Thick-Forested Areas via Convolutional Neural Network. In: IGARSS 2020 - 2020 IEEE International Geoscience and Remote Sensing Symposium. At: Hawaii, USA.
Abstract: Digital Elevation Model (DEM), representing the height of the earth terrain, is one of the crucial geographic information products. One of the main data source of DEM is the airborne LiDAR point cloud with its non-ground-reflections filtered out. Point cloud filtering in thick-forested areas is difficult without enough ground control points when using conventional methods. In this paper, a supervised method is proposed to handle the problem of automatic DEM extraction with little ground control points. The design of the method is inspired by the successful application of the convolutional neural networks (CNN) in the image super resolution (SR) process. First, with the given LiDAR point cloud, the digital surface model (DSM) is resampled with regular grid. Then, by learning the spatial autocorrelation between the DSM and its corresponding DEM, a robust CNN model is established. Finally, the DEM in thick-forested areas can be generated from the DSM with the trained model. Experimental results at two different mountain sites in China validate the effectiveness of the proposed method of high-precision DEM generation. [full text] [link]
-
Fei Wen, , Bin Zhang. (2020) Global Context Aided Semantic Segmentation for Cloud Detection of Remote Sensing Images. In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2020, 5(2),583-589. At: Nice, France.

Abstract: Cloud detection is a vital preprocessing step for remote sensing image applications, which has been widely studied through Convolutional Neural Networks (CNNs) in recent years. However, the available CNN-based works only extract local/non-local features by stacked convolution and pooling layers, ignoring global contextual information of the input scenes. In this paper, a novel segmentation-based network is proposed for cloud detection of remote sensing images. We add a multi-class classification branch to a U-shaped semantic segmentation network. Through the encoder-decoder architecture, pixelwise classification of cloud, shadow and landcover can be obtained. Besides, the multi-class classification branch is built on top of the encoder module to extract global context by identifying what classes exist in the input scene. Linear representation encoded global contextual information is learned in the added branch, which is to be combined with featuremaps of the decoder and can help to selectively strengthen class-related features or weaken class-unrelated features at different scales. The whole network is trained and tested in an end-to-end fashion. Experiments on two Landsat-8 cloud detection datasets show better performance than other deep learning methods, which finally achieves 90.82% overall accuracy and 0.6992 mIoU on the SPARCS dataset, demonstrating the effectiveness of the proposed framework for cloud detection in remote sensing images. [full text] [link]
-
Chi Liu, , Yangjun Ou. (2020) Component Substitution Network for Pan-Sharpening via Semi-Supervised Learning. In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2020, 5(3), 255-262. At: Nice, France.
Abstract: Pan-sharpening refers to the technology which fuses a low resolution multispectral image (MS) and a high resolution panchromatic (PAN) image into a high resolution multispectral image (HRMS). In this paper, we propose a Component Substitution Network (CSN) for pan-sharpening. By adding a feature exchange module (FEM) to the widely used encoder-decoder framework, we design a network following the general procedure of the traditional component substitution (CS) approaches. Encoder of the network decomposes the input image into spectral feature and structure feature. The FEM regroups the extracted features and combines the spectral feature of the MS image with the structure feature of the PAN image. The decoder is an inverse process of the encoder and reconstructs the image. The MS and the PAN image share the same encoder and decoder, which makes the network robust to spectral and spatial variations. To reduce the burden of data preparation and improve the performance on full-resolution data, the network is trained through semi-supervised learning with image patches at both reduced-resolution and full-resolution. Experiments performed on GeoEye-1 data verifies that the proposed network has achieved state-of-The-Art performance, and the semi-supervised learning stategy further improves the performance on full-resolution data. [full text] [link]
-
Xiang Wang, , Xunwei Xie, Yansheng Li. (2018) Salient Object Detection via Double Sparse Representations under Visual Attention Guidance. In: IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium. At: Valencia, Spain.
Abstract: This paper introduces a novel method for salient object detection from the perspective of sparse representation under visual attention guidance. After pretreatment and regional analysis with eye fixation detection and multi scale segmentation, regions that are used to make up the foreground and background dictionaries are respectively selected by sorting the visual attraction level of all image regions. For saliency measurement, the reconstruction errors instead of common local and global contrasts are used as the saliency indicator, which is expected to improve the object integrity. In addition, the multi scale workflow is conductive to enhance the robustness for objects of different sizes. The proposed method was compared to six state-of-the-art saliency detection methods using three benchmark datasets, and it was confirmed to have more favorable performance in the detection of multiple objects as well as maintaining the integrity of the object area. [full text] [link]
-
Xianzhang Zhu, , Hui Cao, Kai Tan, Xiao Ling. (2018) A Novel Fine Registration Technique for Very High Resolution Remote Sensing Images. In: IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium. At: Valencia, Spain.

Abstract: This paper presents a novel registration noise (RN) estimation technique for fine registration of very high resolution (VHR) images. This is accomplished by using a two-step strategy to estimate and mitigate residual local misalignments in standardly registered VHR images. The first step takes advantages of the superpixel segmentation and frequency filtering to generate sparse superpixels as the basic objects for RN estimation. Then local rectification is employed for fine registration of the input image under the aid of RN information. More factors are taken into consideration in order to enhance the RN estimation performance. The proposed approach is designed in a fine registration strategy, which can effectively improve the pre-registration result. The experimental results obtained with real datasets confirm the effectiveness of the proposed method. [full text] [link]
-
Xunwei Xie, , Xiao Ling, Xiang Wang. (2018) A New Registration Algorithm for Multimodal Remote Sensing Images. In: IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium. At: Valencia, Spain.

Abstract: Automatic registration of remote sensing images is a challenging problem in the applications of remote sensing. The multimodal remote sensing images have significant nonlinear radiometric differences, which lead to the failure of area-based and feature-based registration methods. In this paper, to overcome significant nonlinear radiometric differences and large scale differences of multimodal remote sensing images, we propose a new registration algorithm, which can meet the need of initial registration of multimodal remote sensing images that conform to similarity transformation model. Our synthetic and real-data experimental results demonstrate the effectiveness and good performance of the proposed method in terms of visualization and registration accuracy. [full text] [link]
-
Kun Huang, , Rongjun Qin, Xu Huang. (2018) Block adjustment method for optical satellite on-orbit geometric calibration. In: ASPRS Annual Conference 2018 At: Denver, Colorado.
Abstract: On-orbit geometric calibration is a key technology to guarantee the interior geometric quality and direct positioning accuracy of high-resolution optical satellite images, in which block adjustment are used to solve the precise value of interior and exterior calibration parameters. In order to improve the accuracy, efficiency and robustness of geometric calibration of multi-chip TDICCD triangular mechanical staggered stitching optical sensor, this paper proposed an improved Conjugate Gradient Bundle Adjustment (CGBA) method. Taking the high-resolution optical camera of Chinese Mapping Satellite-1 for example, the design of TDICCD triangular mechanical staggered stitching is illustrated. The strict imaging geometric calibration model is constructed and optimized. Then, the CGBA method is deduced by calculus of variations. A preconditioning method based on improved incomplete Cholesky factorization is adopt to reduce the condition number of coefficient matrix, as well as to accelerate the iteration rate of CGBA. Experimental results demonstrate that the proposed geometric calibration method can effective improve the interior and exterior geometric quality of images, the improved CGBA can effectively conquer the ill-conditioned problem and improve the calculation efficiency while maintaining actual accuracy.
-
Xinyi Liu, , Qian Li. (2017) Automatic Pedestrian Crossing Detection and Impairment Analysis Based on Mobile Mapping System. In: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 4, p.251. At: Wuhan, China.
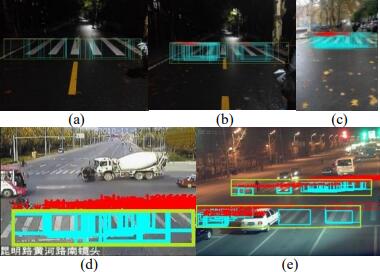
Abstract: Pedestrian crossing, as an important part of transportation infrastructures, serves to secure pedestrians' lives and possessions and keep traffic flow in order. As a prominent feature in the street scene, detection of pedestrian crossing contributes to 3D road marking reconstruction and diminishing the adverse impact of outliers in 3D street scene reconstruction. Since pedestrian crossing is subject to wearing and tearing from heavy traffic flow, it is of great imperative to monitor its status quo. On this account, an approach of automatic pedestrian crossing detection using images from vehicle-based Mobile Mapping System is put forward and its defilement and impairment are analyzed in this paper. Firstly, pedestrian crossing classifier is trained with low recall rate. Then initial detections are refined by utilizing projection filtering, contour information analysis, and monocular vision. Finally, a pedestrian crossing detection and analysis system with high recall rate, precision and robustness will be achieved. This system works for pedestrian crossing detection under different situations and light conditions. It can recognize defiled and impaired crossings automatically in the meanwhile, which facilitates monitoring and maintenance of traffic facilities, so as to reduce potential traffic safety problems and secure lives and property. [full text] [link]
-
Xu Huang, , Zhaoxi Yue. (2016) Image-guided Non-local Dense Matching with Three-steps Optimization. (Oral Presentation). In: International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, July 12-19, Volume III-3:67-74. At: Prague, Czech Republic.

Abstract: This paper introduces a new image-guided non-local dense matching algorithm that focuses on how to solve the following problems: 1) mitigating the influence of vertical parallax to the cost computation in stereo pairs; 2) guaranteeing the performance of dense matching in homogeneous intensity regions with significant disparity changes; 3) limiting the inaccurate cost propagated from depth discontinuity regions; 4) guaranteeing that the path between two pixels in the same region is connected; and 5) defining the cost propagation function between the reliable pixel and the unreliable pixel during disparity interpolation. This paper combines the Census histogram and an improved histogram of oriented gradient (HOG) feature together as the cost metrics, which are then aggregated based on a new iterative non-local matching method and the semi-global matching method. Finally, new rules of cost propagation between the valid pixels and the invalid pixels are defined to improve the disparity interpolation results. The results of our experiments using the benchmarks and the Toronto aerial images from the International Society for Photogrammetry and Remote Sensing (ISPRS) show that the proposed new method can outperform most of the current state-of-the-art stereo dense matching methods. [full text]
-
Yanfeng Zhang, , Yi Zhang, Xin Li. (2016) Automatic Extraction of DTM from Low Resolution DSM by Two-steps Semi-global Filtering (Oral Presentation). In: International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, July 12-19, Volume III-3: 249-255. At: Prague, Czech Republic.

Abstract: Automatically extracting DTM from DSM or LiDAR data by distinguishing non-ground points from ground points is an important issue. Many algorithms for this issue are developed, however, most of them are targeted at processing dense LiDAR data, and lack the ability of getting DTM from low resolution DSM. This is caused by the decrease of distinction on elevation variation between steep terrains and surface objects. In this paper, a method called two-steps semi-global filtering (TSGF) is proposed to extract DTM from low resolution DSM. Firstly, the DSM slope map is calculated and smoothed by SGF (semi-global filtering), which is then binarized and used as the mask of flat terrains. Secondly, the DSM is segmented with the restriction of the flat terrains mask. Lastly, each segment is filtered with semi-global algorithm in order to remove non-ground points, which will produce the final DTM. The first SGF is based on global distribution characteristic of large slope, which distinguishes steep terrains and flat terrains. The second SGF is used to filter non-ground points on DSM within flat terrain segments. Therefore, by two steps SGF non-ground points are removed robustly, while shape of steep terrains is kept. Experiments on DSM generated by ZY3 imagery with resolution of 10-30m demonstrate the effectiveness of the proposed method. [full text]
-
Daifeng Peng, . (2016) Building Change Detection by Combining LiDAR Data and Ortho Image. (Poster). In: International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, July 12-19, Volume XLI-B3:669-676. At: Prague, Czech Republic.
Abstract: The elevation information is not considered in the traditional building change detection methods. This paper presents an algorithm of combining LiDAR data and ortho image for 3D building change detection. The advantages of the proposed approach lie in the fusion of the height and spectral information by thematic segmentation. Furthermore, the proposed method also combines the advantages of pixel-level and object-level change detection by image differencing and object analysis. Firstly, two periods of LiDAR data are filtered and interpolated to generate their corresponding DSMs. Secondly, a binary image of the changed areas is generated by means of differencing and filtering the two DSMs, and then thematic layer is generated and projected onto the DSMs and DOMs. Thirdly, geometric and spectral features of the changed area are calculated, which is followed by decision tree classification for the purpose of extracting the changed building areas. Finally, the statistics of the elevation and area change information as well as the change type of the changed buildings are done for building change analysis. Experimental results show that the completeness and correctness of building change detection are close to 81.8% and 85.7% respectively when the building area is larger than 80 2 m , which are increased about 10% when compared with using ortho image alone. [full text]
-
, Yi Wan, Bo Wang, Yifei Kang, Jinxin Xiong. (2015) Automatic Processing of Chinese GF-1 Wide Field of View Images. In: 36th International Symposium on Remote Sensing of Environment, May 11-15, Volume XL-7/W3: 729-734. At: Berlin, Germany.

Abstract: The wide field of view (WFV) imaging instrument carried on the Chinese GF-1 satellite includes four cameras. Each camera has 200km swath-width that can acquire earth image at the same time and the observation can be repeated within only 4 days. This enables the applications of remote sensing imagery to advance from non-scheduled land-observation to periodically land-monitoring in the areas that use the images in such resolutions. This paper introduces an automatic data analysing and processing technique for the wide-swath images acquired by GF-1 satellite. Firstly, the images are validated by a self-adaptive Gaussian mixture model based cloud detection method to confirm whether they are qualified and suitable to be involved into the automatic processing workflow. Then the ground control points (GCPs) are quickly and automatically matched from the public geo-information products such as the rectified panchromatic images of Landsat-8. Before the geometric correction, the cloud detection results are also used to eliminate the invalid GCPs distributed in the cloud covered areas, which obviously reduces the ratio of blunders of GCPs. The geometric correction module not only rectifies the rational function models (RFMs), but also provides the self-calibration model and parameters for the non-linear distortion, and it is iteratively processed to detect blunders. The maximum geometric distortion in WFV image decreases from about 10-15 pixels to 1-2 pixels when compensated by self-calibration model. The processing experiments involve hundreds of WFV images of GF-1 satellite acquired from June to September 2013, which covers the whole mainland of China. All the processing work can be finished by one operator within 2 days on a desktop computer made up by a second-generation Intel Core-i7 CPU and a 4-solid-State-Disk array. The digital ortho maps (DOM) are automatically generated with 3 arc second Shuttle Radar Topography Mission (SRTM). The geometric accuracies of the generated DOM are 20m for camera-2 and 3, and 30m accuracy for camera-1 and 4. These products are now widely used in the fields of land and resource investigation, environment protection, and agricultural research. [full text]
-
, Xiaodong Xiong, Xiangyun Hu. (2013) Rigorous LiDAR Strip Adjustment with Triangulated Aerial Imagery. In: ISPRS, Laser Scanning 2013, Nov. 11-13, Volume II-5/W2: 361-366. At: , Antalya, Turkey.
Abstract: This paper proposes a POS aided LiDAR strip adjustment method. Firstly, aero-triangulation of the simultaneously obtained aerial images is conducted with a few photogrammetry-specific ground control points. Secondly, LiDAR intensity images are generated from the reflectance signals of laser foot points, and conjugate points are automatically matched between the LiDAR intensity image and the aero-triangulated aerial image. Control points used in LiDAR strip adjustment are derived from these conjugate points. Finally, LiDAR strip adjustment of real data is conducted with the POS aided LiDAR strip adjustment method proposed in this paper, and comparison experiment using three-dimensional similarity transformation method is also performed. The results indicate that the POS aided LiDAR strip adjustment method can significantly correct the planimetric and vertical errors of LiDAR strips. The planimetric correction accuracy is higher than average point distance while the vertical correction accuracy is comparable to that of the result of aero-triangulation. Moreover, the proposed method is obliviously superior to the traditional three-dimensional similarity transformation method. [full text]
-
Jinxin Xiong, . (2012) Combined Multi-View Matching Algorithm with Multiple Long-Strip Satellite Imagery from Different Orbits. In: ISPRS 2012 Congress, ISPRS, 38(B3): 87-92. At: Melbourne, Australia.

Abstract: Existing matching algorithms aim to match conjugate points among overlapping satellite scenes acquired from the same orbit and can generally achieve good matching performance. Unfortunately, no algorithm can avoid the difficulty of simultaneously processing the data sets of long-strip imagery acquired from different orbits. In this paper, the combined matching algorithm we propose introduces the LBP/C operator, which, when combined with existing feature detectors for the first time, can make possible the extraction of more stable interest points and candidates. At the same time, based on the typical characteristics of Chinese satellite imagery, we improved the filter method and achieved an effective combination of several image matching algorithms. A comparison among several kinds of matching transfer modes was presented; and to evaluate this algorithm, Chinese Mapping Satellite-I data are used as the reference data. [full text]
-
, Maoteng Zheng. (2012) Bundle Block Adjustment with Self-Calibration of Long Orbit CBERS-02B Imagery. In: ISPRS 2012 Congress, August 2012, ISPRS, 38(B1): 291-296. At: Melbourne, Australia.

Abstract: CBERS-02B was the first high resolution earth observation satellite in China, which adopted linear array push-broom sensor. The nadir ground resolution of the on board HR camera was 2.36 m. However, the accuracies of the on-board GPS receiver and star tracker were very limited due to the technical restrictions. The accuracy of direct geo-referencing by the on-board measurements of position and attitude parameters was about 1 kilometre, which restrained the wide applications of the CBERS-02B imagery in the surveying and mapping field. It is necessary to perform the bundle block adjustment to improve the accuracy of geo-referencing. A proper sensor model has to be adopted during the bundle block adjustment using strict physical sensor model with long orbit data, in order to solve the problem of too many unknown exterior orientation parameters (EOPs). Several sensor models have been discussed, such as quadratic polynomial model, systematic error compensation model, orientation image model, and piecewise polynomial model. The combination of the systematic error compensation model and the orientation image model will be used to deal with the CBERS-02B imagery in this paper. Furthermore, three TDI-CCD linear arrays were fixed on the focal plane of the HR camera. The middle CCD array was shifted against the left and the right one. The level 1A image used in this paper was mosaicked by the three sub-images collected by the left, the middle and the right CCD, respectively. But there were some displacements among the three sub-images in the mosaicked image and the three CCD arrays may not be rigorously parallel. The angular parameter a and the translation parameters x, y of each CCD refer to the theoretical position on the focal plane is used to model the interior distortions, so there are totally 9 interior distortion parameters, although some of them are not significant. The laboratory calibrated parameters of the image sensor are usually different from the true values after launch. So a self-calibration strategy should be applied in the bundle block adjustment. Plenty of automatically matched GCPs with precision of 10 meters in plane and 20 meters in height are used to perform the bundle adjustment. Both the systematic error compensation model and the orientation image model with the interior selfcalibration parameters are used in the bundle block adjustment to eliminate the systematic errors caused by the camera internal distortions and to improve the precision of geo-referencing. A best combination of interior orientation parameters (IOPs) is drawn from the adjustment results with different combinations of these IOPs. Besides, there may be some gross errors in the automatically matched GCPs. The gross errors among GCPs may lead to unusual variation of the exterior orientation elements by time. Methods of enlarging the intervals of orientation image and increasing the weights of the position and attitude observations are applied in the combined bundle block adjustment to remove the influence of gross errors of GCPs. The preliminary experimental results show that for longer than 1000 km orbit data, the average accuracy of self-calibrated bundle block adjustment combined with GPS and star tracker observations is 2 pixels better than that without self-calibration. The planar position accuracies in X and Y of check points are 8 m and 7 m respectively. [full text]
-
, Maoteng Zheng, Tao Ke. (2011) Triangulation of Spaceborne Three-Line Array Imagery with Different Sensor Models. In: ASPRS 2011 Annual Conference, May 2011. At: Milwaukee, USA.
Abstract: Spaceborne linear array sensors have been introduced into photogrammetry since more than twenty years ago. The traditional solution of frame photograph cannot deal with image data of linear array sensor anymore, because the position and attitude of the spacecraft vary at each scanner line. Thus the number of unknowns would be extremely large and it is impossible to determinate the exterior orientation parameters of each scanner line. A proper approximation has to be applied to model the spacecraft trajectory to reduce the unknowns in triangulation. There are three models feasible to represent the satellite trajectory: Quadratic Polynomial Model (QPM), Systematic Error Compensation Model (SECM), and Orientation Image Model (OIM). Revealing the differences of the three sensor models and relationships between different control strategies and the final accuracy of georeferencing after bundle adjustment is the main purpose of this paper. To fully evaluate the accuracy that spaceborne three-line scanner can achieve, experiments with LMP, SECM and OIM triangulation algorithms are performed with a 500km length data sets under WGS 84 coordinate system. [full text]
-
. (2008) Photogrammetric Processing of Low Altitude Image Sequences by Unmanned Airship. In: ISPRS 2008 Congress, July 2008. ISPRS, 37(B5): 751-758. At: Beijing, China.

Abstract: Low altitude aerial image sequences have the advantages of high overlap, multi viewing and very high ground resolution. These kinds of images can be used in various applications that need high precision or fine texture. This paper mainly focuses on the photogrammetric processing of low altitude image sequences acquired by unmanned airship, which automatically flies according to the predefined flight routes under the controlment of autopilot system. The overlap and relative rotation parameters between two adjacent images are estimated by matching two images as a whole and then precisely determined by pyramid based image matching and relative orientation. The matched image points and ground control points are then used for aerial triangulation with collinearity equations. The aerial triangulated high resolution images can be used to obtain precise spatial information products, such as Digital Surface Model (DSM), Digital Ortho Map (DOM) large scale Digital Linear Graphic (DLG) and three-dimensional (3D) city model. Experimental results show that the developed remote sensing system is qualified for high overlap and high resolution stereo imagery acquisition. Moreover, the proposed approaches are effective for photogrammetric processing of low altitude image sequences, and have well potentials in large scale topographic mapping and precise 3D reconstruction areas. [full text]
-
, Quanye Du. (2008) Semiautomatic Extraction of 3D Curves Based on Snakes and Generalized Point Photogrammetry from Aerial imagery. In: ISPRS 2008 Congress, July 2008. ISPRS, 37(B3): 731-734. At: Beijing, China.

Abstract: The Snakes or active contour models of feature extraction algorithm integrates both photometric and geometric constraints. It derives the feature of interest by minimizing the total energy of Snakes with an initial location of the feature. Linear features can be directly processed with either x or y collinearity equation under the model of generalized point photogrammetry. In this paper, a new approach of extracting 3D curves based on Snakes and generalized point photogrammetry is proposed. Firstly, curve feature is extracted based on parametric B-spline approximation and Snakes on a single image. The seed points of curve feature on other images are determined by matching corresponding points. Then the corresponding curves are extracted by Snakes. Finally, the 3D curve model can be achieved by generalized point photogrammetry. Experimental results show that the proposed approach is feasible for 3D curve extraction. [full text]
-
, Hongchao Bing. (2005) Automatic Extraction of Tree Rows and Hedges by Data Integration Techniques. In: Proceedings of SPIE, November 2005. 6042 I. At: Wuhan, China.

Abstract: Data integration is a very important strategy to obtain optimum solutions in geo-scientific analysis, 3D scene modelling and visualization. This paper mainly focuses on the integration of GIS data, stereo aerial imagery and DSM to derive automatically tree rows and hedges in the open landscape. The roads, field boundaries, rivers and railways from GIS database also represent potential search areas for extracting tree rows and hedges, which are often located parallel and near to them. Different approaches, such as image segmentation by CIE L*a*b, edge extraction, linking, line grouping, space intersection and 3D verifying with DSM, are combined together to extract the objects of interest. The extracted information of tree rows and hedges can be used in many applications, such as deriving of wind erosion risk fields for soil monitoring and protection. [full text]
-
. (2004) Extraction Of Wind Erosion Obstacles By Integrating GIS-Data And Stereo Images. In: ISPRS 2004 Congress, July 2004. ISPRS, 35(B3): 375-380. At: Istanbul, Turkey.

Abstract: Data integration is a very important strategy to obtain optimum solutions in geo-scientific analysis, 3D scene modelling and visualization. This paper mainly focuses on the integration of GIS-data, stereo aerial imagery and DSM to derive automatically wind erosion obstacles in the open landscape to enhance the Digital Soil Science Map of Lower Saxony in Germany. The extracted wind erosion obstacles can be used to derive wind erosion risk fields for soil monitoring and preservation. GIS-data is used as prior information for the object extraction. The GIS-objects roads, field boundaries, rivers and railways from GIS database can represent initial search areas for extracting wind erosion obstacles, which are often located parallel and near to them. Wind erosion obstacles are divided in the semantic model into hedges and tree rows, because of different available information from the GIS-data, although their extraction strategies are similar. Different approaches, such as segmentation by NDVI and CIE L*a*b, edge extraction, linking, grouping and verifying with 3D information, are combined to extract the objects of interest. The extracted wind erosion obstacles are integrated into a semantic model, described by their 3D appearance in geometry, together with 2D elongated shadow regions in a known direction according to 3D information and sunshine. [full text]
-
. (2004) Measurement of Industrial Sheetmetal Parts with CAD-designed Data and Non-metric Image Sequence. In: ISPRS 2004 Congress, July 2004. ISPRS, 35(B5): 640-645. At: Istanbul, Turkey.

Abstract: A novel approach for three-dimensional reconstruction and measurement of industrial parts with CAD-designed data and non-metric image sequence is proposed. The purpose of our approach is to automatically reconstruct and thus measure the producing imprecision or deformations of industrial parts mainly composed of line segments and circles with information extracted from imagery. Non-metric image sequence and CAD-designed data are used as sources of information. Principles of 2D and 1D least squares template matching to extract precise lines and points are presented. Hybrid point-line photogrammetry is adopted to get accurate wire frame model of industrial parts. Circles, arcs and lines connected to each other on the part are reconstructed with direct object space solution according to known camera parameters. The reconstructed CAD model can be used for visual measurement. Experimental results of several parts are very satisfying, which shows that the proposed approach has a promising potential in automatic 3D reconstruction and measurement of widely existed industrial parts mainly composed of lines, circles, connected arcs and lines. [full text]
-
, Zuxun Zhang, Jianqing Zhang. (2003) 3D Reconstruction of Industrial Sheetmetal Parts with Hybrid Point-line Photogrammetry. In: Third International Symposium on Multispectral Image Processing and Pattern Recognition, October 2003. 5286: 992-996. At: Beijing, China.
Abstract: An approach for three-dimensional reconstruction of industrial parts with non-metric image sequence and hybrid point-line photogrammetry is proposed. Non-metric image sequence and CAD-designed data are used as source of information. The strategy of our approach is to reconstruct the parts automatically with points and line segments extracted from imagery. Hybrid point-line photogrammetry is used to reconstruct sheetmetal parts accurately, and the reconstructed model can be used for visualization and inspection. The reconstruction system can run automatically and fastly. The output of hybrid point-line photogrammetry is the final 3D geometric model of the part. Results of real images of several parts are very satisfying, which shows a promising potential in automatic 3D reconstruction of widely existed industrial parts mainly composed of points and lines. [full text]
-
, Zuxun Zhang, Jianqing Zhang. (2003) Photogrammetric Reconstruction of Arcs and Lines Based on one Dimensional Point Template Matching. In: 6th Conference on Optical 3D Measurement Techniques, September 2003. pp. 315-321. At: Zurich, Switzerland.

Abstract: For lots of pipe-like and board-like industrial parts, the reconstruction of circles, arcs and lines is very important but hard to deal with in practice. A new approach to match and reconstruct circles, arcs and lines based on one-dimensional point template matching technique and immediate object space solution is presented. Model of one-dimensional point template matching is addressed. Circles and arcs can be reconstructed easily and accurately with this model. Lines are represented by small segments. The length of small segments is approximately equal to that of point window in circle and arc reconstruction. Arcs and lines, which are connected to each other, can be reconstructed by an uniform solution with additional constraints. Results of experiment are satisfying. [full text]
-
, Zuxun Zhang, Jianqing Zhang. (2003) Orientation of Remote Sensing Image Pairs. In: 2003 Annual Conference of American Society for Photogrammetry and Remote Sensing, May 2003. 0243. At: Anchorage, USA.
Abstract: A new approach to obtain orientation parameters of remote sensing image pairs taken from different orbits by CCD line scanner is proposed. Mathematical model of obtaining orientation parameters by collinearity equations and coplanarity conditions is discussed. The traditional collinearity equations can be used for control point and its image correspondence, but it is not the case for non-control image correspondences. The two camera positions and the image correspondences should be coplanar and thus can be used to resolve the orientation parameters. In the cases of only a few ground control points available, the two models should be combined to get reliable orientation parameters. To combine the two models, space resection model of coplanar condition is modified. Algorithms of how to calculate the initial values of orientation parameters are also addressed. The proposed approach is tested with stereo image pair and results are given. [full text]
-
, Zuxun Zhang, Jianqing Zhang. (2003) Multi-view 3D City Model Generation with Image Sequences. In: 6th AGILE conference on Geographic Information Science, March 2003. At: Lyon, France.

Abstract: Rapid texture mapping of buildings and other man-made objects is a key aspect for reconstruction of 3D city landscapes. An effective approach by the way of coarse-to-fine 3D city model generation based on digital photogrammetric theory is proposed. Three image sequences, two oblique photography to buildings' walls and one vertical photography to building's roof, acquired by digital video camera on a helicopter, coarse 2D vector data of buildings and LIDAR data are used as sources of information. Automatic aerial triangulation technique for high overlapping image sequences is used to give initial values of camera parameters of each image. The correspondence between the space edge of building and its line feature in image sequences is determined with a coarse-to-fine strategy. Hybrid point-line photogrammetric technique is used for accurate reconstruction of buildings. Reconstructed buildings with fine textures superimposed on DSM and orthoimage are visualized realistically. [full text] [full text]
-
, Zuxun Zhang, Jianqing Zhang. (2003) Camera Calibration Technique with Planar Scenes. In: Proceedings of SPIE, January 2003, 5011: 291-296. At: Santa Clara, USA.

Abstract: A flexible new camera calibration technique using 2D-DLT and bundle adjustment with planar scenes is proposed in this paper. The equation of principal line under image coordinate system represented with 2D-DLT parameters is educed using the correspondence between collinearity equations and 2D-DLT. A novel algorithm to obtain the initial value of principal point is put forward in this paper. The practical decomposition algorithm of exterior parameters using initial values of principal point, focal length and 2D-DLT parameters is discussed elaborately. Planar-scene camera calibration algorithm with bundle adjustment is addressed. For the proposed technique, either the camera or the planar pattern can be moved freely, and the motion need not be known. Very good results have been obtained with real data calibration. The calibration result can be used in some high precision applications, such as reverse engineering and industrial inspection. [full text]
-
, Jingnan Liu, Zemin Wang. (2002) Errors Analysising on Combined GPS/GLONASS Positioning. In: 2002 International Symposium on GPS/GNSS, November 2003. At: Wuhan, China.

Abstract: This paper focuses on the major errors and their reduction approaches of combined GPS/GLONASS positioning. To determine the difference in the time reference systems, different receiver clock offsets are introduced with respect to GPS and GLONASS system time. A more desirable method of introducing a fifth receiver independent unknown parameter, which can be canceled out when forming difference measurements, is discussed. The error of orbit integration and the error of transformation parameters are addressed in detail. Results of numerical integration are given. To deal with the influence of ionospheric delay, a method of forming dual-frequency ionospheric free carrier phase measurements is detailed. [full text]
-
, Maoteng Zheng, Jin Yu, et al. (2012) On-orbit Calibration and Accuracy Evaluation of Three-line Scanner of ZY-3 Satellite. In: The First Symposium of High Resolution Earth Observation, December 2012. At: Beijing, China.
-
, Bo Wang, Jin Yu, et al. (2012) Automatic Generation of Advanced Geographic Products with Chinese Remote Sensing Satellite. In: 18th Remote Sensing Congress of China, October 2012. At: Wuhan, China.

Abstract: Satellite remote sensing is an advanced technology with abundant applications and great social benefits. This paper illustrated the key technologies and workflow of the fully automatic data processing system to process the ZY-02C and ZY-3 satellite imagery. Finally, the accuracies of geo-referencing and fully automatically generated advanced products, such as high-resolution color-fused image, digital elevation model (DEM), and digital orthophoto map (DOM), were discussed. [full text]